Learn how to integrate ScyllaDB with PrestoDB and Metabase, unlocking powerful data analytics capabilities.
The integration of ScyllaDB, Presto, and Metabase provides an open-source data analytics solution for high-speed querying and user-friendly visualization. This blog shows a hands-on example of how it works and why this integration is worth exploring further.
We’ll cover how to:
- Unlock real-time insights: Merge ScyllaDB’s speed with Presto’s processing power to gain real-time insights from your data without delays.
- Simplify data exploration: Metabase’s intuitive UI makes data exploration and visualization accessible to everyone, regardless of technical skills.
- Break data silos: Seamlessly query and analyze data from ScyllaDB alongside other sources, breaking down data silos and enhancing overall efficiency.
Here are some of the benefits of choosing this solution:
- High performance, big data: Leverage ScyllaDB’s performance and Presto’s scalability for swift data processing, ideal for handling substantial data volumes.
- Adaptability: Accommodate evolving data structures with ScyllaDB and Presto, ensuring your analytics are never limited by rigid schemas.
- Empowering visualization: Metabase’s user-centric approach empowers business users to create impactful visualizations and reports, fostering data-driven decisions.
In short, integrating ScyllaDB, Presto, and Metabase creates a dynamic solution that supercharges data utilization, delivering speed, flexibility, availability and accessibility.
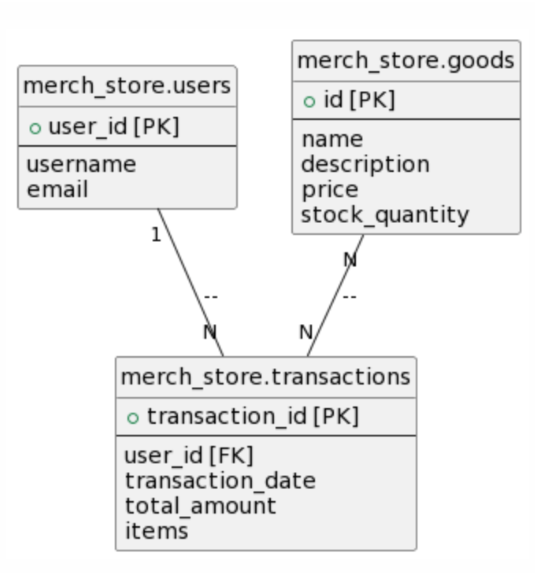
Database Schema
In the following hands-on exercise, you will use a simple DB schema for an online merchandise store with users, goods, and transactions.
Here is the example db schema:
And here is the architecture:
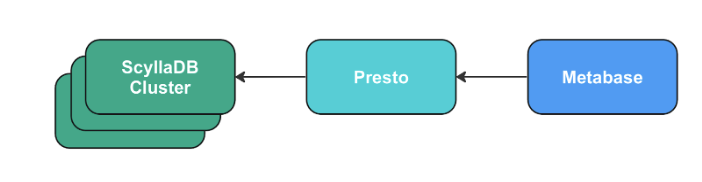
It includes:
- ScyllaDB: A high-throughput low-latency NoSQL database (available as open source).
- Presto: An open-source distributed SQL query engine.
- Metabase: An open-source business intelligence and data visualization tool.
About Presto
In this lesson, you will be working with Presto, an open-source distributed SQL query engine designed to run interactive analytic queries against various data sources. Facebook developed it, and it is now actively maintained by the Presto Software Foundation.
Presto consists of the following components:
- Coordinator: The Coordinator node is responsible for receiving user queries, parsing and analyzing them, and creating a query plan. It coordinates the execution of queries across multiple worker nodes.
- Worker: Worker nodes are responsible for executing the tasks assigned to them by the Coordinator. They perform data retrieval, processing, and aggregation tasks as part of the distributed query execution.
- Catalog: The Catalog represents the metadata about the available data sources and their tables. It helps Presto understand how to access and query the data stored in various data stores like ScyllaDB.
- Connector: Connectors are plugins that allow Presto to communicate with different data sources. Each connector understands how to translate SQL queries into the respective data source’s query language and how to fetch the data.
- SQL Parser: This component parses the SQL queries submitted by users and transforms them into an internal representation that the Coordinator can understand.
- Query Optimizer: The Query Optimizer analyzes the query plan and tries to find the most efficient way to execute the query. It aims to minimize data movement and processing overhead to improve performance.
- Execution Engine: The Execution Engine executes the query plan generated by the Coordinator. It coordinates the execution across multiple worker nodes, ensuring the data processing tasks are distributed efficiently.
By integrating a ScyllaDB cluster with Presto, you can leverage the power of SQL queries to access and analyze data stored in ScyllaDB using the Presto SQL dialect, making it easier to gain insights and perform analytics on large datasets. Additionally, using Metabase as a visualization tool, you can create interactive dashboards and visualizations based on the data queried through Presto, enhancing your data exploration capabilities.
About Metabase
Metabase is an open-source business intelligence and data visualization tool. It is designed to make it easy for non-technical users to explore, analyze, and visualize data without complex SQL queries or programming skills.
Metabase consists of the following main components:
- Dashboard: The Dashboard is the user interface of Metabase, where users interact with the tool to explore data and create visualizations. It provides a user-friendly interface that allows users to build custom dashboards and visualizations using a drag-and-drop approach.
- Query Builder: The Query Builder is an essential part of Metabase that enables users to create queries and retrieve data from various data sources. It offers a simple and intuitive way to construct SQL-like queries without requiring users to write raw SQL code.
- Data Model: Metabase maintains a data model that represents the metadata about the available data sources and the underlying database schemas. This data model helps users understand the structure of the data and aids in creating meaningful visualizations.
- Visualization Engine: Metabase comes equipped with a powerful Visualization Engine that allows users to create a wide range of charts, graphs, and other visual representations of their data. It supports various visualization types, such as bar charts, line charts, pie charts, and more.
- Database Drivers: Metabase uses database drivers to connect to different data sources, including relational databases, NoSQL databases, and other data storage systems. These drivers facilitate data retrieval and enable Metabase to interact with various databases.
- Permissions and Access Control: Metabase provides a robust system for managing user permissions and access control. Administrators can control which users can access specific data sources, dashboards, and features, ensuring data security and privacy.
Using Metabase alongside Presto and the integrated ScyllaDB cluster, you will create insightful visualizations and interactive dashboards based on the data queried through Presto. This combination allows for a seamless end-to-end data analysis and visualization process, making it easier to gain actionable insights from your data and share them with stakeholders effectively.
Services Setup With Docker
In this lab, you’ll use Docker.
First, ensure that your environment meets the following prerequisites:
- Docker for Linux, Mac, or Windows. Please note that running ScyllaDB in Docker is only recommended to evaluate and try
- ScyllaDB. For best performance, a regular install is recommended.
- 4GB of RAM or greater for ScyllaDB, Presto, and Metabase services
- Git
When docker is installed, we can run the whole infra with a single docker-compose from https://github.com/scylladb/scylla-code-samples/tree/master/presto.
Check out ScyllaDB’s code samples and go to the preso directory with all the required assets.
git clone git@github.com:scylladb/scylla-code-samples.git
cd scylla-code-samples/prestoRun docker compose. It creates a docker network “presto” and creates and starts containers with a single node ScyllaDB server, a Presto server and a Metabase server:
docker compose up -dIt takes about 40s for ScyllaDB to initialize. You can check the status of Presto and Metabase by running:
docker compose psAs long as it is still initializing the STATUS will show (health: starting), and once initialized it will show (healthy):
Check the status of the ScyllaDB cluster by running:
docker exec -it presto-scylladb-1 nodetool statusThe UN status shows that the ScyllaDB node is up and running.
Presto UI
Browse to the Presto UI at localhost:8080/ui
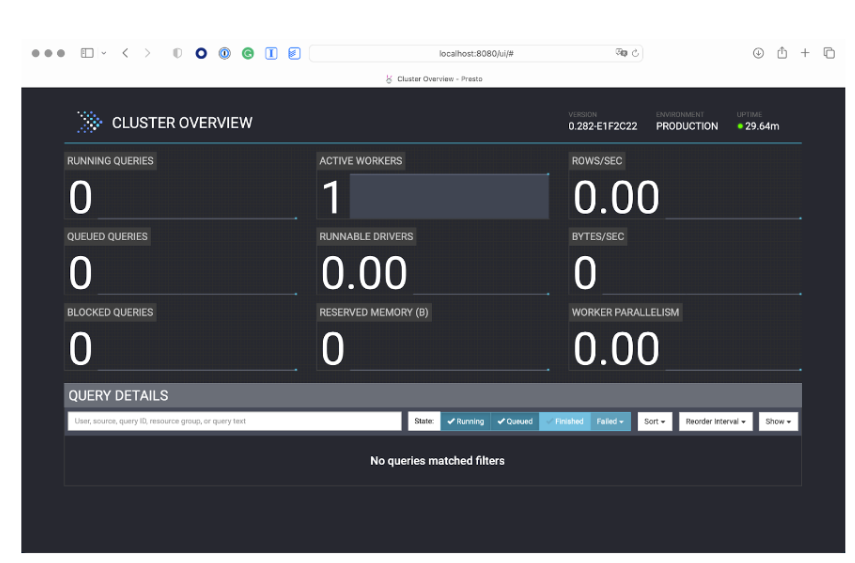
When queries are executed, it displays their execution result and some useful Presto server metrics:
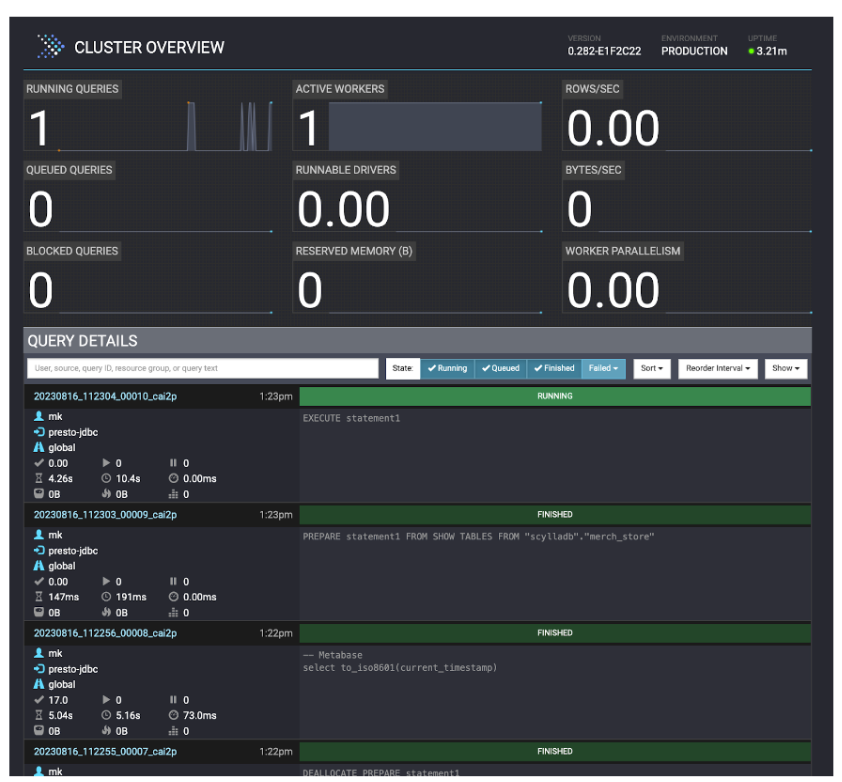
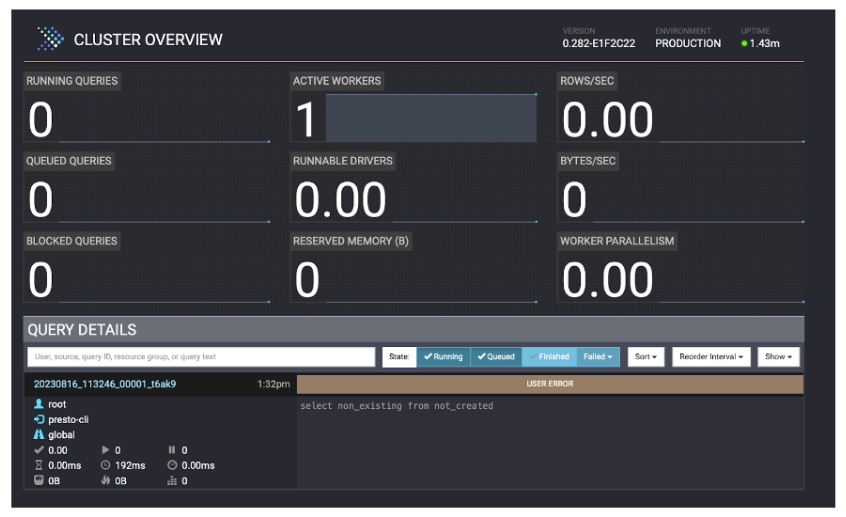
The UI is helpful for debugging errors. You can see some query details along with any failures. In the example above, all queries are successful. Below, is an example of a query that fails:
Metabase UI
Browse to the Metabase UI at localhost:3000
Testing the Integration
Data Preparation
Let’s create a namespace and generate a schema with sample data for our store:
make prepare_dataThis command will connect to ScyllaDB, and invoke cqlsh to fill the cluster with the schema and sample data from the data.txt file, which is located in the root of the presto directory.
Connect Metabase to Presto
After this part is complete and Metabase has started, continue with the setup process in the Metabase UI.
During the “Add your data” step, choose Presto.
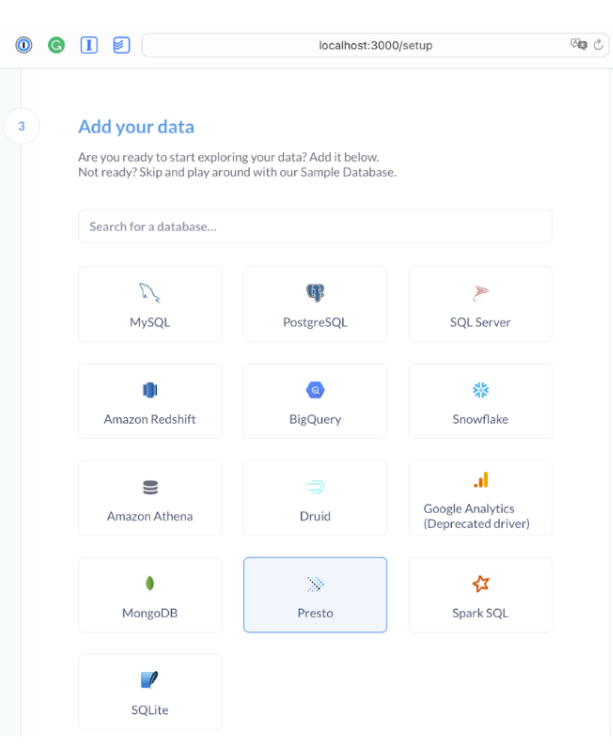
Then fill in all required fields except “password”, and leave it empty, it will still show the grayed masked points.
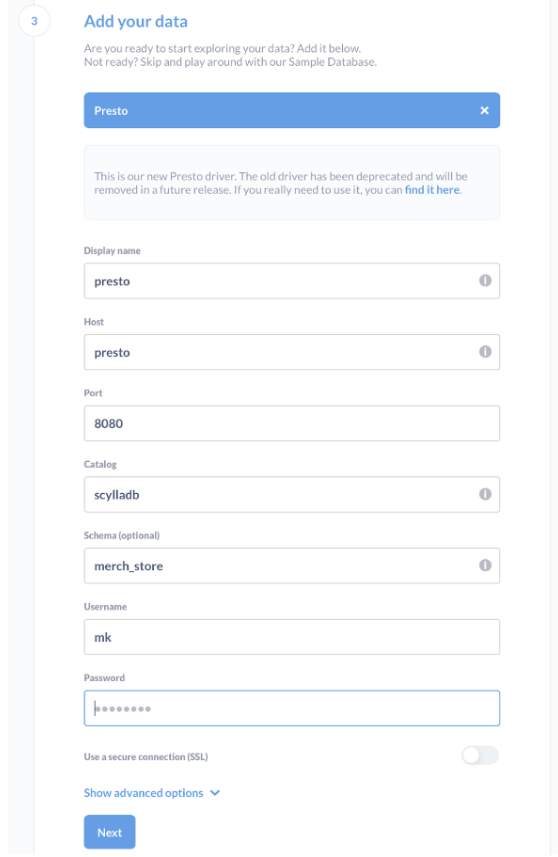
Here are the details of each field:
- Setting host to “presto”. This is how the Presto service is called in docker-compose.
- Setting a port to
8080. This is the default port for presto. We did not override it. - Setting catalog to
scylladb. This name comes from the catalog name we use in Presto by adding the file scylladb.properties in the presto/resources/etc/catalog directory. - The schema name
merch_storecomes from the sample data. - The username is a free type string here.
- We left the password empty with a masked example from Metabase.
After onboarding completion, Metabase will show the home dashboard with a small hint in the right-down corner saying that it is in the process of syncing tables from our presto installation.
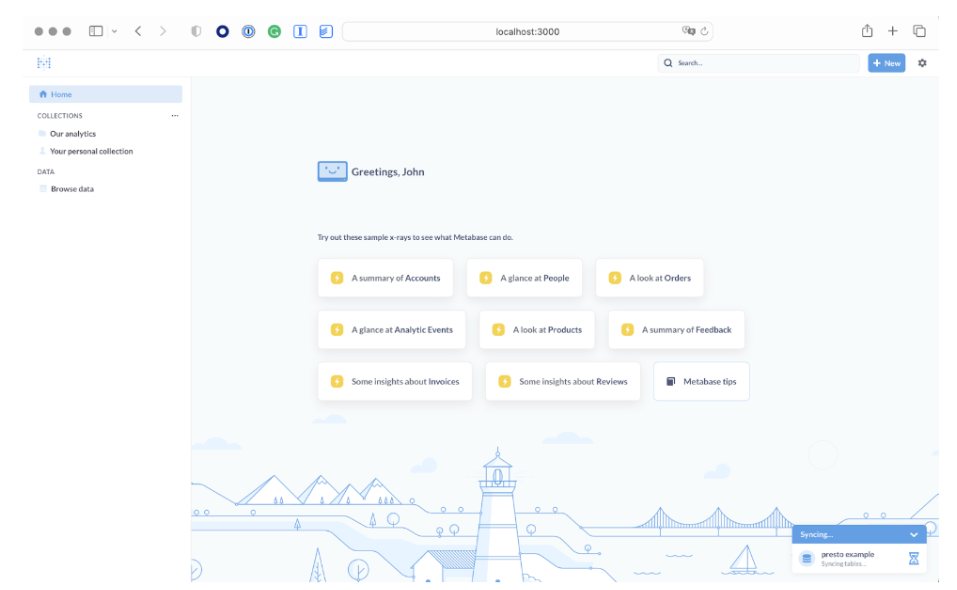
Here you have insights about the test data that Metabase added for a demo. You can delete the Sample database from admin settings -> Databases -> Sample database -> Remove database. After deleting the sampling database and waiting for about a minute or two, Metabase will generate insights based on the schema and data that we prepared. The dashboard looks like this:
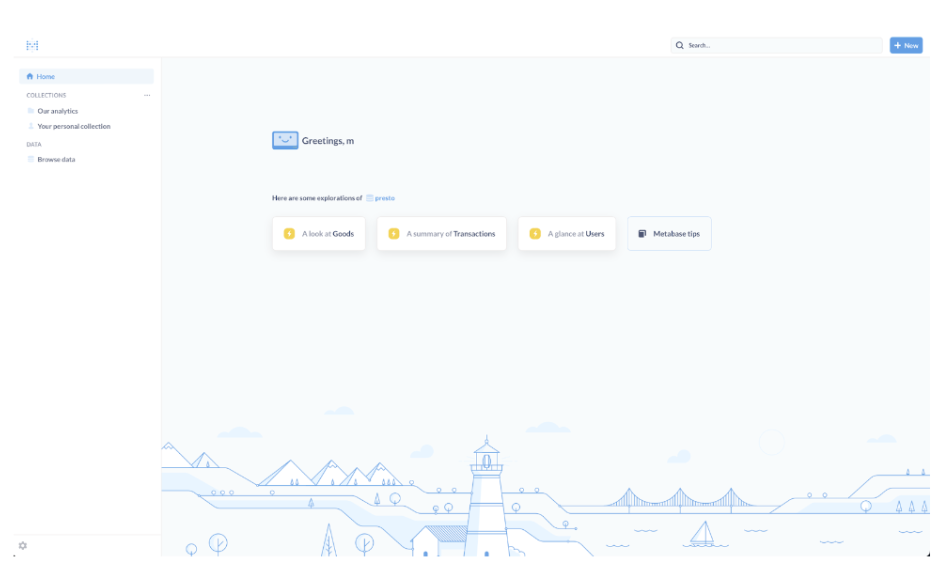
Next, open the “A summary at Transactions” insight. It shows some insights into the transaction data.
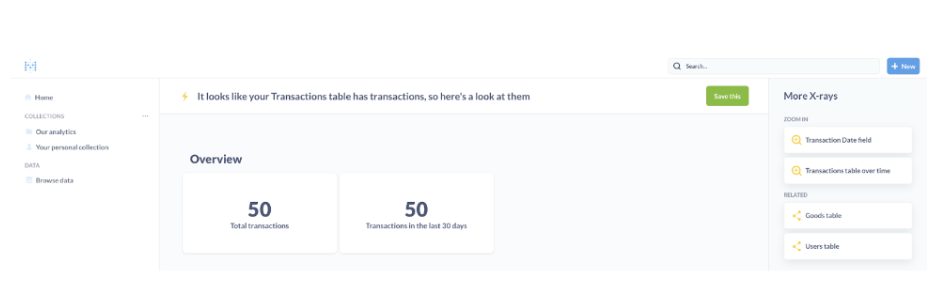
Example Insights
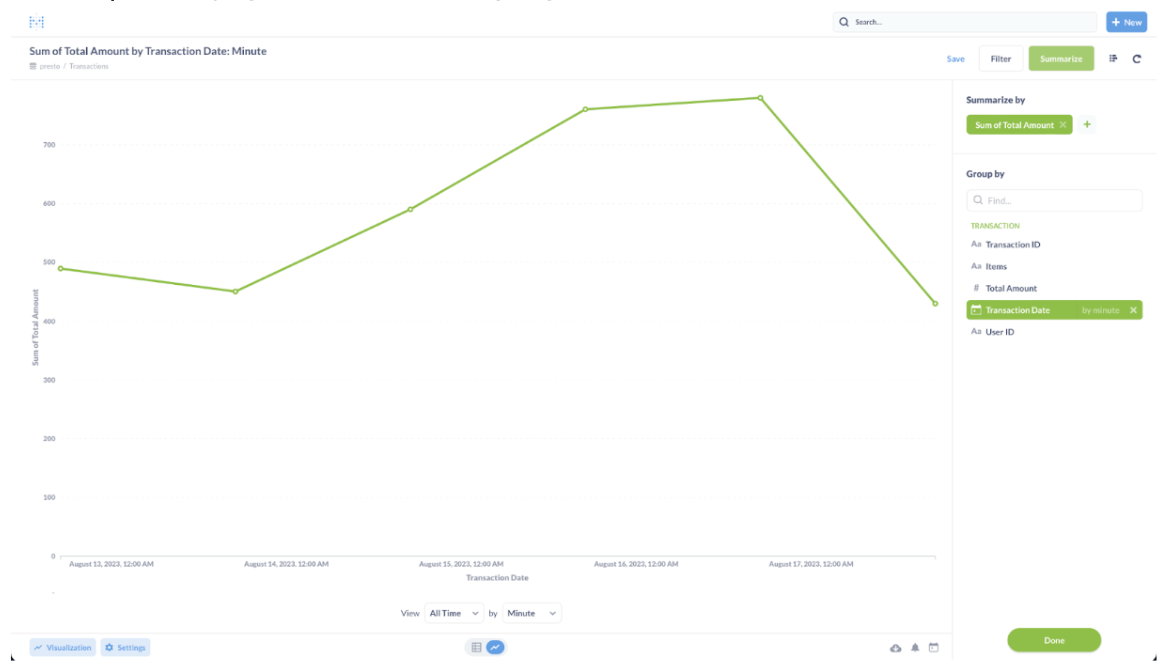
Here’s an example of how the integration lets you get insights, such as creating a dashboard to show the sum of transactions per day:
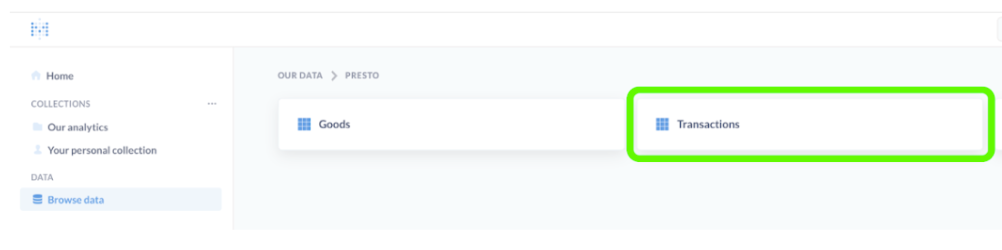
- Click on the “Browse Data” section in the menu on the left.
- Choose the “Presto” database.
- Choose the “Transactions” table.

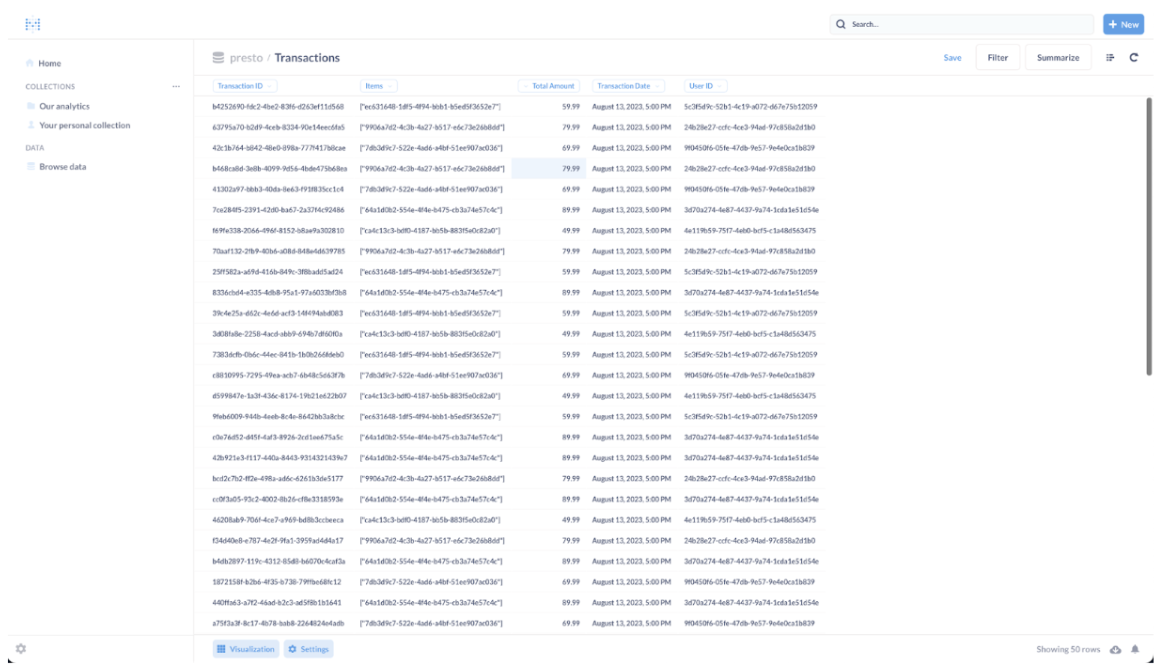
You will see transactions as a table with all available fields.

- On the right corner of the UI, click on “Summarize” to start building the report.

- Click on the green “Count.”
 and select “Sum of…”
and select “Sum of…”
 Metabase will propose a column on which to sum.
Metabase will propose a column on which to sum.
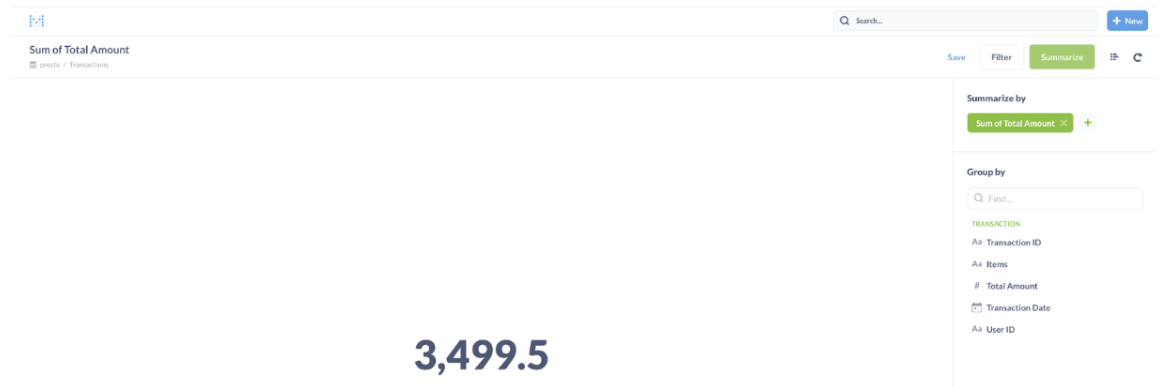
Select “Total Amount”. Selecting the column to sum by Metabase will calculate the whole sum of all transactions and display just a number.

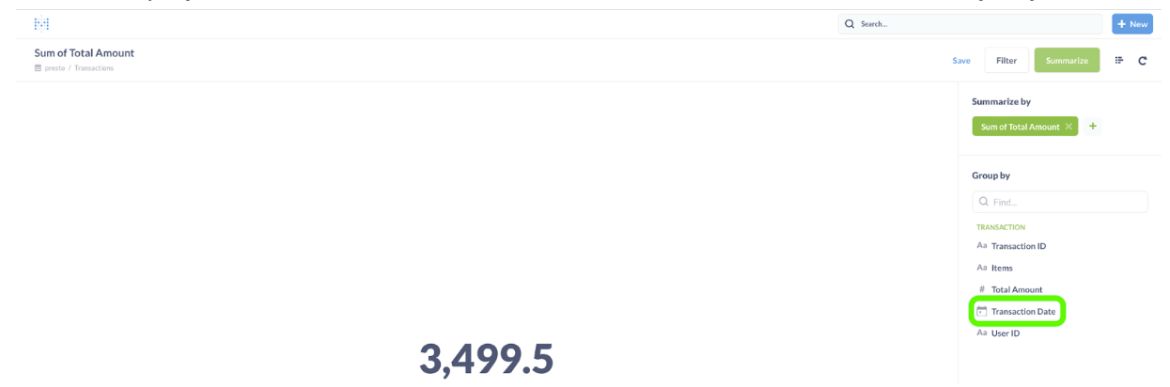
- In the Group by section, choose the “Transaction Date” column to calculate the sum by day.

Metabase will display transactions sum by day in the line view

- Click on “Save” to persist the created report to the existing dashboard or to a new one.

 and select “Sum of…”
and select “Sum of…”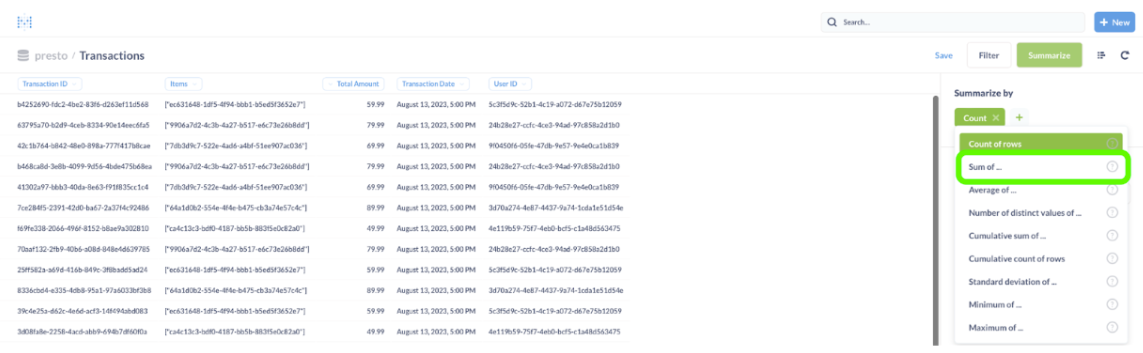 Metabase will propose a column on which to sum.
Metabase will propose a column on which to sum.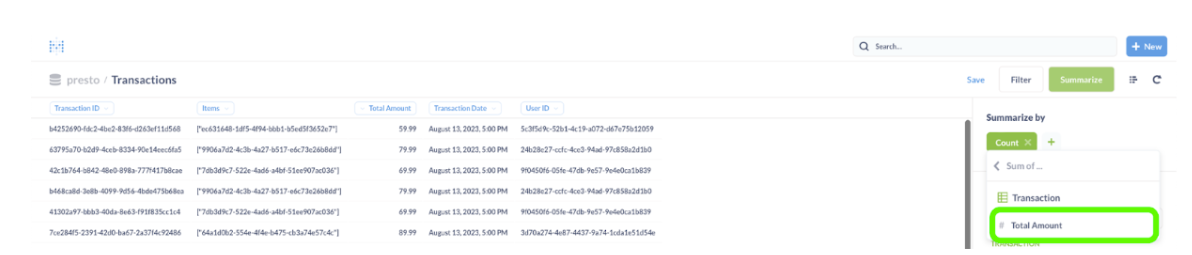
See it in Action
Watch the following video to see:
- The above example (transaction sums),
- A second example, which demonstrates how to create a table of the most valuable users by joining the transactions table with the users table
- How to create a custom dashboard
Cleanup
Clean-up is as easy as startup. Just use
docker-compose down --volumes
This stops all running docker containers and removes the created volumes.
Summary
In this lesson, you learned how to integrate a ScyllaDB, cluster with a Presto server, unlocking powerful data analytics capabilities. ScyllaDB’s high performance complements Presto’s distributed SQL query engine. Leveraging ScyllaDB’s capabilities with Presto enables lightning-fast data retrieval and processing, which is ideal for handling large-scale data workloads. The integration empowers users to explore and analyze vast datasets effortlessly, making data-driven decisions more accessible and efficient. Combined with Metabase’s intuitive visualization tools, this integration forms a robust end-to-end solution for deriving valuable insights from your data, empowering businesses to stay competitive in a data-driven world.
For more information, see the ScyllaDB docs on integrating with Presto.