




Developers building on the DynamoDB API can run vector similarity search without the complexity of bolted-on “Zero ETL”
For users in the DynamoDB environment, implementing vector search has been overly complicated. Amazon’s “Zero ETL” forces a dual-service approach (managing both DynamoDB and OpenSearch) and requires using two separate APIs just for Vector Semantic Search queries.
ScyllaDB believes this is unnecessary complexity. We’re eliminating the heavy lifting by integrating vector search capabilities into Alternator, our DynamoDB-compatible API. This gives DynamoDB users high-performance similarity search within their familiar API, without the need for extra clusters or constant API context-switching.
Architectural Differences: Unified vs. Fragmented
Amazon’s approach to vector search exports data to S3 and then syncs it to OpenSearch via DynamoDB Streams. While “Zero ETL” sounds hands-off, you’re still responsible for the cost and complexity of a separate search cluster. The AWS cost is composed of DynamoDB, DynamoDB Streams, S3, OpenSearch, and the OSIS pipeline. Each of these elements’ pricing is complex on its own.
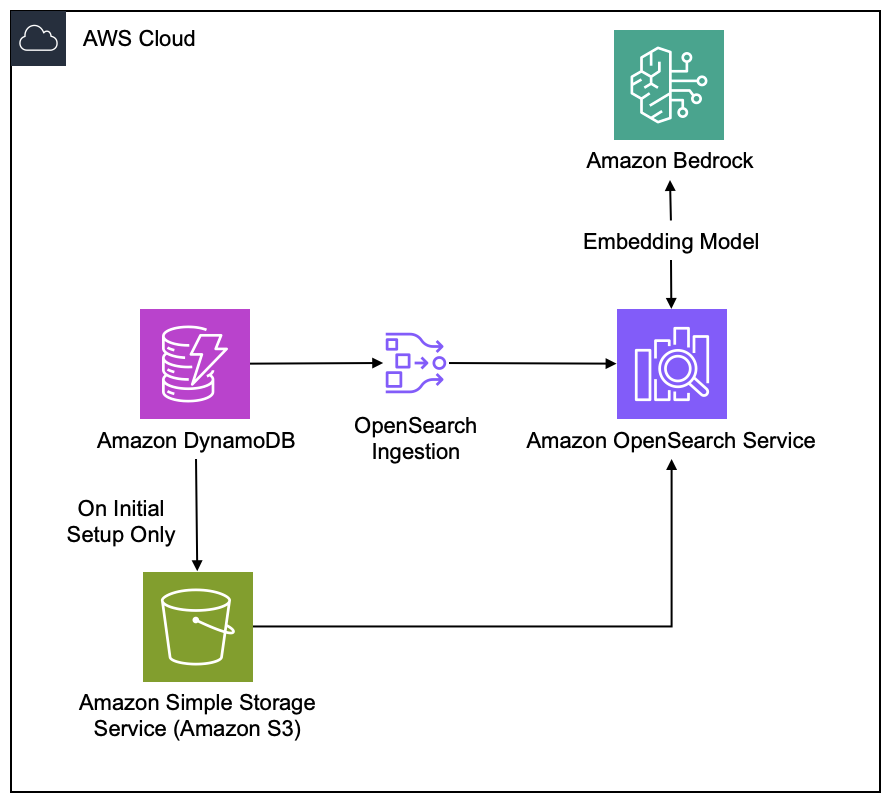
ScyllaDB Alternator simplifies this by integrating the vector store engine directly into the backend.
- Simple module: The ScyllaDB database hosts both the data and the vector index.
- Native API: You perform vector searches using DynamoDB Query operations.
Performance: 10 Million Vectors on a Budget
In our latest benchmark using a 10-million-vector dataset (768-dimensional Cohere embeddings), a modest five-node ScyllaDB cluster delivered over 12K QPS with single-digit millisecond latency.
Setup: 10M vectors; 768 dimensions; K: 10 (retrieve top K values); No Quantization
Results
- Recall: ~90%
- Throughput: 12,763 QPS
- P99 Latency: 7.8 ms
- Cost: $1,643 / Month for 1Y full up front
Estimating the AWS cost for this case is not trivial. The write-path includes DynamoDB (storage+ops), DynamoDB streams, S3 (storage, API), OpenSearch (data nodes, master nodes, EBS), and the OSIS pipeline. To read more on the pricing of Amazon Zero ETL, see Implementing search on Amazon DynamoDB data using zero-ETL integration with Amazon OpenSearch service.
Code Examples
Note: The exact JSON format might change in the next few months.
1. Enabling a Vector Index
You can enable vector indexing during CreateTable or via UpdateTable. Note the new VectorSecondaryIndexUpdates parameter.
// Adding a vector index to an existing table
{
"TableName": "ProductCatalog",
"AttributeDefinitions": [
{"AttributeName": "ProductEmbedding", "AttributeType": "V"}
],
"VectorSecondaryIndexUpdates": [
{
"Create": {
"IndexName": "VectorIdx",
"VectorAttribute": {
"AttributeName": "ProductEmbedding",
"Dimensions": 768
},
"IndexOptions": {
"SimilarityFunction": "COSINE",
"M": 32,
"ef_construction": 256
}
}
}
]
}Pro Tip: You will get the best results with ScyllaDB’s optimized “V” (Vector) type. Although you can use standard DynamoDB Lists, the “V” type will store data as a tight array of 32-bit floats – and that saves storage while boosting performance.
2. Performing a Vector Search
To search, use the Query operation with the ScyllaDB VectorSearch parameter.
{
"TableName": "ProductCatalog",
"IndexName": "VectorIdx",
"VectorSearch": {
"QueryVector": [0.12, 0.05, ..., 0.88],
"Oversampling": 1.5
},
"Limit": 10,
"ReturnVectorSearchSimilarity": "SIMILARITY"
}Example Use Cases
Semantic Product Search
Instead of relying on exact keyword matches, users can find products based on intent. For example, a search for “waterproof rugged hiking gear” can surface relevant items even if those exact words aren’t in the title.
RAG (Retrieval-Augmented Generation)
For knowledge bases, precision is non-negotiable. Using the High Recall configuration, ScyllaDB delivers 99.2% recall. That way, the LLM receives the most accurate context possible for generating responses.
Semantic Deduplication
At the Max Throughput end of the spectrum, ScyllaDB can quickly scan millions of incoming vectors to find near-duplicates. That prevents redundant data from cluttering your system – reducing costs and improving performance.
Conclusion
With ScyllaDB, DynamoDB users now have a “fast track” to AI-ready infrastructure. By unifying storage and vector search into a single API, you eliminate the operational tax of “Zero ETL” without sacrificing the sub-millisecond performance ScyllaDB is known for.



