The data model in ScyllaDB and Apache Cassandra partitions data between cluster nodes using a partition key, which is defined by the database schema. Using a partition key provides an efficient way to look up rows using the partition key because you can find the node that owns the row by hashing the partition key. Unfortunately, this also means that finding a row using a non-partition key requires a full table scan which is inefficient. Secondary Indexes are a mechanism in Apache Cassandra that allows efficient searches on non-partition keys by creating an index.
In this blog post you will learn:
- How Apache Cassandra implements Secondary Indexes using local indexing
- Why we decided to take a different implementation strategy for ScyllaDB using global indexing
- How global indexing affects how you should use Secondary Indexing
- How to create your own Secondary Indexes and use them in your application CQL queries
Background
The size of an index is proportional to the size of the indexed data. As data in ScyllaDB and Apache Cassandra is distributed to multiple nodes, it’s impractical to store the whole index on a single node. Apache Cassandra implements Secondary Indexes as local indexes, which means that the index is stored on the same node as the data that’s being indexed from that node. The benefit of a local index is that writes are very fast, but the downside is that reads have to potentially query every node to find the index to perform a lookup on, which makes local indexes unscalable to large clusters. In addition to the native secondary indexes, Apache Cassandra also has another local indexing scheme, SSTable Attached Secondary Index (SASI), which supports complex queries and search. However, from a scalability point of view, it has exactly the same characteristics as the original Secondary Indexes.
Materialized views in ScyllaDB and Apache Cassandra are a mechanism to automatically denormalize data from a base table to a view table using a different partition key. This solves the scalability issue of local indexes but comes at a storage cost because you need to duplicate the whole table in the worst case. Materialized Views are therefore not a replacement for Secondary Indexes for all use cases. However, Materialized Views provide the necessary infrastructure to implement Secondary Indexes using global indexing, which is the implementation approach taken for ScyllaDB.
Global Indexing
ScyllaDB takes a different approach than Apache Cassandra and implements Secondary Indexes using global indexing. With global indexing, a Materialized View is created for each index. The Materialized View has the indexed column as the partition key and primary key (partition key and clustering keys) of the indexed row as clustering keys. ScyllaDB breaks indexed queries into two parts: (1) a query on the index table to retrieve partition keys for the indexed table and (2) a query to the indexed table using the retrieved partition keys. The benefit of this approach is that we can use the value of the indexed column to find the corresponding index table row in the cluster so reads are scalable. The downside of the approach is that writes are slower than with local indexing because of all the overhead from keeping the index view up-to-date.
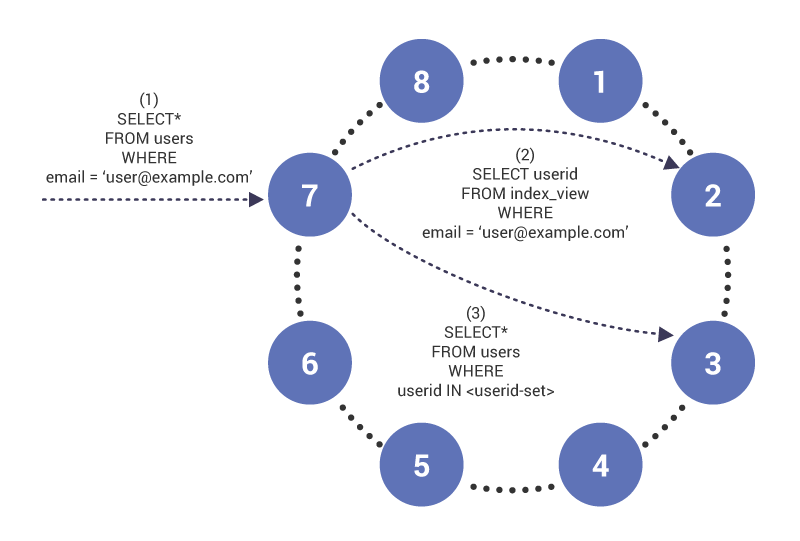
Querying on an indexed column proceeds as follows. In phase (1), the query arrives on node 7, which acts as a coordinator for the query. The node notices that we’re querying on an indexed column and therefore in phase (2), issues a read to index table on node 2, which has the index table row for “[email protected]”. The query returns a set of user IDs that are used in phase (3) to retrieve contents of the indexed table.
When to use Secondary Indexes?
Secondary Indexes are (mostly) transparent to the application. Queries have access to all the columns in the table and you can add and remove indexes without changing the application. Secondary Indexes can also have less storage overhead than Materialized Views because Secondary Indexes only need to duplicate the indexed column and primary key, not the queried columns like with a Materialized View. Furthermore, for the same reason, updates can be more efficient with Secondary Indexes because only changes to the primary key and indexed column cause an update in the index view. In the case of a Materialized View, an update to any of the columns that appear in the view requires the backing view to be updated.
As always, the decision whether to use Secondary Indexes or Materialized Views really depends on the requirements of your application. If you need maximum performance and are likely to query a specific set of columns, you should use Materialized Views. However, if the application needs to query different sets of columns, Secondary Indexes are a better choice because they can be added and removed with less storage overhead depending on application needs.
Want to learn more about Secondary Indexes? Check out my presentation from ScyllaDB Summit 2017 on SlideShare. If you want to try out this feature, it is expected to be in the upcoming ScyllaDB 2.2 release.