



Log Structured Merge Tree FAQs
How Do Log Structured Merge Trees Work?
Log-structured merge-trees (LSM trees) handle both write and read operations efficiently with in-memory and disk-based storage structures. Here is an overview of log structured merge tree implementation:
Write operations. Incoming data is first stored in an in-memory structure called a memtable, memory tree, or write buffer. Often, the memtable allows for faster writes to memory compared to disk. The memtable frequently uses a red-black tree to maintain data in a sorted structure based on key-value pairs.
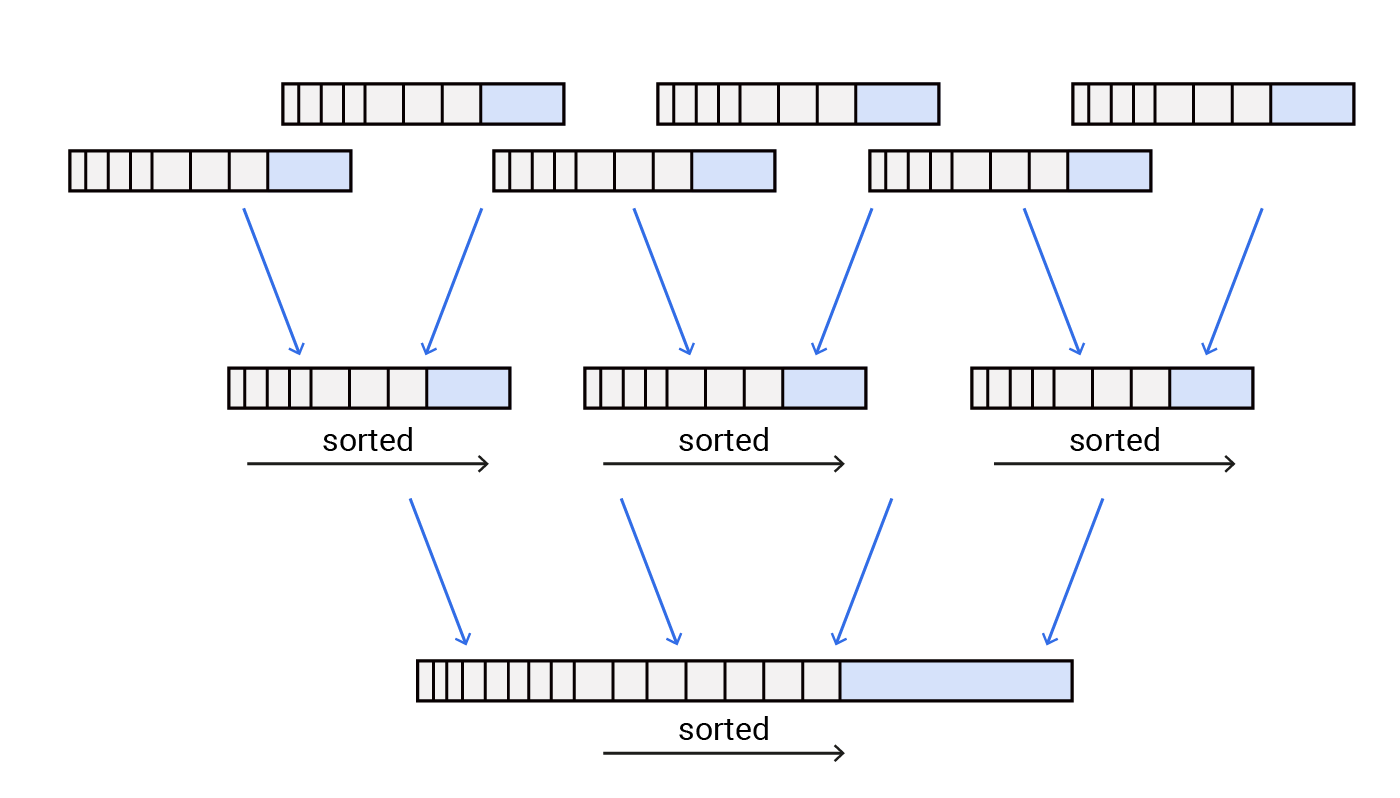
Level 0 sorted runs (SSTables). As the write buffer fills up, its contents are periodically flushed to disk as sorted string tables (SSTables) in Level 0. To compare the larger categories of log structured merge tree vs SSTtables, these smaller memory data structures contain contiguous key-value pairs and are involved with the compaction process. This involves sorting merged and compacted data across different levels to reduce fragmentation and eliminate overlapping key-value pairs.
SSTables are quick and efficient to read and write since they are append only and do not overwrite existing data to disk, and use binary search and index files to locate blocks and keys within blocks. And rather than store keys individually, they also gain speed by maintaining a selective or sparse index, keeping index entries for only a subset of the data rather than every individual record.
Read operations. A Bloom filter checks the memtable for the queried key and retrieves it directly if it locates it. If the key cannot be located, the LSM tree sequentially performs a multi-level search starting from the smallest and least sorted levels (Level 0) and moving upwards to higher, more sorted levels.
Log-structured merge-trees optimize workflows in several ways:
- In-memory buffering. Incoming writes are first stored in an in-memory structure, the memtable, to enable fast write operations and quick access.
- Batched writes. LSM trees accumulate writes in memory, batching them before flushing to disk to minimize the number of disk writes, improving efficiency.
- Reduced overwrites. By buffering writes in memory LSM trees reduce the number of random disk writes, enhancing performance.
- Compaction. Periodic compaction optimizes storage by merging and organizing data, reducing fragmentation and enhancing write performance.
- Multi-level search. Multi-level search and increasingly sorted data structures improves read efficiency. Compaction enhances read performance, reducing disk reads and improving data organization.
- Tuning. Tuning parameters allows users to optimize workflow performance based on specific use cases.
- Adaptability. Log-structured merge trees adapt well to varying workloads, efficiently handling write-heavy operations without sacrificing read efficiency.
- Scalability. LSM trees scale effectively due to their ability to manage data across multiple levels and optimize storage through compaction.

B-Trees vs Log-Structured Merge Trees
B-trees and log-structured merge trees (LSM trees) are both efficient data structures, but they have different characteristics and are optimized for different scenarios.
A B-tree is a balanced structure of nodes with multiple keys and child pointers. Each node contains a range of keys and pointers to child nodes, enabling efficient search, insertion, and deletion.
A B-tree sorts and stores data in a hierarchical structure optimized for both read and write operations, providing more balanced performance for sequential and random access. It is efficient for range queries due to the hierarchical nature, as traversing the tree can quickly identify a range of keys.
B-trees store data in a sorted order within tree nodes, so they excel in scenarios where data needs to be continually accessed and modified. This is why B-trees are often used in file systems and databases.
In contrast, LSM trees consist of multiple levels where data is organized, leveraging both in-memory and disk-based storage structures. They are optimized for write-heavy workloads and handle write operations quickly by buffering data in memory before flushing to disk in sorted runs efficiently.
LSM trees require periodic compaction to merge and organize data, reducing fragmentation and optimizing storage. They excel in scenarios where write throughput is crucial and can tolerate slightly higher read latencies.
In terms of B-trees vs log-structured merge trees, there are important differences in write vs read optimization. LSM trees prioritize write optimization, making them suitable for write-heavy workloads. In contrast, B-trees maintain a more balanced approach for reads and writes.
Storage efficiency is also somewhat different, in that log-structured merge trees require periodic compaction to optimize storage and minimize fragmentation, while B-trees maintain a relatively stable structure.
Common use cases for B-trees include databases and file systems where data is frequently read and written. Log-structured merge trees are often used in systems that handle heavy write loads, such as certain types of databases, distributed storage systems, and log-structured file systems.
Log Structured Merge Tree Database Comparison
There are many systems on the market that use LSM trees to optimize storage, writes, and reads while addressing different requirements of distributed systems, streaming platforms, and big data processing. Here are a few notable examples:
- Cassandra log structured merge tree emphasizes write optimization and is suitable for write-heavy workloads, time-series data, IoT, and logging.
- Kafka log structured merge tree excels in handling real-time streaming and event data with high throughput; it is best for real-time data pipelines, event streaming, and message queuing.
- Hbase log structured merge tree focuses on random read/write access to large datasets and is used in big data analytics and Hadoop-based systems requiring random access.
Cassandra. The Cassandra log structured merge tree implementation employs a combination of an in-memory memtable and disk-based SSTables to achieve a distributed NoSQL database designed for high scalability, fault-tolerance, and high-performance writes. Leveled Compaction Strategy (LCS) and Size-Tiered Compaction Strategy (STCS) are commonly used in Cassandra. This platform is suitable for scenarios requiring high write throughput, like time-series data, IoT applications, and logging, due to its distributed nature and emphasis on writes. ScyllaDB takes a similar approach, and offers addtional compaction options (more details on ScyllaDB’s approach below).
Kafka. The Kafka log structured merge tree implementation uses a variant called Log-Structured Storage to manage disk space and optimize for high-throughput writes. It is a distributed streaming platform designed for building real-time data pipelines and streaming applications ideal for building real-time data pipelines, event streaming, and message queuing due to its persistent, high-throughput, and low-latency characteristics.
HBase. The Hbase log structured merge tree implementation uses an LSM tree-based storage engine to manage data in HFiles (similar to SSTables) and in-memory Memstore and persistent HFiles on disk. This open-source, distributed, column-oriented database built atop the Hadoop Distributed File System (HDFS) is designed for random, real-time read/write access to large datasets. It is suited for applications requiring random access to large datasets, such as big data analytics.
Does ScyllaDB Offer Solutions for Log Structured Merge Tree?
Yes. ScyllaDB uses an LSM tree structure, which makes it well-suited for teams with write-heavy workloads. ScyllaDB optimizes write speed because: 1) writes are sequential, which is faster in terms of disk I/O and 2) writes are performed immediately, without first worrying about reading or updating existing values (like databases that rely on B-trees do). As a result, users can typically write a lot of data with very low latencies. At the same time, ScyllaDB can offer fast reads as a result of its specialized internal cache (in contrast to Cassandra, which relies on Linux caching that is inefficient for database implementations.)
ScyllaDB leverages RUM conjecture and controller theory, to deliver a state-of-art LSM-tree compaction for its users. Find out more about how ScyllaDB can identify the latest versions of data to shave down time on queries in this LSM Tree tech talk from ScyllaDB Engineering.