



NoSQL Storage Types FAQs
What are NoSQL Storage Types?
What is NoSQL Storage?
While there isn’t a strict set of features common to all NoSQL databases, they typically share certain characteristics:
- Schema flexibility. NoSQL databases allow for dynamic, flexible, non-relational data models, accommodating unstructured data and semi-structured data without a predefined schema. This is particularly useful within the dynamic agile development environment.
- Scalability and distributed architecture. They are designed to scale horizontally, enabling them to handle large amounts of data by adding more servers to the database cluster. Many are distributed across multiple nodes, enhancing fault tolerance and availability.
- High performance. NoSQL databases often prioritize more efficient data retrieval and processing.
How do different NoSQL storage types work?
The various NoSQL storage types tackle challenges that arise with agile development pipelines, many connected apps and devices, more online users, and massive amounts of big data. Yet they present issues of their own related to query mechanisms and the richness of results.
ACID guarantees—atomicity, consistency, isolation, and durability—are typically associated with traditional SQL or relational databases. They ensure that database transactions are processed reliably and consistently even in the face of failures.
NoSQL databases often relax certain ACID properties to achieve better scalability and performance. Most NoSQL storage types sacrifice full consistency for improved availability and partition tolerance.
As the CAP theorem explains, it is impossible to simultaneously guarantee availability and consistency of data across all nodes in a distributed system while also achieving partition tolerance. Instead, many NoSQL databases embrace eventual consistency.
Network latency and partitioning issues in these environments challenge the achievement of immediate consistency across all nodes, so these databases prioritize availability and partition tolerance instead.
Different NoSQL storage types can often be classified based on which CAP theorem trade-offs they prioritize: consistency and partition tolerance, consistency and availability, or availability and partition tolerance.
How do NoSQL databases compare to SQL and other databases?
SQL databases are rigid, vertically scalable, and optimized for specific queries. NoSQL databases are preferable for applications with dynamic data and evolving requirements.
NoSQL databases differ from hierarchical databases by supporting a wide range of data models such as document-oriented, key-value, and column-family databases for many use cases.
Object-oriented databases represent data as objects with attributes and methods. In contrast, the many NoSQL storage types use different data models that offer a wide range of options for representing data.
What are NoSQL Storage Types? How Many are There?
The flexible schema of the NoSQL database allows users to store almost any kind of data. The more salient question is whether using a NoSQL database management system lends advantages for storing and querying the type of data the user has.
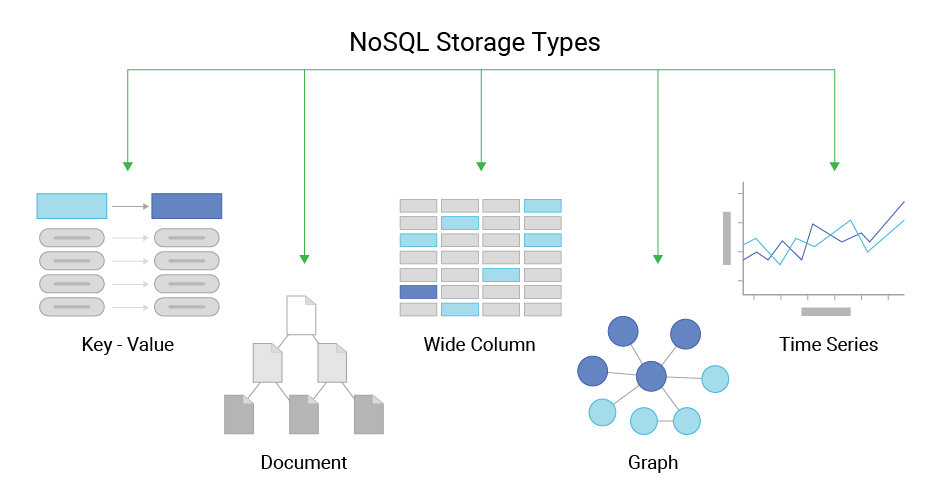
There are a few basic types of NoSQL databases:
- key value stores
- document stores
- column-oriented stores
- graph databases
- time series databases
NoSQL databases vary in their features, use cases, and underlying data models. Each type stores information in its own way and has unique features to be aware of.
Key-value pair databases
- Key-value pair databases store data in a simple data model with each piece of information stored as a key-value pair
- High-performance read operations suitable for applications that need to store and retrieve data, optimized for quick access
- Often designed for horizontal scalability, distributing data across multiple nodes allows them to handle large datasets and increasing loads by adding more servers.
Document stores
- In document databases data is stored as JSON-like documents, allowing for nested structures and flexibility in representing complex data models
- Document stores provide rich querying capabilities, allowing for complex queries and indexing of fields within documents
- These can also scale horizontally, distributing data across multiple nodes
Column-oriented databases
- While other databases store data in rows or rows and columns, column-oriented databases store data in columns only, with each containing data for a specific attribute across all rows
- Column-specific compression techniques reduce storage space and improve query performance
- Support for aggregations and analytical queries allow quick access and processing of specific columns of data
- Storing only columns with actual data values ensures efficient management of sparse data
Graph databases
- Graph databases store data using a graph data model, consisting of nodes (entities), edges (relationships between entities), and properties (additional information about nodes and edges)
- Enables efficient traversal of relationships without complex join operations
- Graph databases often come with a specialized query language to facilitate relationship traversal
- Relationships are stored between connected nodes, further speeding traversal
Time series databases
- Time series databases organize and store data chronologically in a compressed format to optimize storage efficiency, associating each data point with a timestamp
- Commonly used time series data structures include arrays or tables indexed by time
NoSQL Storage Types Advantages and Disadvantages
To make the best choice, know the different NoSQL storage types advantages and disadvantages:
Key-value pair databases
Advantages:
- Speed. Key value stores excel in read and write operations, retrieving data based on specific keys
- Simplicity. Key value stores are easy to implement and maintain
Disadvantages:
- Limited query capabilities. Complex queries involving multiple criteria or relationships may be challenging to perform efficiently.
- Data relationships. Modeling relationships between data may require additional effort or involve denormalization, which may limit applications with complex data interdependencies.
Document stores
Advantages:
- Flexible data modeling. Nested and hierarchical data stored suits document databases for applications with diverse and evolving data models.
- Querying power. Document stores offer powerful data querying, retrieval, and analysis capabilities.
- Schema evolution. The data structure and schema can evolve and be accommodated without affecting the entire database.
Disadvantages:
- Storage overhead. Document stores incur storage overhead due to denormalized data. Storing redundant information within documents might improve query performance.
- Complexity in joins. Although these handle nested data well, performing complex joins across multiple documents may demand additional considerations.
Column-oriented stores
Advantages:
- Analytical processing. Column-oriented databases excel in analytical processing, especially for queries that involve aggregations and reporting.
- Compression efficiency. Storing data in columns allows for effective compression, reduced storage requirements, and improved query speed.
- Parallel processing. Analytical queries often involve scanning and processing large subsets of columns.
Disadvantages of include:
- Transactional performance. Column-oriented databases may not perform as well for transactional workloads that involve frequent insert, update, or delete operations.
- Efficiency. Retrieving specific rows (point queries) may be less efficient in column-oriented databases compared to data stored in models organized by rows alone or rows and columns.
Graph databases
Advantages:
- Relationship modeling. Graph databases are well-suited for applications that rely on understanding and querying relationships between entities like social networks or recommendation engines
- Query efficiency. Graph databases excel in querying and traversing complex relationships, making them efficient for relationship-centric tasks
Disadvantages:
- Scaling. Graph databases face challenges with very large datasets
- Not used in many contexts. Graph databases may not be ideal where relationships between entities are not the primary focus of queries.
Time series databases
Advantages:
- Efficient time-based queries. Time series databases excel in quickly retrieving and analyzing data based on time
- Storage optimization. Designed to optimize storage and query performance based on time
Disadvantages:
- Specialized use. Time series databases are specialized for time-related data and may not be as efficient for other queries, complex relationships between data points, or applications with diverse data models.
Use Cases for Different NoSQL Storage Types
Key value stores. These are best suited for scenarios where fast query performance against individual pieces of data is more critical than complex querying. For example, key-value stores are used in shopping carts, caching, quickly retrieving sensor data in IoT applications, real-time analytics, session storage, configuration management, and gaming sites with leaderboards.
Document stores. These are well-suited for applications that require flexibility in data modeling and support for complex queries, making them a popular choice for content management systems (CMS), real-time analytics, and storing and querying data from Internet of Things devices. They are also used for e-commerce applications such as managing product catalogs, customer information/user profiles, product reviews, and order data with varying attributes
Column-oriented databases. These are optimized for analytical workloads, making them a frequent choice in data warehousing and similar business intelligence environments that require efficient querying and analysis of large volumes of data. Column-oriented databases also support efficient data retrieval for data mining and online analytical processing (OLAP) applications. These typically involve complex queries, log analysis, and aggregations—often leveraging column-oriented databases.
Graph databases. Relationships and connections between entities are at the core of data queries in these, suiting them particularly well for applications that involve complex network structures and dependencies such as social networks, recommendation systems, knowledge graphs, route optimization tools, and real-time analytics.
Time series databases. These are specifically designed to handle temporal data, suiting them well for applications that involve analyzing, tracking, and querying time-ordered data points from IoT sensor logs, server and application logs, energy and monitoring logs, and other sources.
How Do Different NoSQL Storage Types Handle Consistency?
Different types of NoSQL databases make different design choices regarding consistency based on their specific use cases and data models:
Key-value stores often prioritize high availability and partition tolerance over strong consistency. They may opt for an eventually consistent model.
Document stores, like MongoDB or Couchbase, may offer developers a choice in tunable consistency between strong consistency, eventual consistency, or a level in between based on their application requirements.
Column-oriented stores such as ScyllaDB and Apache Cassandra often deliver tunable consistency levels so developers can choose between strong consistency and eventual consistency.
Graph databases such as Neo4j vary in their consistency models. Some offer strong consistency for transactions involving graph structures, while others may prioritize availability and partition tolerance in distributed settings.
Time-series databases are designed to prioritize availability and partition tolerance to efficiently manage time-ordered data.
What types of NoSQL Storage Types Does ScyllaDB Support?
ScyllaDB is a wide-column NoSQL database designed for data-intensive applications that require low latency and high throughput. ScyllaDB is fully compatible with Apache Cassandra and Amazon DynamoDB and can serve as the storage layer for graph databases like JanusGraph.
ScyllaDB offers a shared-nothing, highly asynchronous, shard-per-core design that eliminates barriers to scale as data grows. Unlike legacy NoSQL databases that are effectively insulated from the underlying hardware, ScyllaDB capitalizes on processor, memory, network, and storage innovation to maximize performance and use less infrastructure.
Ultimately, this results in less admin and lower total cost of ownership. For instance, Comcast went from 962 Apache Cassandra nodes to only 78 ScyllaDB nodes. This efficiency results in anywhere from 2x to 10x cost savings over prior solutions.
Learn more about how ScyllaDB is unique among other NoSQL storage types and options.