Learn essential steps for boosting distributed system performance– explained with grocery store checkout analogies.
I visited a small local grocery store which happens to be in a touristy part of my neighborhood. If you’ve ever traveled abroad, then you’ve probably visited a store like that to stock up on bottled water without purchasing the overpriced hotel equivalent. This was one of these stores.
To my misfortune, my visit happened to coincide with a group of tourists arriving all at once to buy beverages and warm up (it’s winter!).
It just so happens that selecting beverages is often much faster than buying fruit – the reason for my visit. So after I had selected some delicious apples and grapes, I ended up waiting in line behind 10 people. And there was a single cashier to serve us all. The tourists didn’t seem to mind the wait (they were all chatting in line), but I sure wish that the store had more cashiers so I could get on with my day faster.
What does this have to do with system performance?
You’ve probably experienced a similar situation yourself and have your own tale to tell. It happens so frequently that sometimes we forget how applicable these situations can be to other domain areas, including distributed systems.Sometimes when you evaluate a new solution, the results don’t meet your expectations. Why is latency high? Why is the throughput so low? Those are two of the top questions that pop up every now and then.
Many times, the challenges can be resolved by optimizing your performance testing approach, as well as better maximizing your solution’s potential. As you’ll realize, improving the performance of a distributed system is a lot like ensuring speedy checkouts in a grocery store.
This blog covers 7 performance-focused steps for you to follow as you evaluate distributed systems performance.
Step #1: Measure Time
With groceries, the first step towards doing any serious performance optimization is to precisely measure how long it takes for a single cashier to scan a barcode. Some goods, like bulk fruits that require weighing, may take longer to scan than products in industrial packaging.
A common misconception is that processing happens in parallel. It does not (note: we’re not referring to capabilities like SIMD and pipelining here). Cashiers do not service more than a single person at a time, nor do they scan your products’ barcodes simultaneously. Likewise, a single CPU in a system will process one work unit at a time, no matter how many requests are sent to it.
In a distributed system, consider all the different work units you have and execute them in an isolated way against a single shard. Execute your different items with single-threaded execution and measure how many requests per second the system can process.
Eventually, you may learn that different requests get processed at different rates. For example, if the system is able to process a thousand 1 KB requests/sec, the average latency is 1ms. Similarly, if throughput is 500 requests/sec for a larger payload size, then the average latency is 2ms.
Step #2: Find the Saturation Point
A cashier is never scanning barcodes all the time. Sometimes, they will be idle waiting for customers to place their items onto the checkout counter, or waiting for payment to complete. This introduces delays you’ll typically want to avoid.
Likewise, every request your client submits against a system incurs, for example, network round trip time – and you will always pay a penalty under low concurrency. To eliminate this idleness and further increase throughput, simply increase the concurrency. Do it in small increments until you observe that the throughput saturates and the latency starts to grow.
Once you reach that point, congratulations! You effectively reached the system’s limits. In other words, unless you manage to get your work items processed faster (for example, by reducing the payload size) or tune the system to work more efficiently with your workload, you won’t achieve gains past that point.
You definitely don’t want to find yourself in a situation where you are constantly pushing the system against its limits, though. Once you reach the saturation area, fall back to lower concurrency numbers to account for growth and unpredictability.
Step #3: Add More Workers
If you live in a busy area, grocery store demand might be beyond what a single cashier can sustain. Even if the store happened to hire the fastest cashier in the world, they would still be busy as demand/concurrency increases.
Once the saturation point is reached it is time to hire more workers. In the distributed systems case, this means adding more shards to the system to scale throughput under the latency you’ve previously measured. This leads us to the following formula:
Number of Workers = Target Throughput / Single worker limit
You already discovered the performance limits of a single worker in the previous exercise. To find the total number of workers you need, simply divide your target throughput by how much a single worker can sustain under your defined latency requirements.
Distributed systems like ScyllaDB provide linear scale, which simplifies the math (and total cost of ownership [TCO]). In fact, as you add more workers, chances are that you’ll achieve even higher rates than under a single worker. The reason is due to Network IRQs, and out of scope for this write-up (but see this perftune docs page for some details).
Step #4: Increase Parallelism
Think about it. The total time to check out an order is driven by the number of items in a cart divided by the speed of a single cashier. Instead of adding all the pressure on a single cashier, wouldn’t it be far more efficient to divide the items in your shopping cart (our work) and distribute them among friends who could then check out in parallel?
Sometimes the number of work items you need to process might not be evenly split across all available cashiers. For example, if you have 100 items to check out, but there are only 5 cashiers, then you would route 20 items per counter.
You might wonder: “Why shouldn’t I instead route only 5 customers with 20 items each?” That’s a great question – and you probably should do that, rather than having the store’s security kick you out.
When designing real-time low latency OLTP systems, however, you mostly care about the time it takes for a single work unit to get processed. Although it is possible to “batch” multiple requests against a single shard, it is far more difficult (though not impossible) to consistently accomplish that task in such a way that every item is owned by that specific worker.
The solution is to always ensure you dispatch individual requests one at a time. Keep concurrency high enough to overcome external delays like client processing time and network RTT, and introduce more clients for higher parallelism.
Step #5: Avoid Hotspots
Even after multiple cashiers get hired, it sometimes happens that a long line of customers queue after a handful of them. More often than not you should be able to find less busy – or even totally free – cashiers simply by walking through the hallway.
This is known as a hotspot, and it often gets triggered due to unbound concurrency. It manifests in multiple ways. A common situation is when you have a traffic spike to a few popular items (load). That momentarily causes a single worker to queue a considerable amount of requests. Another example: low cardinality (uneven data distribution) prevents you from fully benefiting from the increased workforce.
There’s also another commonly overlooked situation that frequently arises. It’s when you dispatch too much work against a single worker to coordinate, and that single worker depends on other workers to complete that task. Let’s get back to the shopping analogy:
Assume you’ve found yourself on a blessed day as you approach the checkout counters. All cashiers are idle and you can choose any of them. After most of your items get scanned, you say “Dear Mrs. Cashier, I want one of those whiskies sitting in your locked closet.” The cashier then calls for another employee to pick up your order. A few minutes later, you realize: “Oops, I forgot to pick up my toothpaste,” and another idling cashier nicely goes and picks it up for you.
This approach introduces a few problems. First, your payment needs to be aggregated by a single cashier – the one you ran into when you approached the checkout counter. Second, although we parallelized, the “main” cashier will be idle waiting for their completion, adding delays. Third, further delays may be introduced in between each additional and individual request completion: for example, when the keys of the locked closet are only held by a single employee, so the total latency will be driven by the slowest response.
Consider the following pseudocode:
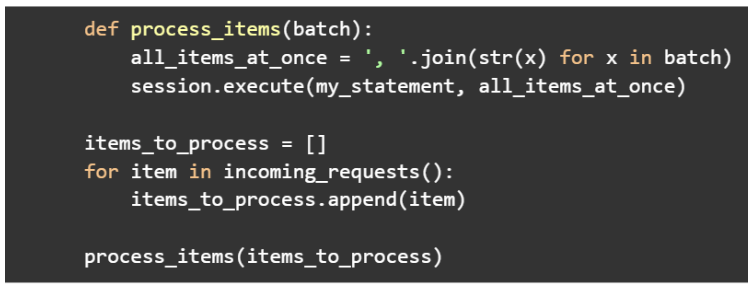
See that? Don’t do that. The previous pattern works nicely when there is a single work unit (or shard) to route requests to. Key-value caches are a great example of how multiple requests can get pipelined all together for higher efficiency. As we introduce sharding into the picture, this becomes a great way to undermine your latencies given the previously outlined reasons.
Step #6: Limit Concurrency
When more clients are introduced, it’s like customers inadvertently ending up at the supermarket during rush hour. Suddenly, they can easily end up in a situation where many clients all decide to queue under a handful of cashiers.
You previously discovered the maximum concurrency at which a single shard can service requests. These are hard numbers and – as you observed during small scale testing – you won’t see any benefits if you try to push requests further. The formula goes like this:
Concurrency = Throughput * Latency
If a single shard sustains up to 5K ops/second under an average latency of 1 ms, then you can execute up to 5 concurrent in-flight requests at all times.
Later you added more shards to scale that throughput. Say you scaled to 20 shards for a total throughput goal of 100K ops/second. Intuitively, you would think that your maximum useful concurrency would become 100. But there’s a problem.
Introducing more shards to a distributed system doesn’t increase the maximum concurrency that a single shard can handle. To continue the shopping analogy, a single cashier will continue to scan barcodes at a fixed rate – and if several customers line up waiting to get serviced, their wait time will increase.
To mitigate (though not necessarily prevent) that situation, divide the maximum useful concurrency among the number of clients. For example, if you’ve got 10 clients and a maximum useful concurrency of 100, then each client should be able to queue up to 10 requests across all available shards.
This generally works when your requests are evenly distributed. However, it can still backfire when you have a certain degree of imbalance. Say all 10 clients decided to queue at least one request under the same shard. At a given point in time, that shard’s concurrency climbed to 10, double our initially discovered maximum concurrency. As a result, latency increases, and so does your P99.
There are different approaches to prevent that situation. The right one to follow depends on your application and use case semantics. One option is to limit your client concurrency even further to minimize its P99 impact. Another strategy is to throttle at the system level, allowing each shard to shed requests as soon as it queues past a certain threshold.
Step #7: Consider Background Operations
Cashiers do not work at their maximum speed at all times. Sometimes, they inevitably slow down. They drink water, eat lunch, go to the restroom, and eventually change shifts. That’s life!
It is now time for real-life production testing. Apply what you’ve learned so far and observe how the system behaves over long periods of time. Distributed systems often need to run background maintenance activities (like compactions and repairs) to keep things running smoothly.
In fact, that’s precisely the reason why I recommended that you stay away from the saturation area at the beginning of this article. Background tasks inevitably consume system resources, and are often tricky to diagnose. I commonly receive reports like “We observed a latency increase due to compactions”, only to find out later the actual cause was something else – for example, a spike in queued requests to a given shard.
Irrespective of the cause, don’t try to “throttle” system tasks. They exist and need to run for a reason. Throttling their execution will likely backfire on you eventually. Yes, background tasks slow down a given shard momentarily (that’s normal!). Your application should simply prefer other less busy replicas (or cashiers) when it happens.
For a great detailed discussion of these points, see Brian Taylor’s insights during his How to Maximize Database Concurrency talk.
Applying These Steps
Hopefully, you are now empowered to address questions like “why latency is high”, or “why throughput is so low”. As you start evaluating performance, start small. This minimizes costs, and gives you fine-grained control during each step.
If latencies are sub-optimal under small scale, it either means you are pushing a single shard too hard, or that your expectations are off. Do not engage in larger scale testing until you are happy with the performance a single shard gives you.
Once you feel comfortable with the performance of a single shard, scale capacity accordingly. Keep an eye on concurrency at all times and watch out for imbalances, mitigating or preventing them as needed. When you find yourself in a situation where throughput no longer increases but the system is idling, add more clients to increase parallelism.
These concepts generally apply to every distributed system out there, including ScyllaDB. Our shard-per-core architecture linearly scales, making it easy for you to follow through the steps we discussed here.
If you’d like to know more on how we can help, book a technical session with us.