



A recap of the recent Rust developer workshop, where we built and refactored a high-performance Rust app for real-time data streaming (with ScyllaDB and Redpanda).
Felipe Cardeneti Mendes (ScyllaDB Technical Director) and I recently got together with a couple thousand curious Rustaceans for a ScyllaDB Rust Developer Workshop. The agenda: walk through how we built and refactored a high-performance Rust app for real-time data streaming. We promised to show developers, engineers, and architects how to:
- Create and compile a sample social media app with Rust
- Connect the application to ScyllaDB (NoSQL data store) and Redpanda (streaming data)
- Negotiate tradeoffs related to data modeling and querying
- Manage and monitor the database for consistently low latencies
This blog post is a quick recap of what we covered. Hopefully, it’s a nice wrapup for those who joined us live. If you missed it, you can still watch the recording (uncut – complete with a little cat chasing!). And feel free to ping me or Felipe with any questions you have.
Attend P99 CONF (free + virtual) to watch Rust tech talks
First Things First
First, I wanted to cover how I approach an existing, legacy codebase that Felipe so kindly generated for the workshop. I think it’s really important to respect everyone who interacts with code – past, present and future. That mindset helps foster good collaboration and leads to more maintainable and high quality code. Who knows, you might even have a laugh along the way.
You probably spotted me using an Integrated Development Environment (IDE). Depending on your budget (from free to perhaps a couple hundred dollars), an IDE will really help streamline your coding process, especially when working with complex projects. The eagle eyed among you may have spotted some AI in there as well from our friends at GitHub. Every bit helps!
Dealing with Dependencies
In the code walkthrough, I first tackled the structure of the code, and showed how to organize workspace members. This helps me resolve dependencies efficiently and start to test the binaries in isolation:
[workspace]
members = ["backend", "consumer", "frontend"]
resolver = "1"Then I could just run the consumer after stopping it in docker-compose with:
cargo run --package consumer --bin consumerUpdating the Driver
Another thing I did was update the driver. It’s important to keep things in check with releases from ScyllaDB so we upgraded the Rust driver for the whole project.
I did a quick walkthrough of application functionality and decided to write a quick smoke test that simulated traffic on the front end in terms of messaging between users. If you’re interested, I used a great load testing tool called k6 to simulate that load. Here’s the script:
export default function () {
http.post('http://localhost:3001/new_post', JSON.stringify({
content: 'bar',
subject: 'foo',
id: '8d8712fc-786f-4d72-98ea-3669e56f7012'
}), {
headers: {
'Content-Type': 'application/json',
},
});
}Dealing with an Offset Bug
Once we had some messages flowing (perhaps way too many, as it turned out) I discovered a potential bug, where the offset was not being persisted between application restarts. This meant every time we restarted the application, all of the messages would be read from the topic and then re-written to the database.
Without understanding functionality like the ability to parse consumer offsets in Redpanda, I went for a more naive approach by storing the offset in ScyllaDB instead. I’m sure I’m not the first dev to go down the wrong path, and I fully blame Felipe for not intercepting earlier 😉
Refactoring Time
In any case, it was fun to see how we might approach the topic of refactoring code. It’s always easier to start with small, manageable tasks when making improvements or refactoring code.
The first thing I did was decide what the table (and ultimately query) might look like. This “query first design” is an important design concept in ScyllaDB..Be sure to check out some ScyllaDB University courses on this. I decided the table would look something like this to store my offset value:
CREATE TABLE IF NOT EXISTS ks.offset (consumer text PRIMARY KEY, count BigInt)We briefly touched on why I chose a BigInt primitive instead of a Counter value. The main reason is that we can’t arbitrarily set the latter to a value, only increment or decrement it. We then tackled how we might write to that table and came up with the following:
async fn update_offset(offset: i64, session: &Session, update_counter: &PreparedStatement, consumer: &str) -> Result<()> {
session.execute(update_counter, (offset, consumer)).await?;
Ok(())
}You’ll notice here that I’m passing it a prepared statement which is an important concept to grasp when making your code perform well with ScyllaDB. Be sure to read the docs on that if you’re unsure. I also recall writing a TODO to move some existing prepared query statements outside a for loop. The main reason: you only need to do this once for your app, not over and over. So watch out for that mistake.
I also stored my query as a constant:
const UPDATE_OFFSET: &str = "UPDATE ks.offset SET count = ? WHERE consumer = ?";There are different ways to skin this, like maybe some form of model approach, but this was a simple way to keep the queries in one place within the consumer code.
We restarted the app and checked the database using cqlsh to see if the offsets were being written – and they weren’t! But first, a quick tip from other webinars: If you’re running ScyllaDB in a docker container, you can simple exec to it and run the tool:
docker exec -it scylla cqlsh
Back to my mistake, why no writes to the table? If you recall, I write the offset after the consumer has finished processing records from the topic:
offset = consumer(&postclient, "posts", offset, &session).await;
update_offset(offset, &session, &update_counter, "posts").await.expect("Failed to update offset");
tokio::time::sleep(Duration::from_secs(5)).await;Since I had written a load test with something like 10K records, that consumer takes some time to complete, so update_offset wasn’t getting called straight away. By the end of the webinar, it actually finished reading from the topic and wrote the offset to the table. Another little change I snuck in there was on:
tokio::time::sleep(Duration::from_secs(5)).await;Felipe spoke to the benefits of using tokio, an asynchronous runtime for Rust. The previous thread sleep would in fact do nothing, hence the change. Hooray for quick fixes!
Once we had writes, we needed to read from the table, so I added another function that looked like this:
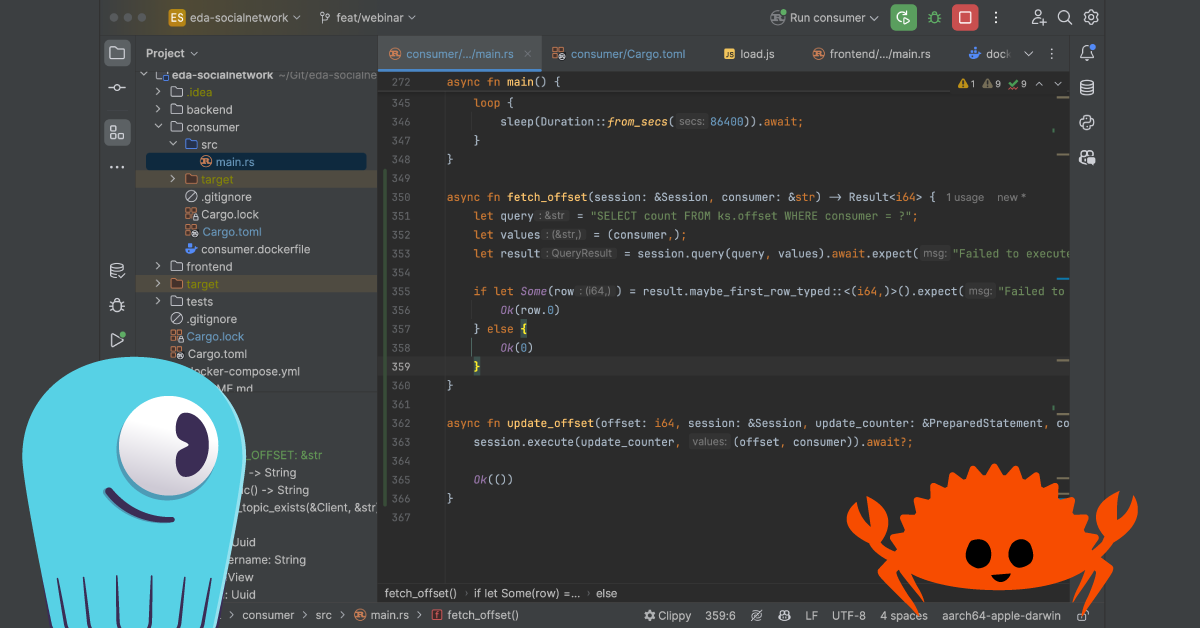
async fn fetch_offset(session: &Session, consumer: &str) -> Result {
let query = "SELECT count FROM ks.offset WHERE consumer = ?";
let values = (consumer,);
let result = session.query(query, values).await.expect("Failed to execute query");
if let Some(row) = result.maybe_first_row_typed::<(i64,)>().expect("Failed to get row") {
Ok(row.0)
} else {
Ok(0)
}
}I spoke about some common gotchas here, like misunderstanding how query values work, with different types, and whether to use a slice &[] or a tuple (). Query text is constant, but the values might change. You can pass changing values to a query by specifying a list of variables as bound values. Don’t forget the parenthesis!
I also highlighted some of the convenience methods in query result, like maybe_first_row_typed. That returns Option<RowT> containing the first row from the result – which is handy when you just want the first row or None. Once again, you can play around with types, and even use custom structs if you prefer for the output. In my case, it was just a tuple with an i64.
The complete consumer code for posts looked something like this:
tokio::spawn(async move {
use std::time::Duration;
info!("Posts Consumer Started");
let session = db_session().await;
let update_counter = session.prepare(UPDATE_OFFSET).await.expect("Failed to prepare query");
loop {
let mut offset = fetch_offset(&session, "posts").await.expect("Failed to fetch offset");
offset = consumer(&postclient, "posts", offset, &session).await;
update_offset(offset, &session, &update_counter, "posts").await.expect("Failed to update offset");
tokio::time::sleep(Duration::from_secs(5)).await;
}
});You can see I prepare the statement before the loop, then I fetch the offset from the database, consume the topic, write the offset to the database and sleep. Keep doing that forever!
What We Didn’t Have Time to Cover
There were a few things that I wanted to cover, but ran out of time. If you wanted to write results to a custom struct, the code might look something like:
#[derive(Default, FromRow)]
pub struct Offset {
consumer: String,
count: i64,
}
use scylla::IntoTypedRows;
async fn fetch_offset_type(session: &Session, consumer: &str) -> Offset {
let query = "SELECT * FROM ks.offset WHERE consumer = ?";
let values = (consumer,);
let result = session.query(query, values).await.expect("Failed to execute query");
if let Some(rows) = result.rows {
if let Some(row) = rows.into_typed::().next() {
let offset: Offset = row.expect("Failed to parse row");
return offset;
}
}
Offset {
consumer: consumer.to_string(),
count: 0,
}
}There are some custom values you’ll come across like CqlTimestamps and Counter… so you should be aware of the ways to handle these different data types. For example, rather than convert everything to and from millisecond timestamps, you can add the chrono feature flag on the crate to interact with time.
You can also improve logging with the driver’s support of the tracing crate for your logs. If you add that, you can use a tracing subscriber as follows:
#[tokio::main]
async fn main() {
tracing_subscriber::fmt::init();
…Wrapping Up
I personally find refactoring code enjoyable. I’d encourage you to have a patient, persistent approach to coding, testing and refactoring. When it comes to ScyllaDB it’s a product where it really pays to read the documentation, as many of the foot guns are well documented. If you still find yourself stuck, feel free to ask questions on the ScyllaDB forum and learn from your peers.
And remember, small, continuous improvements lead to long-term benefits. Have fun!




