





IMR stands for In Memory Representation and in the scope of this blog post we mean the in-memory representation of cells. You might be asking, why is this even something worth talking about? Why not just use the native data model provided by the programming language in use? The answer lies in the programming language in use: C++ is a strongly typed compiled language and as such it needs to know all properties of a type at compile time. Cells on the other hand have various fields depending on the state they are in and even depending on the schema — the CQL type of the value they store. To give the simplest example, while a live cell has a timestamp and a value, a dead cell only has a timestamp and a deletion time. To represent this in C++, one would need something like this:
struct simple_cell {
timestamp_type ts;
std::optional<deletion_time_type> deletion_time;
std::optional<value_type> value;
};This representation is wasteful, as some of the fields are only used in certain fields. While the amount of waste might be small, there might be millions of cells in memory and this adds up. Using a union or std::variant also doesn’t help, as those allocate space large enough for the largest of their member types.
Now that we established why an IMR is needed, let’s look at why we needed a new IMR infrastructure. Back in the times of old, ScyllaDB had a quite simple IMR format. A cell was a buffer. In the start of this buffer was a bitset, with some flags, from which the state of the cell could be determined. Each state had a specific field layout, storing only fields it needed. Once the state was known, fields could be accessed simply by adding up offsets. This was simple and it worked, but it had one major weakness: it required the buffer to be linearized. (You can read more about key linearization here, and the kinds of behavioral issues it can cause here.)
In ScyllaDB we break up large allocations into fragments of uniform size. This is mainly to reduce memory fragmentation and make the database more resilient. To solve this it would have been enough to just adapt this simple code to work with fragmented buffers. But we had more ambitious plans. If we were going to touch this, we wanted to change it into something that aligns better into our long-term goals: more widespread-usage (migrate more components like collections to also have an IMR format) and JIT compiling.
We wanted something that is not open-coded but generated by the compiler as much as possible, so we ended up with a template-metaprogramming heavy solution. This had the advantage of eliminating much of the boiler-plate of the open-coded solution, as well as allowing nice declarative code on the interface level. But, as it turned out in time, it had some significant disadvantages too: beyond the nice interface was code that proved to be so complicated that very few people could understand it and people started to avoid touching it. Thus it completely backfired in the more widespread adoption regard. Also, it had a horrible debugging experience.
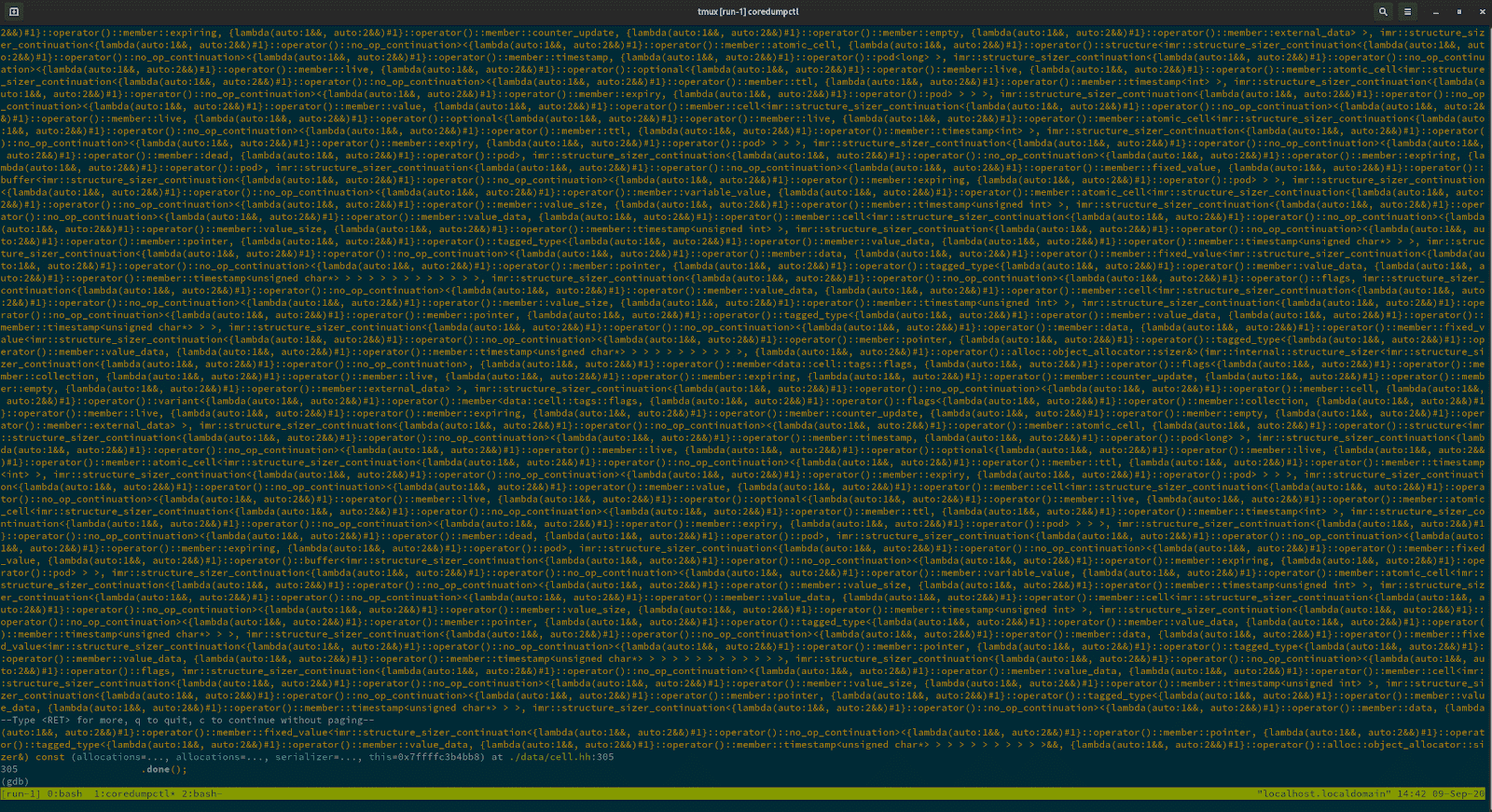
Figure 1: the name of a single function in IMR doesn’t fit into a single screen
For these reasons we decided that we want to go back to the old simpler days of an open-coded IMR format and the Hackathon seemed like the perfect opportunity for this experiment.
Implementation
First we tried refactoring the current IMR format to make it less template-heavy and hence easier to work with, but this proved futile. In the end we ended up effectively dropping the current format and reverting to the old open-coded one. This was not an easy task, as in the years since it was introduced, many improvements have accumulated on top of it. It kinda felt like trying to yank an entire level out of a Jenga tower without it crumbling entirely.

Figure 2: reverting a change from years ago
We also didn’t want to regress in regard to buffer fragmentation, so we had come up with a way to make this work with fragmented buffers, without losing the simplicity of it.
We ended up using a widely used abstraction in C++: iterators. We wrote an iterator for our fragmented buffer type that hides the fragmentation and creates the illusion of contiguity (without promising it). This iterator works well with C++ standard functions like std::copy_n() that we use heavily to extract values from buffers. The drawback is that this iterator is a fat iterator. As the compiler cannot prove that the underlying storage is contiguous it can’t optimize such copies away into simple memcpy() equivalents (or, when the size is known in advance, into single mov instructions). To solve this problem we came up with a function which would double compile our iterator using code:
auto with_iterator_pair(auto&& func) {
if (is_fragmented()) {
return func(slow_begin(), slow_end());
}
else {
return func(single_fragment_begin(), single_fragment_end());
}
}This allows those buffers that are small enough to fit into a single fragment (most cells are small enough to fit) to use good old pointers as iterators that are lightning fast, and only fall back to the slower fat iterator for the larger buffers (that are rare).
Next Steps
Obviously a three day hackathon was not enough to get this into a mergeable state. But it was enough for a POC that proves that it can be done. Now only the hardest part remains: polishing and testing. Once done this opens the door for migrating more components to this IMR format. One example is collections. These currently use a serialization format that requires full deserialization for each access and a further serialization pass for each modification. Another example is counters, which also has its own serialization format and requires deserialization for reads.
If you want to learn more about what is going on behind the scenes at ScyllaDB, you’re invited to attend ScyllaDB Summit 2021, this coming January 12th – 14th. It will have two days of technical talks. You can hear directly from many of our engineers, who will present what they’ve been working on this past year, as well as sessions from your industry peers. Plus there’s a free day of training for both app developers as well as DBAs/DevOps.

