
NoSQL practitioners from across the globe gathered this past Friday, 14 September 2018, in San Francisco for the latest Distributed Data Summit (#dds18). The attendees were as distributed as the data they manage, from the UK to Japan and all points between. While the event began years ago as a purely Apache Cassandra Summit, it currently bills itself as appealing to users of Apache Cassandra “and Friends.” The folks at ScyllaDB are definitely among those friends!

Spinning up for the event
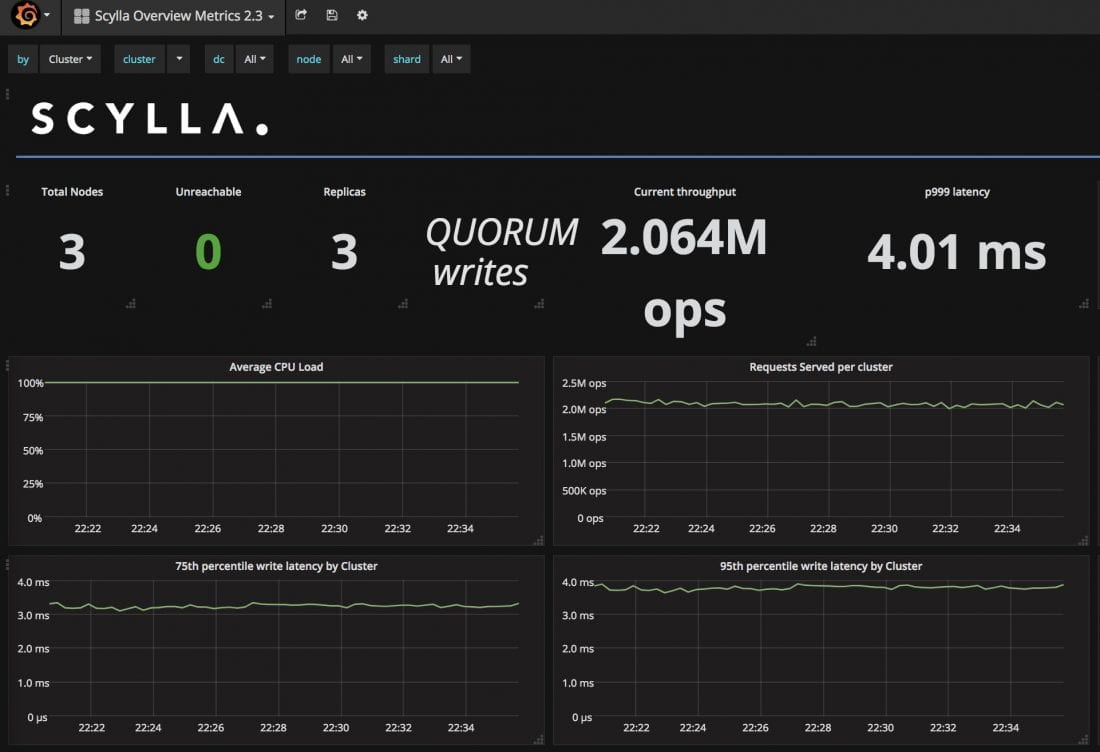
Our team’s own efforts kicked off the night before with spinning up a 3-node cluster to show off ScyllaDB’s performance for the show: two million IOPS with 4 ms latency at the 99.9% level. (And note the Average CPU Load pegged at 100%.)
A Hot Keynote
The keynote to the event was delivered by Nate McCall (@zznate), current Apache Cassandra Project Management Committee (PMC) Chair. He laid out the current state of Cassandra 4.0, including updates on its offerings, including Transient Replicas (14404) and Zero Copy Streaming (14556).

Nate acknowledged his own frustrations with Cassandra. For example, the “tick-tock” release model adopted in 2015, named after the practice originally promulgated by Intel. With a slide titled “Tick Toc Legacy: Bad,” Nate was pretty blunt, “I have to sacrifice a chicken [to get git to work].” Since Intel itself moved away from “tick-tock” in 2016, and the Cassandra community decided in 2017 to end tick-tock (coinciding with 3.10) in favor of 6-month release schedules, this is simply a legacy issue, but a painful one.
He also took a rather strident stance on Materialized Views, a feature Nate believes is not-quite-there-yet: “If you have them, take them out.”
When he mentioned the final nails in the coffin for Thrift (deprecated in favor of CQL), a hearty round of applause rose from the audience. Though, as an aside, ScyllaDB will continue to support Thrift for legacy applications.
Nate also highlighted a number of sidecar proposals being made, such as The Last Pickle’s Cassandra Reaper for repairs, plus the Netflix and Datastax proposals.
Besides the specific technical updates, Nate also addressed maturity lifecycle issues that are starting to crop up in Cassandra. For the most part, he praised Cassandra staying close to its open source roots: “The features that are coming out are for users, by users… The marketing team is not involved.” But like Hadoop before it (which was split between Cloudera, Hortonworks and MapR), Cassandra is now witnessing increased divergence emerging between commercial vendors and code committers (such as DataStax and ScyllaDB).
Yahoo! Japan
The ScyllaDB team also had a chance to meet our friends Shogo Hoshii and Murukesh Mohanan. They presented on Cassandra and ScyllaDB at Yahoo! Japan, focusing on the evaluation they performed for exceedingly heavy traffic generated by their pre-existing Cassandra network of 1,700 nodes. Yahoo! Japan is no stranger to NoSQL technology, forming their NoSQL team in 2012. We hope to bring you more of their analyses and results in the future. For now, we’ll leave you with this one teaser slide Dor took during their presentation.

Was Cassandra the Right Base for ScyllaDB?
ScyllaDB CEO Dor Laor asked this fundamental question for his session. If we knew then what we know now, four years ago, would we have still started with Cassandra as a base?
While ScyllaDB mimics the best of Cassandra, it was engineered in C++ to avoid some of the worst of its pitfalls, such as JVM Garbage Collection, making it quite different under the hood.
Dor observed first “what worked well for us?” Particularly, inheriting such items as CQL, drivers, and the whole Cassandra ecosystem (Spark, KairosDB, JanusGraph, Presto, Kafka). Also, Cassandra’s “scale-out” capabilities, high availability and cross-datacenter replication. Backup and restore had reasonable solutions. (Though it is particularly nice to see people write ScyllaDB-specific backup tools like Helpshift’s ScyllaDBbackup.) Cassandra also has a rich data model, with key-value and wide rows. There was so much there with Cassandra. “Even hinted handoffs.” And, not to be left out of the equation, tools like Prometheus and Grafana.
On the other hand, there was a lot that wasn’t so great. Nodetool and JMX do not make a great API. The whole current sidecar debate lays bare that there was no built-in management console or strategy. Configurations based on IP are problematic. Dor’s opinion is that they should have been based on DNS instead. Secondary indexes in Cassandra are local and do not scale. “We fixed it” for ScyllaDB, Dor noted.
Since 2014, a lot has changed in the NoSQL world. Dor cited a number of examples, from CosmosDB, which is multi-model and fully multi-tenant, to Dynamo’s point-in-time backups and streams, to CockroachDB’s ACID guarantees and SQL interface. Some of those features are definitely compelling. But would they have been a better place to start from?
So Dor took the audience on a step-by-step review of the criteria and requirements for what the founding team at ScyllaDB considered when choosing a baseline database.


Fundamental reliability, performance, and the ecosystem were givens for Cassandra. So those became quick checkboxes.
Dor instead focused on the next few bullets. Operational management could be better. Had it been part of Cassandra’s baseline, it would have obviated the need for sidecars.
For data and consistency, Dor cited Baidu’s use of CockroachDB for management of terabytes of data with 50 million inserts daily. But while that sounds impressive, a quick bit of math reveals that only equates to 578 operations per second.
While SSTables 3.0 provide a significant storage savings compared to 2.0, where Cassandra needs to improve in terms of storage and efficiency is to adopt a tiered-storage model (hot vs. cold storage).
“Cloud-native” is a term for which a specific definition is still quite arguable, especially when it comes to databases. Though there have been a few good takes at the topic, the term itself can still mean different things to different people, never mind the implementations. For instance, Dor brought up the example of what might happen if a split-brain divides the database and your Kubernetes (“k8s”) differently. Dor argued that ScyllaDB/Cassandra’s topology awareness is better than Kubernetes, but the fact that they are different at all means there needs to be a reconciliation to heal the split-brain.
With regards to multi-tenancy, Dor saw the main problem here as one of idle resources, exacerbated by cloud vendors all-too-happy to over-provision. The opportunity here is to encapsulate workloads and keyspaces per tenant, and to provide full isolation, including system resources (CPU, memory, disk, network), security, and so on — without over-provisioning, and also while handling hot partitions well. It would require a single cluster for multiple tenants, consolidating all idle resources. Ideally, such a multi-tenant cluster would permit scale-outs in a millisecond. Dor also emphasized that there is a great need to define better SLAs that focus on real customer workloads and multi-tenancy needs.
So was Cassandra the right baseline to work from? Those who attended definitely got Dor’s opinion. But if you couldn’t attend, don’t worry! We plan on publishing an article delving into far more depth on this topic in the near future.

Thread per Core
ScyllaDB CTO Avi Kivity flew in from Israel to present on ScyllaDB’s thread-per-core architecture.
The background to his talk was the industry momentum towards ever-increasing core counts. Utilizing these high core count machines is getting increasingly more difficult. Lock contention. Optimizing for NUMA and NUCA. Asymmetric architectures, which can lead to over- or under-utilization extremes.
Yet there are compelling reasons to deal with such difficulties to achieve significant advantages. Lowered mean time between failures (MTBFs) and reduced management burdens by dealing with orders of magnitude fewer machines. The use of far less space in your rack. Less switch ports. And, of course, a reduction in overall costs.
So, Avi asked, “How do you get the most from a large fat node?” Besides system architecture, there are also considerations within the core itself. “What is the right number of threads” to run on a single core? If you run too few, you can end up with underutilization. If you run too many, you run into the inverse problems of thrashing, lock contention and high latencies.
The natural fit for this issue is a thread-per-core approach. Data has traditionally been partitioned across nodes. This simply drills the model down to a per-core basis. It avoids all locking and kernel scheduling. And it scales up linearly. However, if you say “no kernel scheduling,” you have to take on all scheduling yourself. And everything has to be asynchronous.
In fact, each thread has to be able to perform all tasks. Reads. Writes. Compactions. Repairs. And all administrative functions. The thread also has to be responsible for balancing CPU utilization across these tasks, based on policies, and with sufficient granularity. Thus, the thread has to be able to preempt any and every task. And, finally, threads have to work on separate data to avoid any locking—a true “shared-nothing” architecture.
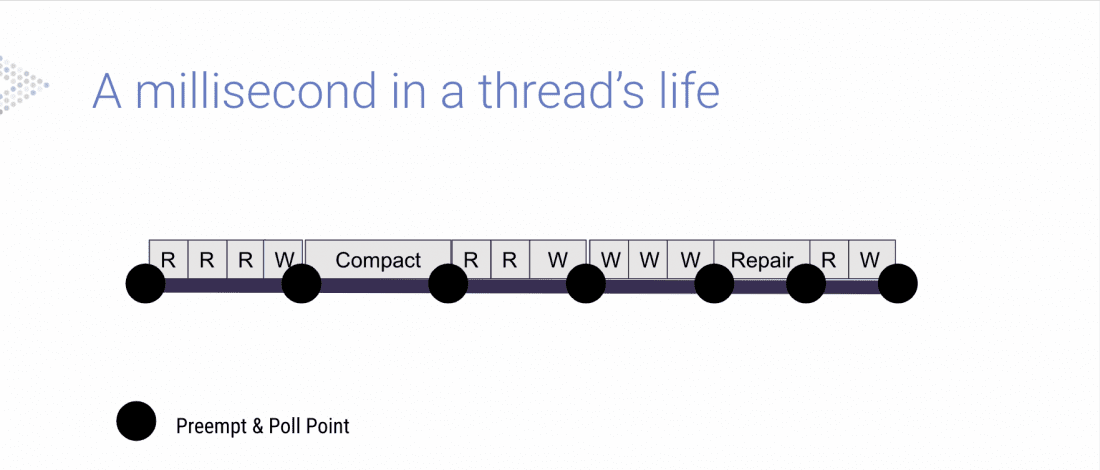
Avi took us on a tour of a millisecond in a thread’s life. “We maintain queues of tasks we want to run.” This “gives us complete control of what we want to run next.” You’ll notice the thread maintains preemption and poll points, to occasionally change its behavior. Every computation must be preemptable at sub-millisecond resolution.
Whether you were in the middle of SSTable reads or writes, compactions, intranode partitioning, replicating data or metadata or mutating your mutable data structures, “Still you must be able to stop at any point and turn over the CPU.”
Being able to implement this low-level thread-per-core architecture brought significant advantages to ScyllaDB. In one use case, it allowed the contraction from 120 Cassandra i3.2xl nodes to just three (3) i3.16xl nodes for ScyllaDB. Such a reduction in nodes maintained the exact same number of cores, yet required significantly lower administrative overhead.
OLTP or Analytics? Why not Both?
In a second talk, Avi asked the question that has been plaguing the data community for years.
Can databases support parallel workloads with conflicting demands? OLTP workloads asks for the fastest response time, high cache utilization, and has a random access pattern. OLAP on the other hand has a batchy nature, latency is less important while throughput and efficient processing is paramount. The workload can scan large amount of data and access them once, thus the data shouldn’t be cached.
As Chad Jones of Deep Information Sciences quipped at his Percona Live 2016 keynote, “Databases can’t walk and chew gum at the same time.” He observed you can optimize databases for reads, or writes, but not both. At least, that was his view in 2016.
So how do you get a single system to provide both Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP)? Avi noted that workloads can compete with each other. Writes, reads, batch workloads, and even internal maintenance tasks like compactions or repairs can all dominate a system if left to their own devices.
Prior practices with Cassandra have focused on throttling, configuring maximum throughput. But this has often been a manual tuning effort, which could leave systems idle at certain points, while being unable to shift system resources during peak activities.
Finally, after years of investment in foreground and background workload isolation ScyllaDB is able to provide different SLA guarantee for the end-user workloads.
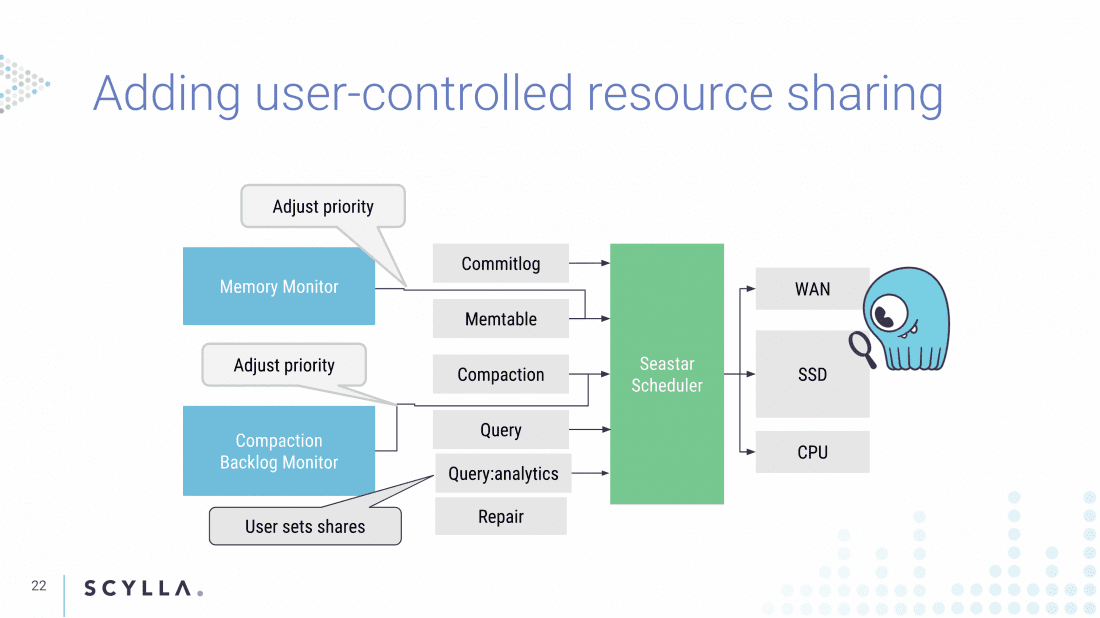
Avi took the audience through the low-level methods ScyllaDB, built on the Seastar scheduler, can allow users to create new scheduling classes, and thus assign relative resource shares. For example, imagine a role defined as follows:
CREATE ROLE analytics
WITH LOGIN = true
AND SERVICE_LEVEL = { ‘shares’: 200 };
This would create an analytics role that would be constrained to a share of system resources. Note that the rule limits the analytics role to portion of the resources, however, this is not a hard cap. In case there are enough idle resources the analytics workload can go beyond its share and thus get the best of all worlds — utilization for OLAP and low latency for OLTP.
Avi then shared the results of two experiments, creating an oltp and analytics user to simulate performance under different scenarios. In the second more-realistic scenario, Avi outlined setting a latency-sensitive online workload that would consume 50% of CPU, versus a batch load with three times the thread count that would try to achieve as much throughput as it could get.
The results of his experiments were promising, the oltp workload continued to perform exactly as before, despite the 3X competing workload from analytics.
Having a single datacenter that handles operational and Spark (analytics) workload is a huge advance by ScyllaDB. There is no more need to reserve an entire datacenter together with 1x-3x data duplication for Spark. If you want to hear more about this novel ability, we will be covering it at the ScyllaDB Summit in November.
Looking Towards an Official Cassandra Sidecar, Netflix
Focusing on Cassandra itself, there were a number of very interesting talks. One in particular by the team at Netflix on “Looking towards an Official C* Sidecar.” They’ve kindly shared their slides after the event. Netflix is no stranger to sidecars, being the home of Priam (first committed to github in 2011), as well as sidecars for other services like Raigad for Elasticsearch and Prana. We at ScyllaDB have our own vision on a ScyllaDB sidecar, in the form of ScyllaDB Manager, but it is vital to hear the views of major stakeholders in the Cassandra community like Netflix. If you didn’t attend DDS18, this is definitely a talk to check out! See You at ScyllaDB Summit! It was great to meet so many of you at Distributed Data Summit. Let’s keep those conversations going. We’re looking forward to seeing you at our own event coming up in November, ScyllaDB Summit 2018. There will be hands-on training plus in-depth talks on a wide range of technical subjects, practical use cases, and lessons-learned by some of the industry’s leading practitioners. Don’t delay! Register today!



