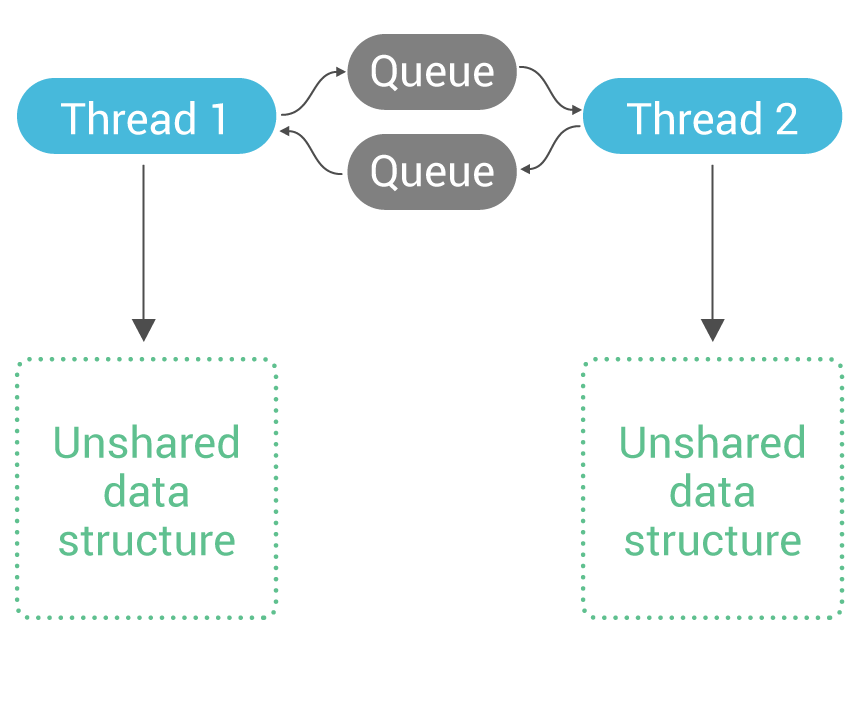
February 15, 2018 Adventures with Memory Barriers and Seastar on Linux Engineering, Featured, Tutorials, Seastar, ScyllaDB Open Source
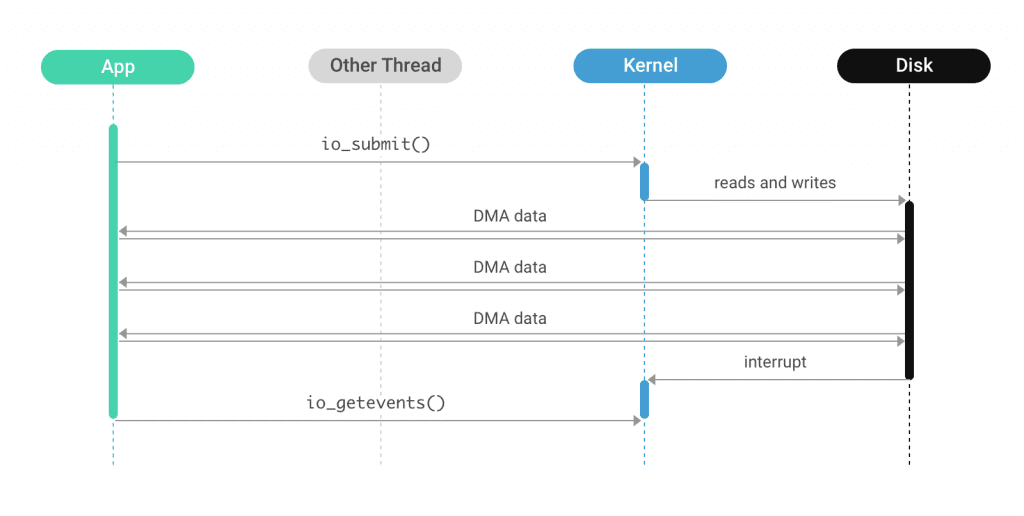
October 5, 2017 Different I/O Access Methods for Linux, What We Chose for ScyllaDB, and Why Engineering