





How ScyllaDB plays a critical role in handling Meesho’s millions of transactions – optimizing our catalog rankings and ensuring ultra-low-latency operations
With over a billion Indians set to shop online, Meesho is redefining e-commerce by making it accessible, affordable, and inclusive at an unprecedented scale. But scaling for Bharat isn’t just about growth—it’s about building a tech backbone that can handle massive traffic surges, dynamic pricing, real-time recommendations, and seamless user experiences.
Let me take you behind the scenes of Meesho’s journey to democratize e-commerce while operating at monster scale. We’ll cover how ScyllaDB plays a critical role in handling Meesho’s millions of transactions – optimizing our catalog rankings and ensuring ultra-low-latency operations.
Note: Adarsha Das from Meesho will be presenting a keynote at the upcoming Monster Scale Summit India/APAC. That talk is on BharatMLStack, an open-source, end-to-end machine learning infrastructure stack built at Meesho to support real-time and batch ML workloads at Bharat scale.
Join Monster Scale Summit India/APAC — it’s free and virtual
About Meesho
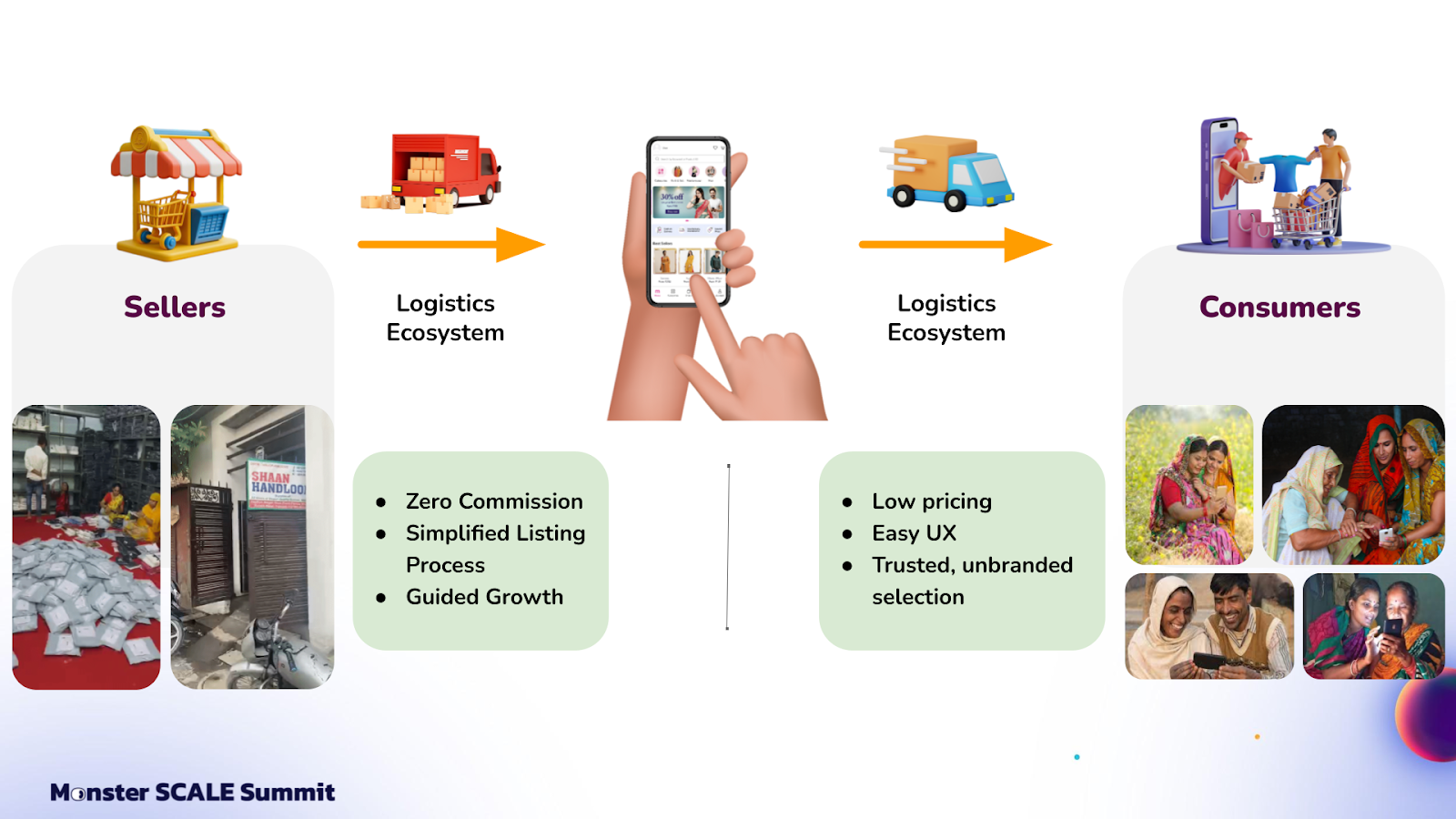
In case you’re not familiar with Meesho, we’re an Indian e-commerce platform. The company was founded in 2015 to connect small and medium enterprises in India. Meesho helps consumers from these areas access products from all over India, beyond their local markets.
Meesho focuses on bringing affordable product selections to Tier 2 cities and smaller markets. The company operates with a zero-commission model that reduces barriers for sellers. We function as an asset-light marketplace that connects sellers, logistics partners, and consumers. We make the listing process quite simple. Sellers just need to take a picture of the product, upload it, set the price, and start selling.
Why Personalization is Essential for Meesho
Meesho’s architecture aims to support people who are new to e-commerce. Tech-savvy users from Tier 1 cities likely know how to use search, tweak keywords, and find what they want. But someone from a Tier 2 city, new to e-commerce, needs discovery to be simpler. That’s why we invested in a lot of tech to build personalized experiences on the app.
Specifically, we invested significantly in AI and personalization technologies to create intuitive app experiences. We personalize all the way from the moment the app opens to order completion. For example, different users see different homepages and product selections based on their preferences and purchase history. We also personalize for sellers, helping them create product descriptions that make sense to their buyers.
Real-Time Feed-First Personalization
Meesho meets these needs with a fundamentally feed-first app. We create a tailored product feed, ranking products based on preferences and actions (searches, clicks, etc). To do this, we built a CTR (click-through rate) prediction model to decide what product tiles to show each user, and in what order. Two people logging in will see different selections based on their behavior.

Given all this, Meesho had to move from traditional recommendation systems to real-time, highly personalized experiences. Batch processing wasn’t sufficient; our personalization must respond instantly to recent user actions. That requires low-latency databases and systems at scale, with the ability to support millions of sellers and users on the app simultaneously.
Why ScyllaDB
We experimented with a few different databases and data stores: SQL, NoSQL, columnar, and non-columnar. Some worked at certain scales. But as we kept growing, we had to reinvent our storage strategy. Then we discovered ScyllaDB, which met our needs and proved itself at Meesho scale. More specifically, ScyllaDB provided…
Horizontal Scaling
Given the ever-increasing scale of Meesho – where user transactions kept increasing and users kept growing over years – horizontal scalability was very important to us.
Today, I might be running with X nodes. If that becomes 2X tomorrow, how do you scale in a live manner? Being a low-cost e-commerce platform, we are conscious about server spend, so we try to emulate traffic patterns by dynamically scaling up and down based on demand. For example, not all 24 hours have the same number of orders; there are peaks and lows. We want to provision for baseline load and auto-scale for demand without downtime, since the cost of downtime for a business like ours is very high. Downtime can result in user churn and loss of trust, so we prioritize reliability and availability above all.
Moreover, we expect that adding new nodes will linearly increase throughput. For example, if I run an X-node cluster and add nodes, I should get a proportionate throughput increase. This is critical as we scale up or down. We observed that in distributed systems with a primary-secondary configuration, the primary can become a bottleneck. So, we wanted a peer-to-peer architecture like ScyllaDB’s, where each node can service writes as well as reads. ScyllaDB gives us linear scalability.
Low-Level Optimizations for Efficiency
The database’s efficiency is also a factor for us. A major challenge we saw in JVM- or Java-based systems was garbage collection and related overheads. These impact performance, interrupt scaling, and limit hardware utilization. That’s why we prefer C++-based or other low-level language implementations, with minimal JVM or garbage collection issues, and minimal memory overhead. Most of our use cases require low-latency, real-time personalization, where every bit of memory is used for application logic and data, not overhead.
Smart Architecture and Fault Tolerance
Having a smart, fault-tolerant architecture was another consideration. Much of our user base is in Tier 3 and 4 cities, where network connectivity is sometimes flaky. We want to provide a Tier 1 user experience to Tier 4 users, so low latency is critical. We prioritize keeping latency within a few milliseconds.
One of ScyllaDB’s key features is token-aware routing. When a query comes, it goes directly to the node with relevant data – reducing network hops since each node acts as its own master. This is the kind of distributed architecture we were looking for, and the token-level routing helps with horizontal scalability.
Reliability and fault tolerance are also major requirements. When running on a public cloud, a big pain point is a particular zone going down. We’ve seen cloud regions and zones go down before. To minimize impact, we look for automatic data replication across zones and seamless failover in case of failures, so that user impact is minimal. Building trust with first-time e-commerce users is hard. If we lose it, getting them back is even harder. That’s why this capability is critical.
Operational Simplicity
Another thing we wanted is operational simplicity—having a system where adding or removing nodes is as simple as running a script or clicking a button. We like having an engine where we don’t need to tune everything ourselves.
Results So Far
We’ve been using ScyllaDB to power very low-latency systems at high throughput, for both reads and writes. We started with small workflows, scaled to platform workflows like ML platform and experimentation performance, and continue to scale. It’s been a good journey so far, and we’re looking forward to using it for more use cases.


