Date-tiered compaction strategy is now available in ScyllaDB 1.3. In this post, we’ll explain why this new compaction strategy is needed, how it works, among other things.
Why was date-tiered compaction strategy developed?
In short words, the strategy was developed to improve performance for time-series use cases.
For those unfamiliar, time-series is basically about generating specific data at a constant rate. That’s very helpful for understanding the behavior of something over time. Nadav, a ScyllaDB engineer, listed some things that you need to know when modelling time-series data in ScyllaDB:
- Clustering key and write time are correlated.
- Data is added in time order. Only a few out-of-order writes, typically rearranged by just a few seconds.
- Data is only deleted through TTL or by deleting an entire partition.
- The rate at which data is written is nearly constant.
- A query on a time series is usually a range query on a given partition; The most common query is of the form “values from the last hour/day/week”.
In the ‘getting started’ section, you will learn how to model data for a simple time-series use case.
Now let’s understand how a new strategy would improve performance for time-series data. As you know, ScyllaDB flushes new data into immutable files called SSTables. These files accumulate over time, and compaction is required to save disk space and also reduce the number of them. A fewer number of SSTables results in better read performance.
The strategy employed by compaction plays an essential role to read performance. Why? When the database is asked to read a specific data, it needs to consult every SSTable and that may be a very expensive operation. If we can consult only a subset of SSTables instead, read performance is improved. The strategy dictates how data will be grouped over time. Leveled strategy, for example, tries to keep a partition key in as few SSTables as possible. Which strategy to use depends a lot on your use case. For time-series use case, we want to group together data that was inserted nearly the same time. That’s how the strategy originated. It was developed by Björn Hegerfors and first included in Cassandra 2.0.11.
Internals
In the section above, we talked about the reason that led to the development of the strategy. Now let’s take a quick look at what it does to achieve its goal.
Each SSTable keeps track of minimum and maximum timestamp (a.k.a. insertion time) for its data, so it’s possible to determine its timestamp range. Date-tiered strategy takes advantage of that and groups SSTables that have similar timestamp ranges into buckets, and when it’s done, it will choose for compaction the newest bucket that contains at least 2 entries. It’s important to mention that a bucket with older SSTables covers a bigger timestamp range, and therefore, compaction of such buckets will result in bigger files. The size of a SSTable will correlate to the age of its data.
By default, the strategy will compact first the bucket containing SSTables written in the last 60 seconds, then the bucket containing SSTables written in the last 240 seconds, and so on. The number of seconds grows exponentially. There’s a property that can be used to change the base seconds, i.e the 60 seconds in the example above, called base_time_seconds. And the property min_compaction_threshold, 4 by default, can be used to control the exponential growth of seconds. We’ll talk more about compaction strategy properties later on.
The optimal scenario for this strategy is to have SSTables with non-overlapping timestamp ranges. If size-tiered compaction strategy is used instead in time-series, old and new data will be mixed and read performance will suffer considerably. That’s because the user will ask for specific data using a time filter. After this new strategy, the database will efficiently select SSTables that overlaps with the time range specified in the select query.
Last but not least, the strategy makes an effort to get rid of fully expired SSTables as fast as it can. That’s important when an user defines a TTL (time-to-live) for every cell, and eventually many SSTables will become fully expired. Those ones are useless and not getting rid of them results in a waste of disk space.
Leveled vs Date Tiered analysis
Basic rule for understanding the graphs below: In the y-axis, you will find SSTables. Each horizontal bar corresponds to the timestamp range of a SSTable.
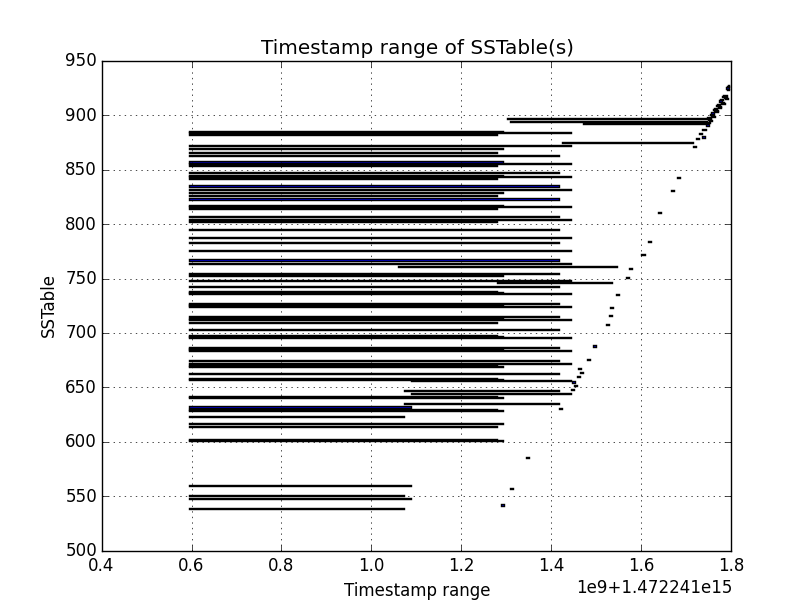
The graph above shows the resulting SSTables using Leveled compaction strategy. From a quick analysis, we can say that most of them have overlapping timestamp ranges. That’s bad for time-series data because the database will have to consider almost every SSTable.
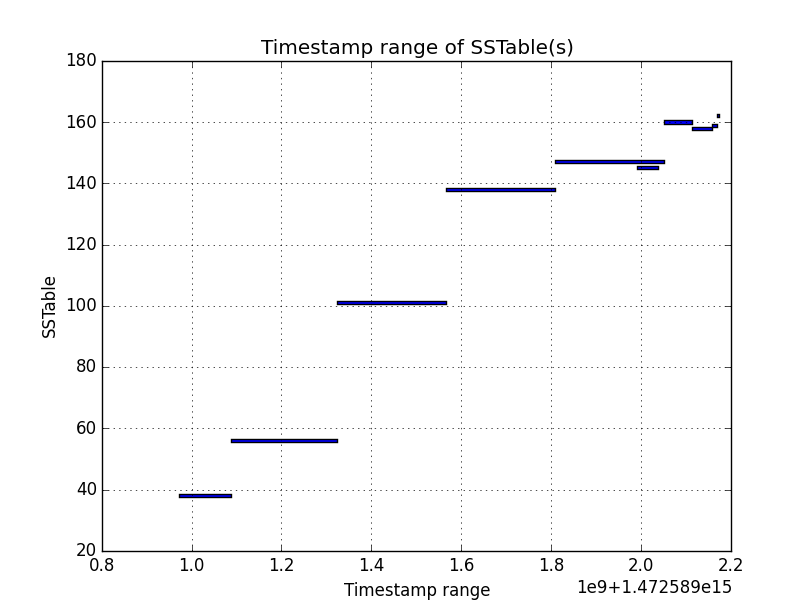
The graph above shows the resulting SSTables using Date Tiered compaction strategy. Things have changed drastically here. Now it’s easier to understand why the strategy is called Date Tiered. We can see that timestamp ranges of SSTables barely overlaps, so read performance in time-series use case will be very good because we will only have to look at a few SSTables.
Strategy pitfalls
Date-tiered compaction strategy isn’t perfect though. It was found that the strategy may struggle in the following scenarios:
- Memtable may hold data for too long, and when it’s flushed, the resulting SSTable will contain old and new data.
- Read Repair may result in old data being written into new SSTables, and the strategy will have to work harder to place it into its proper tier.
- Strategy relies heavily on clustering key being consistent with insertion time, or it may do poor decisions.
- Streaming may result in SSTables being created with old timestamps, and that will also result in poor decisions.
Knowing these problems, Jeff Jirsa worked on creation of another strategy that would remove the tiered nature of Date Tiered compaction strategy to address its limitations. This new strategy is called Time Window compaction strategy. ScyllaDB doesn’t support it yet, but we plan to get it supported as soon as possible.
Getting started
If you read all the previous sections, you know why date tiered strategy was created and how it works internally. Now it’s time to get hands dirty.
Let’s say that we want to track the number of users online for web pages with one minute interval. What we can do is to create a schema that will use the web page as the partition key, and use clustering key as the time of every single data point. The schema for this use case will be as follow:
CREATE TABLE users_online_tracker (
webpage_id text,
event_time timestamp,
users_online int,
PRIMARY KEY (webpage_id,event_time)
) WITH compaction = {'class': 'DateTieredCompactionStrategy', 'timestamp_resolution':'MICROSECONDS', 'base_time_seconds':'60', 'max_sstable_age_days':'365'};
Note that clustering key named as event_time uses the type timestamp, and it’s the key to modeling time-series data. Its value will actually correlate with insertion time. For example, if current time is ‘2016-08-30 07:01:00’, insertion to the table above will look like as follow:
INSERT INTO users_online_tracker(webpage_id,event_time,users_online) VALUES ('http://foo.bar','2016-08-30 07:01:00',10000);
Afterwards, the user may ask for events that happened in a time period using the following statement:
SELECT * FROM users_online_tracker WHERE webpage_id='http://foo.bar'
AND event_time >= '2016-08-30 07:01:00' AND event_time < '2016-08-30 07:04:00';
And that’s basically all you need to start working with time-series data. Now let’s quickly dive into some of the compaction options used in the creation of the table above:
- timestamp_resolution: MICROSECONDS by default. Don’t change it unless you’re using older clients, which may use a different timestamp resolution..
- base_time_seconds: 60 by default. This value is used to define a base time for timespans. If you want a lower number of SSTables covering a bigger timespan, it’s recommended to use 3600 seconds instead.
- max_sstable_age_days: 365 by default. SSTables older than max_sstable_age_day will no longer be considered by the strategy.
Summary
Date-tiered compaction strategy is now available in ScyllaDB. It’s very important for performance of time-series workloads. That’s not the end of the story though. Recently, it was found that date tiered doesn’t behave well under certain circumstances, and Time Window compaction strategy was introduced as a better alternative to it. We plan to get this new compaction strategy supported by ScyllaDB as soon as possible. Stay tuned!