ScyllaDB Virtual Workshops are your chance to get to know more about how ScyllaDB’s NoSQL distributed database works, and how it might fit into your latest project plans. Each month, our expert solution architects look forward to interacting with database architects, developers, and managers in these interactive workshops.
Today we wanted to share with you some insights from running them over the past year, as well as answer some of your most recent questions. You can also learn more about the format of our Virtual Workshops and read some of the prior Q&A in this prior blog.
SAVE YOUR SEAT AT OUR NEXT VIRTUAL WORKSHOP
Insights from Prior Virtual Workshops
We poll attendees as to their expectations for their data-intensive projects. These results therefore represent hypothetical deployments; actual deployment numbers will differ. But it is still interesting to understand what scale and performance bounds Virtual Workshop attendees have for their potential NoSQL database projects.
Latency Expectations
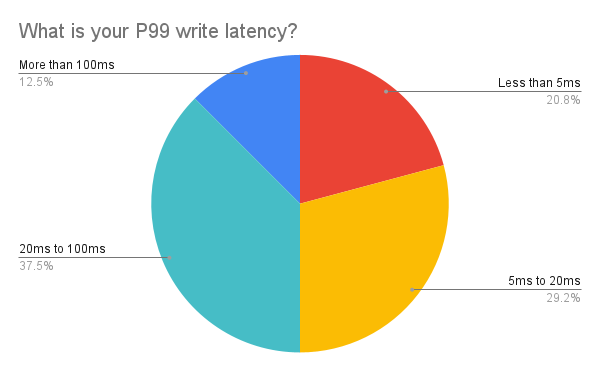
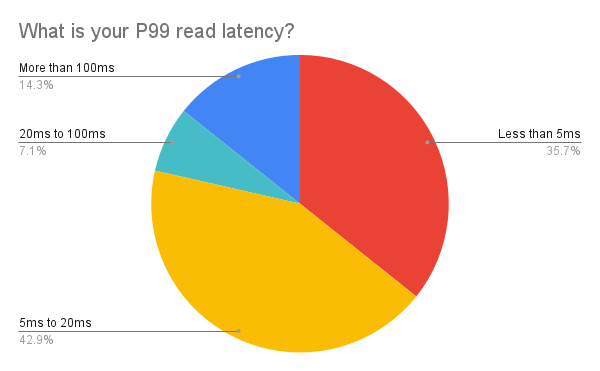
Our attendees have very different expectations as to how “fast” is fast in regards to read and write latencies for a NoSQL database. Rather than measure average latencies (P50), at ScyllaDB we tend to measure long tail latencies such as 99th percentiles (P99).
What’s more subtly interesting is there’s also differences amongst attendees as to read vs. write latencies. Only a fifth of Virtual Workshop attendees said they require P99 write latencies ≤5 ms. Instead, more attendees had higher expectations for fast reads — with over 35% wanting reads to be ≤5 ms. You can see that 50% of attendees would be satisfied with P99 writes of ≤20 ms, but over 78% wanted their read latencies to be ≤20 ms.
Data Volume Expectations
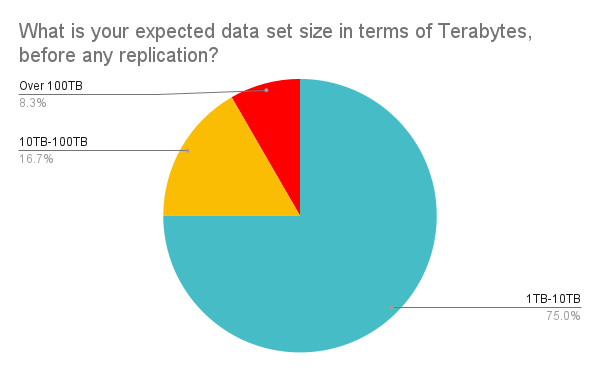
Most ScyllaDB use cases will begin somewhere in the terabyte scale of data — either immediately upon reaching production, or within the first year of operations. For the most part, 75% of virtual workshop attendees said that they would remain in the 1–10 terabyte range of unique data. But the last quarter said they would either run in the 10–100TB range (16% of all attendees), and the remainder (8%) at the top end would deploy systems storing over 100TB of unique data before replication.
Besides total unique data, we also asked attendees how large their expected payloads are. About a third (37%) said their typical payloads would span from 500 bytes to 5 KB. Nearly half (45%) said their payloads would be in the 5–50 KB range. And the remainder (16%) would use payloads of >50 KB. This shows the broad variety of payload sizes that ScyllaDB needs to support in production environments.
![]()
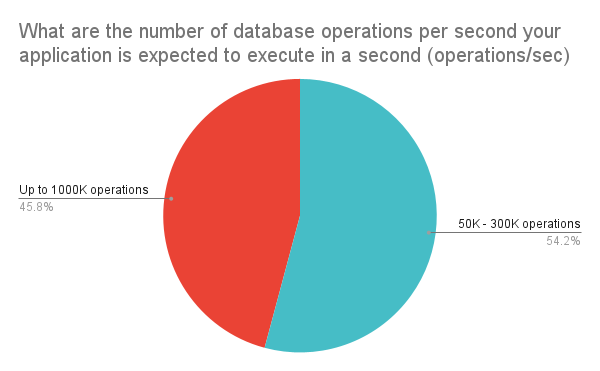
The next question was about throughput, measured in operations per second (OPS). Here the audience was split roughly evenly, with the majority (54%) looking to run between 50–300K OPS, while a significant minority (45%) would run up to a million OPS.
Target Deployments
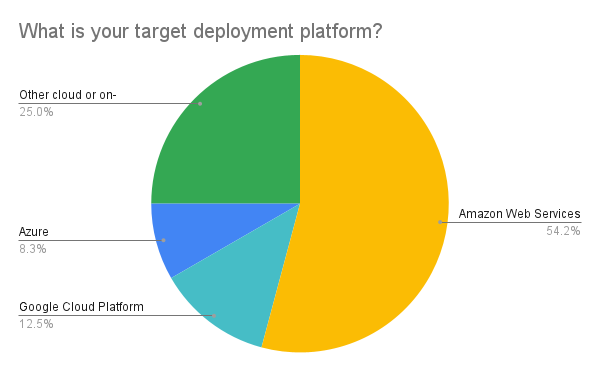
The majority of attendees planned to deploy to Amazon Web Services (AWS), with smaller numbers wanting to deploy to Google Cloud (12%) or Azure (8%). A quarter of respondents were interested in deploying to other cloud vendors or to an on-premises deployment.
Technical Depth
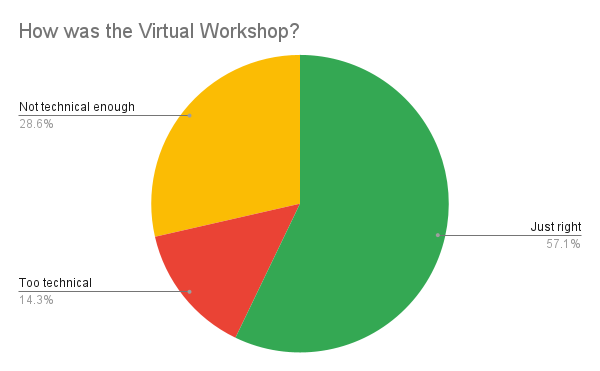
Virtual Workshops are open to everyone who wishes to attend. This spans from curious professionals who have not heard much about ScyllaDB before, to practitioners who have significant prior experience. So, as you can imagine, there’s a broad range of attendees who believe it was not technical enough (28%) and those who thought it was too technical (14%). But for the most part, the majority of attendees believe the technical depth is just right (57%) — the “Goldilocks” desired answer. For those who wish further technical depth, or those who want to start from the very basics, we recommend signing up for free online ScyllaDB University self-paced courses, or attend our ScyllaDB University LIVE training sessions.
Questions from Our Virtual Workshops
Q: Does ScyllaDB have any index approach for SELECT from different datacenters?
A: Yes. I presume your application is in one of those datacenters or both. For example, maybe you have a collection of microservices running on us-west. You are going to use the load balancing policy to tell ScyllaDB to fetch the data from us-west — for example, how to configure this for the Go driver here — unless you lose the entire datacenter. This is unlikely; but if it occurred, ScyllaDB would try to fetch data from us-east. Also, check out the 10th note in this blog.
Q: Do you support Kubernetes?
A: Yes! We have a Kubernetes operator. It’s called ScyllaDB Operator, and it’s on Github. Read all the documentation and take the ScyllaDB University course. It’s GA [General Availability] and tested on Google Cloud and AWS; the next target we’re looking at is Azure. There’s also #kubernetes and #scylla-operator channels on our user Slack.
Q: What is the minimum and recommended AWS EC2 instance type for ScyllaDB?
A: Every time we do sizing, the answer is “it depends.” The typical instance that we recommend when you deploy in AWS is either the I3 or I3en families of instances because those instances come with NVMe storage [read more here]. This does not mean that other instances are unable to fit your use case. What we typically need to know is your data set size, your latency requirements, the average payload size, among other information. Feel free to contact us for help with specific sizing for your use case. You can also try the ScyllaDB Cloud Sizing & Pricing Calculator.
Next Virtual Workshop
Have questions of your own? Feel free to join us for our next Virtual Workshop, which is scheduled for Thursday, 21 October 2021, at 10 AM Pacific Time, 1 PM Eastern Time, and 5 PM GMT.
SAVE YOUR SEAT AT OUR NEXT VIRTUAL WORKSHOP