




Last week we hosted the ScyllaDB University LIVE Summer Session virtual training. It was held on two consecutive days, one more convenient for EMEA timezones and another for the Americas.
Attendance was high. We saw a 27% increase in the number of participants from our previous LIVE event held in April, plus we were very pleased to see that both days had roughly equal numbers of attendees.
Our attendees came from a broad range of industry leading companies such as Amazon, Ericsson, Disney, Expedia, Apple, Fujitsu, Nubank, Rackspace, Palo Alto Networks, RSA, Salesforce and many others.
We don’t have an on-demand version of the event. However, you can find the slides from the different sessions, quiz questions, and some of the labs on ScyllaDB University. Here is the one for the Advanced topics course. For those of you that are not familiar with ScyllaDB University, it’s our online, free, self-paced ScyllaDB training center. To get started all you have to do is create a user account.
Users that complete a course will get a certificate of completion and some bragging rights.
You had Questions? We had Answers!
Participants asked lots of questions in the different sessions and in the Expert Panel. Here are some of the more interesting ones:
Q: Are Materialized Views stable enough for production or are they still in testing?
A: ScyllaDB’s Materialized View feature has been available since 2019. They are stable and in production; the feature has reached General Availability (GA) status. Learn more here.
Q: What are the benefits of migrating from Cassandra to ScyllaDB?
A: In addition to better performance, the cluster will behave in a more predictable and consistent way. ScyllaDB is implemented in C++ and you don’t have to worry about Garbage Collection (GC). Also ScyllaDB auto tunes itself and it’s much easier to maintain. Also, ScyllaDB has some unique features, or features that are implemented in a better way than in Cassandra. For instance, our Change Data Capture (CDC) feature makes it far easier to consume change data right out of a CQL-readable table. Also, ScyllaDB’s Materialized Views are production-ready, while Cassandra’s are not. ScyllaDB’s Lightweight Transactions (LWT) feature is implemented more efficiently and performant than Cassandra’s. You can read more about the important differences between ScyllaDB and Cassandra here.
Q: How can I migrate from Cassandra to ScyllaDB?
A: There are different ways to migrate, one is the SSTable Loader tool, another is the ScyllaDB Spark Migrator. You can read more about it in the documentation. Notice that these migration strategies can be done without any downtime.
Q: What are the differences between ScyllaDB Cloud and ScyllaDB Enterprise?
A: ScyllaDB Cloud is a fully-managed database as a service (DBaaS). Under the hood it runs ScyllaDB Enterprise. However we take care of things like software updates, backups, repairs, day-to-day monitoring, and security hardening so you can concentrate on your application development.
Q: When would it make sense to use the ScyllaDB DynamoDB compatible API (Project Alternator) as opposed to using CQL?
A: If you’re starting from scratch, it would make more sense to use CQL. If you have an existing project that uses DynamoDB and you’re looking for better performance, reduced costs and no vendor lock-in, it would make more sense to use the Alternator project. You can read more about the difference between these two APIs here.
Essentials Track
- In the Getting Started with ScyllaDB session, I covered basic topics such as an intro to ScyllaDB. Before diving into the theory I ran users through our Quick Wins lab which shows how easy and fast it is to start a ScyllaDB cluster and perform some basic queries. I also gave an overview of the design goals for ScyllaDB: High Availability, High Scalability, High Performance, Low Maintenance and being API-level compliant with Apache Cassandra and DynamoDB. Keep in mind that in ScyllaDB, high availability is given preference over consistency. I explained concepts such as Node, Keyspace, Consistency Level, Replication Factor, Token Ranges, Cluster, and more. I then moved on to talk about Data Modeling, the importance of primary key selection and what users should focus on when creating a data model in ScyllaDB (or Cassandra for that matter).
- Tzach Livyatan, ScyllaDB’s VP Product, talked about Advanced Data Modeling. Tzach continued where I left off and dove into choosing a partition key, using some examples. He then talked about Materialized Views and Secondary Indexes and when to use each. Next, Tzach talked about Counters. They are a Conflict-free Replicated Data Type (CRDT). Concurrent updates converge to a stable value. Counters support increment and decrement and are implemented as a set of triplets (node ID, vector clock, value). He also covered Sets, Lists, and Maps, giving an example of each type of collection. Then he talked about User-Defined Types (UDTs) and presented some code showing how they can be used. Tzach also discussed Time To Live (TTL) and how and when to use it. Finally, Tzach talked about Lightweight Transactions, when and how to use them.
- Avishai Ish Shalom, Developer Advocate, gave the last talk in the Essentials track, titled Building Well-Architected Apps in ScyllaDB Cloud. Avishai covered consistency in ScyllaDB and what happens when we have failed writes? What are the options for handling this? He then talked about different architecture patterns such as the read/write split, write dam, Harvest and Yield, before moving on to some examples.
Advanced Track
- Piotr Grabowski, Software Developer, talked about Working with Kafka and ScyllaDB. He started by giving an overview of Apache Kafka, an open-source distributed event streaming system, and presented a hands-on demo. It allows users to ingest data from a multitude of different systems, such as databases, services or other applications. It then can store the data for future reads, process and transform the incoming streams in real-time and allows downstream applications to consume the stored data stream. As an example of the latter Piotr went over the ScyllaDB Sink Connector which reads messages from a Kafka topic and inserts them into ScyllaDB. The connector supports different data formats (Avro, JSON). Piotr then covered the ScyllaDB CDC Source Connector, giving a quick overview of Change Data Capture (CDC) and how to use it.
- Lubos Kosco, Software Engineer, covered utilizing Spark and ScyllaDB together. Apache Spark is a unified analytics engine for large-scale data processing. It allows for writing data analytics applications quickly in Java, Scala, Python, R, and SQL. The ScyllaDB Spark Connector allows for integration between ScyllaDB and Spark. Lubos showed an example of using it to connect to ScyllaDB, perform queries and process data. Lastly Lubos talked about the ScyllaDB Migrator, showing an example of how to use it with a sample app.
- Amnon Heiman, Software Developer, gave a talk about Improving Applications Using ScyllaDB Monitoring, which is the goto tool for understanding what’s going on in your cluster. After an overview, Amnon covered common pitfalls and how they can be detected in the different monitoring dashboards, performance issues, alerts, and how to debug issues.
Attendee Poll Results
While attendees were learning about ScyllaDB, we wanted to learn about you. A few last observations we’d like to share from the event come from our attendee polls. Let’s look at the results.
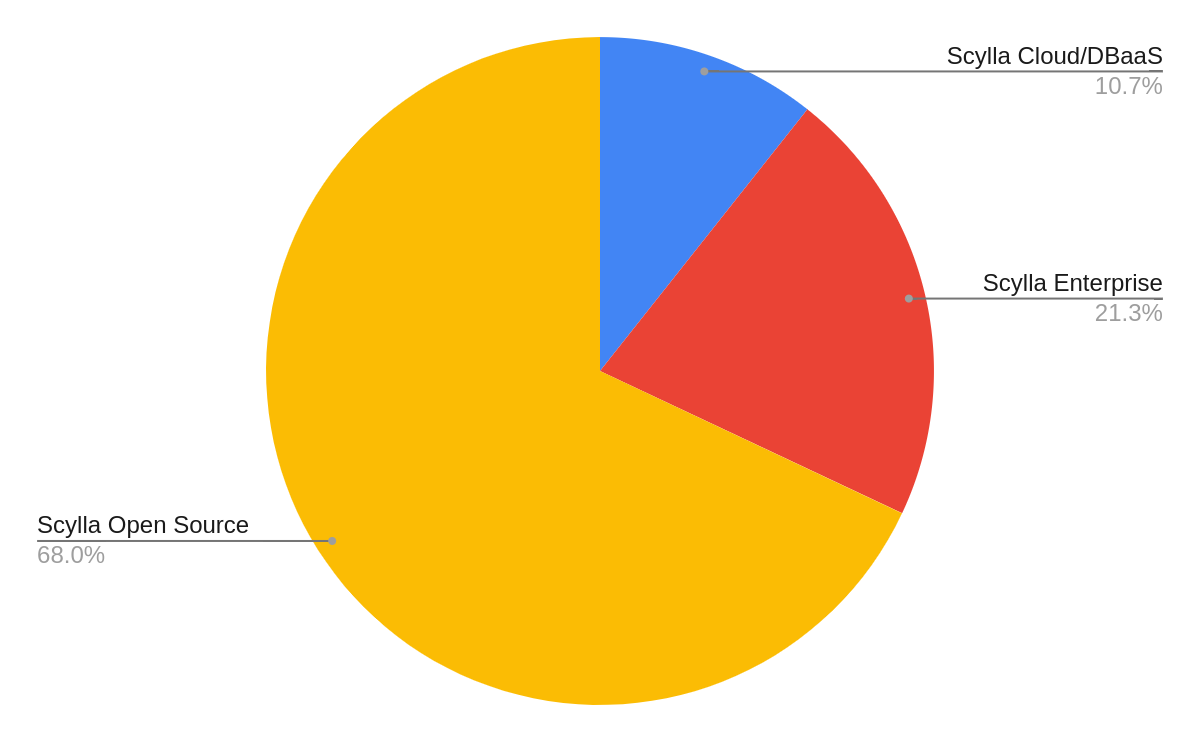
How are you interested in deploying ScyllaDB?
The vast majority of our attendees — over two thirds — were interested in deploying ScyllaDB Open Source. Of the remaining third, the ratio of users who want to run their own instances of ScyllaDB Enterprise outnumbered those who want a fully-managed DBaaS option by a factor of two-to-one.
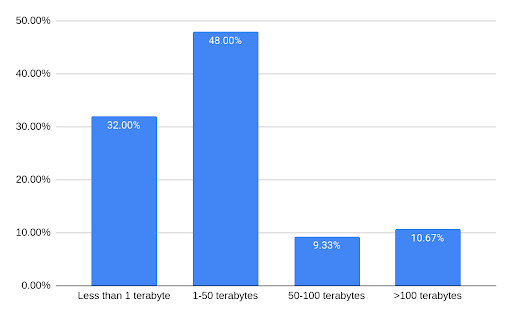 How much data do you have under management in your transactional database systems?
How much data do you have under management in your transactional database systems?
What’s interesting in terms of data size is that most attendees — nearly half — support workloads in the low-terabytes scale. Together with sub-terabyte workloads, that accounts for 80% of all attendees. However, about 20% are in the 50 terabyte or larger scale; about half of whom — one attendee in ten overall — are operating workloads with more than 100 terabytes of data under management.
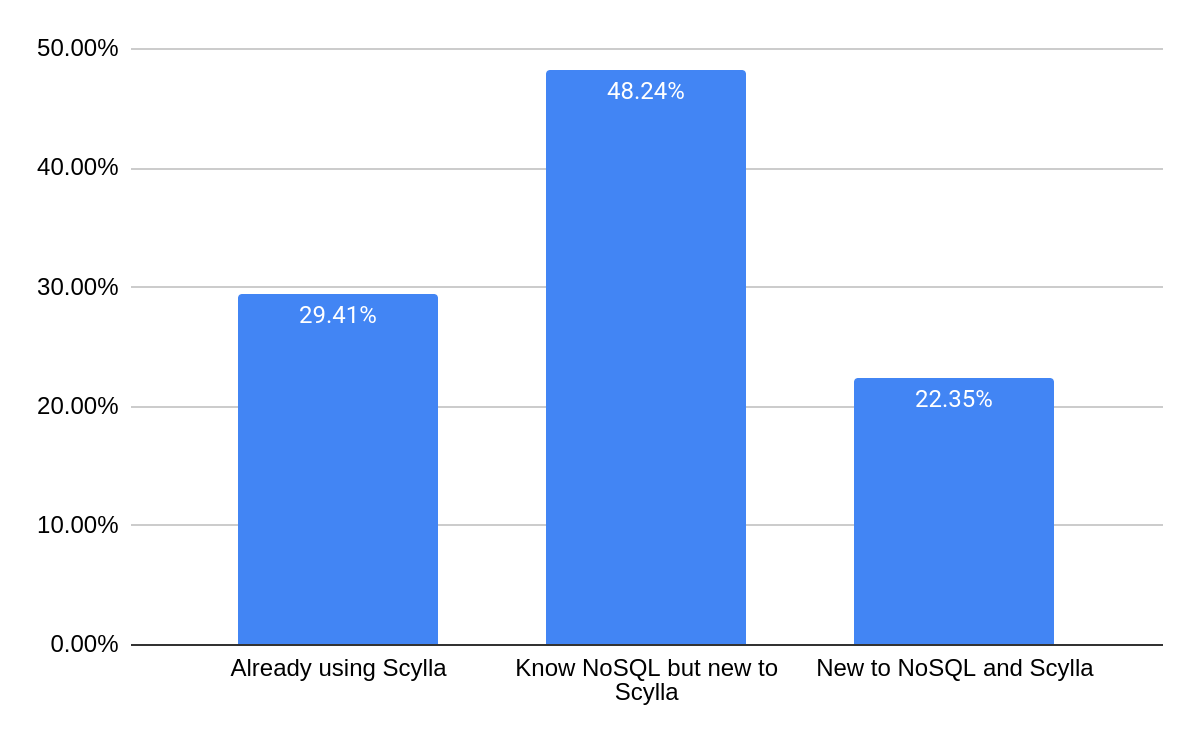
What is your level of experience with ScyllaDB?
As expected for an online training opportunity, the majority of attendees — about 70% — were new to ScyllaDB. About half of all attendees knew some sort of NoSQL; only for a fifth of attendees was this their very first experience with NoSQL. About 30% of our attendees are already using ScyllaDB, who sought to get even deeper insights.
Enroll in ScyllaDB University
Thank you to everyone who attended our ScyllaDB University LIVE Summer Session and made the event so great! If you didn’t have a chance to attend, never fear! Many of these courses are available right now in a free self-paced form in ScyllaDB University. Create an account and get started today!



