



In high throughput read-heavy systems having good cacheability is paramount to good performance. DRAM access (measured in nanoseconds), is far faster than even the fastest of the storage systems (measured in µseconds), and on top of that, caches have the luxury of storing finished post-processed results of computations, making returning them again even faster. For example, data to serve a query in ScyllaDB from storage may be spread over multiple files. This data will have to be read, deserialized, and combined into a single entry so that it can be returned to the client. The ScyllaDB cache will store the end result of that process, making the difference in efficiency between a storage-bound read and a cached read much wider than just the speed difference between the DRAM and storage technologies.
In this article we will explore one IoT/time-series classical scenario in which knowledge of how the cache operates can mean the difference between a fully cached workload that will be fast, and a fully storage-bound workload that will of course perform much worse.
How to query slices of time?
Consider the following table schema
This is a classic and simple model for anything that is related to IoT and/or timeseries: there is a UUID that is associated with some component of the system (a sensor, a stock ticker, etc), and we want to track events that happen in a specific time frame.
One of the most common patterns is to query events from a certain point in the past until the current time. There are two ways of specifying such a query:
Although those queries look equivalent, we will show in this article how they are, internally, completely different and can have wildly different performance characteristics. But for that to make sense, we need a quick explanation about how the ScyllaDB cache works.
The ScyllaDB cache
The ScyllaDB cache is able to track two kinds of objects:
- rows, in which case the cache will contain the key and value for the row
- a negative entry, in which case ScyllaDB will track the fact that an entry for that key does not exist in the database.
Rows are always individual entries: the cache either knows the value associated with a key, or it doesn’t. Negative entries, however, can either be singular or ranges. This shouldn’t be hard to understand: we can know that the key ‘5’ does not exist, but we can just as easily know that ‘nothing exists between 5 and 50’
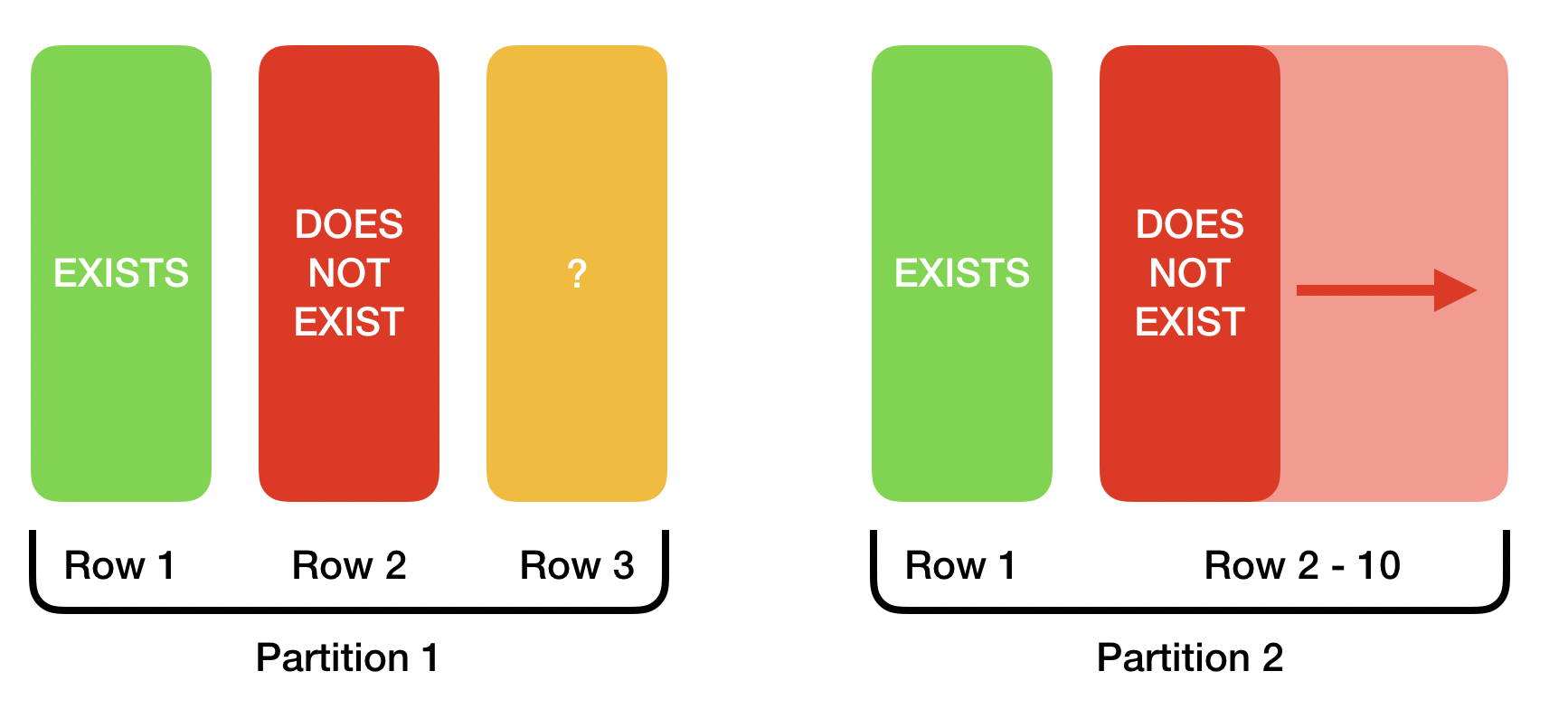
Figure 1 shows two partitions cached. The first partition has three rows. We know the value of Row 1, and know that Row 2 does not exist. But we know nothing about Row 3. In the second partition we know Row 1’s value, and we also know that nothing exists between Rows 2 to 10.
Let’s start from a completely empty cache, and use the CQL tracing functionality to examine what is happening internally with each of the queries below. We will start with a simple query, in which we query a time point that exists in the database, but about which the cache knows nothing:
The database returns the query, as expected, and the tracing data will tell us how ScyllaDB accomplished that:
As we can see from the trace above, at some point we need to go into the storage system to read the desired key from a particular file (in this case mc-6-big-Data.db). But what happens if we try the same query again? As expected, that line is no longer there, indicating that ScyllaDB was able to cache this entry.
Since ScyllaDB caches negatives too, we expect to see a similar pattern if we query for a non-existent time point, that is slightly in the future. And indeed we will see a storage access present in the first trace, but absent in the second, indicating that ScyllaDB was able to properly cache the non-existent entry.
And repeating the same query:
Now what happens if we have another query, in which we want to query for a time range that is bounded by those two points? It is a reasonable expectation that this query will be served entirely from the cache. After all, this query will just return the same one data point as before. But how can ScyllaDB know for sure that the range between them is empty? The answer is that without searching for that explicitly it can’t, and a range query bound by those two time points will, at first, hit the storage:
However now that we explicitly searched for a range, we can populate the cache with a richer negative information: we can say that the entire range is absent. The cache will now look like this:
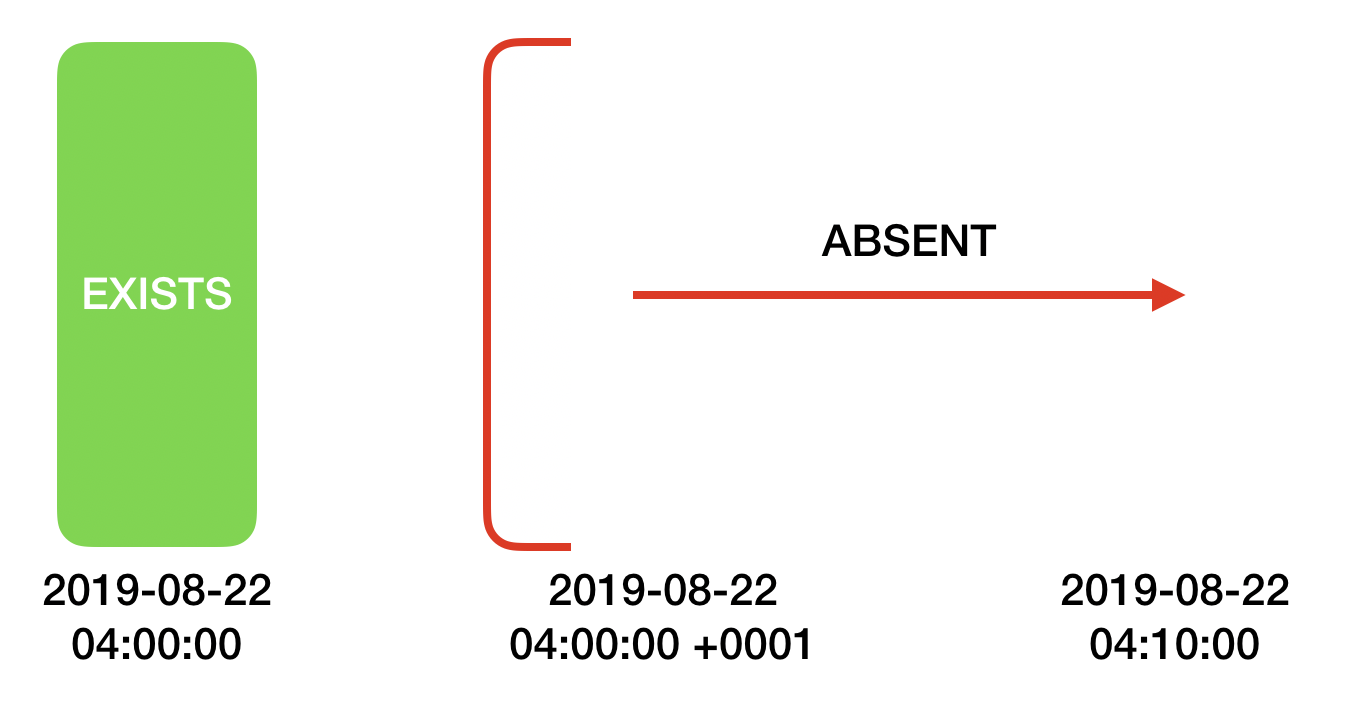 Figure 2 shows the status of the cache after the search happens.
Figure 2 shows the status of the cache after the search happens.
And indeed, with this newfound information querying it again we can see that the query can be served entirely from the cache:
The Antipattern
Now that we understand how the cache works, it should be trivial to understand why the two queries that we are analyzing behave so differently. Let’s consider the first query, and let’s assume for the sake of example that “now” is ‘2019-08-22 01:00:00’
Once this query is done, ScyllaDB will have cached all it knows (as long as it fits in the cache) about the data between the points ‘2019-08-22 00:00:00’ and ‘2019-08-22 01:00:00’. If there are rows in that interval, ScyllaDB will store those rows, and if there are gaps, ScyllaDB will store the fact that those gaps are empty. But what happens if the same query is issued one hour later, when “now” is ‘2019-08-22 02:00:00’? ScyllaDB cannot know what data is there between 01:00:00 and 02:00:00 and has to read it from storage! This happens regardless of whether or not there is a new row that got inserted in the interval so ScyllaDB will be forced to check. Do the CQL traces confirm that? We will see that they do:
At this point the astute reader is asking themselves: why can’t ScyllaDB cache all possible ranges and just keep the cache updated if there are new incoming data? The answer to that is that it can, but it will not do so unless explicitly asked, as this would make the initial query more expensive: if all we wanted was a fixed range in the past anyway, there is no reason to make that query more expensive just because an arbitrary query for a slightly longer range could arrive in the future.
So how do we tell ScyllaDB to keep this time range updated, so that this query always caches well? We do that by not specifying an end range, and writing the query like this:
This will cause the cache to store a range negative entry in which the right bound is +Infinity. And as we expected, that query will now be served entirely from cache. Also because new inserts will intersect with this open range, the cache will be kept up-to-date with the new data (as long as the new data still fits in the cache). Do the tracing data confirm that? The answer is yes, it does:
Conclusion
Querying data by time ranges is a stable of time-series-like data, which is a common use case for ScyllaDB, the monstrously fast and scalable NoSQL database. Often, applications need to query an open range, from a fixed time in the past until “now.” In this article we looked at two ways of performing such queries: one by always explicitly specifying the current time, and another by using an open range specifying only the beginning of the interval. We discussed how those two seemingly similar approaches will yield vastly different access patterns in the ScyllaDB cache and demonstrated that using open ranges will provide superior results.
To know more about the ScyllaDB Cache and how it works in detail, check out this article by Tomasz Grabiec.



