



DynamoDB Throttling FAQs
How does DynamoDB throttling work?
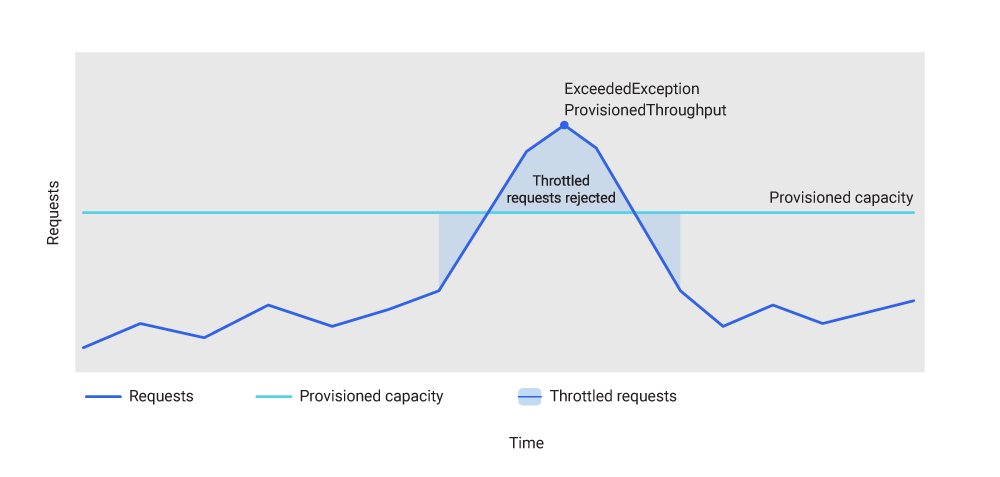
DynamoDB throttling is enforced using a token bucket algorithm applied at the partition level. Each partition holds a bucket of tokens representing available read and write capacity. Each request consumes tokens proportional to the number of RCUs or WCUs required. When a partition’s token bucket runs dry, new requests are rejected with a ProvisionedThroughputExceededException. In provisioned mode, AWS DynamoDB throttling begins at the partition level before the table-level limit is reached if access is uneven. In on-demand mode, DynamoDB on demand throttling begins when traffic spikes exceed 2x the previous peak.
What are DynamoDB throttling limitations?
DynamoDB throttling introduces several compounding operational burdens: partition-level hot spots that require partition key restructuring to resolve, DynamoDB throttling errors that must be handled in application code with carefully tuned retry logic, DynamoDB Global Secondary Index (GSI) throttling that operates independently for each global secondary index, DynamoDB throttling on demand behavior that surprises teams during traffic spikes, and unpredictable cost exposure when DynamoDB throttled exceed capacity thresholds force teams to switch between provisioned and on-demand modes in the long run.
How does DynamoDB throttling compare to ScyllaDB?
ScyllaDB does not use a provisioned capacity unit model and does not have anything like DynamoDB’s throttling mechanism. ScyllaDB does not impose hard limits on querying hot partitions. Instead, it routes each request directly to the CPU shard that owns the relevant data; here, throughput is bounded by hardware rather than configured quotas. Teams migrating from DynamoDB to ScyllaDB eliminate the DynamoDB throttle incidents that characterized their DynamoDB operations.
In DynamoDB vs ScyllaDB benchmarks, DynamoDB delivered as little as 16% of its provisioned throughput under skewed workloads; ScyllaDB sustained target throughput with single-digit millisecond P99 latencies throughout.

Key Components of DynamoDB Throttling Architecture
DynamoDB’s throughput enforcement is built on several interdependent components that together determine when DynamoDB throttled requests occur and how the database responds.
Provisioned capacity mode assigns a fixed number of RCUs and WCUs to each table and distributes that allocation evenly across underlying partitions. As tables grow and partition splits occur, capacity is redistributed — but at any given time, each partition has a bounded throughput ceiling. Requests that push a single partition beyond its ceiling trigger throttling at the partition level, producing DynamoDB throttled read events and DynamoDB throttled write events independently.
Adaptive capacity is DynamoDB’s mechanism for redistributing unused capacity from cold partitions to hot ones. It reduces the impact of uneven access patterns over time, but responds to imbalances on a minute-scale timescale — far too slow to prevent throttling from sudden bursts. Adaptive capacity is useful for gradual skew but does not protect against traffic spikes or rapidly shifting hot partitions.
On-demand capacity mode removes the explicit provisioning requirement, allowing DynamoDB to scale partitions automatically. DynamoDB on demand throttling is still possible when traffic exceeds 2x the previous peak throughput in a short window. For workloads with extreme or irregular spikes — seasonal traffic, event-driven architectures — the on-demand throttling window presents a real operational risk.
DynamoDB GSI throttling applies independently to each global secondary index. Each GSI maintains its own partition structure and token bucket allocation. A table with three GSIs has four independent throttling surfaces. High query rates against a specific GSI can produce DynamoDB throttled read events on that index while the base table operates without issue, making per-index throughput monitoring essential in production.
High query rates against a GSI can trigger GSI throttling, which causes a replication lag in the index. This throttles the base table’s writes until the GSI replication catches up with the incoming write workload.
ScyllaDB vs DynamoDB Throttling: Predictable Throughput Without Capacity Planning
DynamoDB’s throttling model forces a recurring capacity planning decision: overprovision to absorb peaks (and pay for unused capacity), or provision tightly and accept throttling errors (and pay with engineering time and application complexity). Neither option is free, and for teams operating at scale, both costs compound.
ScyllaDB’s architecture eliminates this decision. Each CPU core owns a shard of the data and processes requests for that shard independently. The concepts of RCUs, WCUs, and token buckets do not apply. Throughput is bounded by hardware (disk I/O, network bandwidth, and CPU capacity) rather than by configurable quotas that can be exhausted at arbitrary traffic levels.
In practice, this means teams running ScyllaDB do not monitor per-partition or per-GSI capacity consumption and do not restructure partition key design to avoid hot partition throttling. This avoids the engineering overhead that DynamoDB throttling demands (retry tuning, jitter configuration, idempotency enforcement on retried writes).
For workloads with highly variable traffic, ScyllaDB’s hardware-based model can be a better fit. DynamoDB on demand throttling can kick in if traffic suddenly spikes beyond recent peaks. ScyllaDB can service requests up to whatever the cluster allows, plus it can add capacity faster than DynamoDB.
Since ScyllaDB is API-compatible with DynamoDB, applications using AWS SDK DynamoDB clients can point at a ScyllaDB cluster with minimal code changes. Teams can test existing workloads against ScyllaDB before committing to migration, making the throughput comparison verifiable rather than theoretical.
How DynamoDB Throttling Exceptions Work
When DynamoDB throttles a request, it returns a ProvisionedThroughputExceededException to the caller. This is a DynamoDB throttling exception that signals the request was rejected before execution — no data was written or read, and the operation is safe to retry. AWS SDKs implement automatic retry with exponential backoff by default, but the default configuration is rarely appropriate for production workloads at scale.
The core challenge of handling DynamoDB throttled requests in production is avoiding a thundering herd: when many application instances retry simultaneously after being throttled, they collectively saturate the partition’s token bucket again immediately, perpetuating the throttle cycle. Production implementations add jitter to retry intervals. AWS documentation recommends full jitter or decorrelated jitter as the most effective approaches for high-concurrency workloads.
DynamoDB write throttled requests require particular care when designing application logic. Although the
ProvisionedThroughputExceededException confirms rejection and is safe to retry, engineers must still apply the general rule for write operations: audit non-idempotent patterns (like conditional writes or side-effecting updates) and explicitly confirm the SDK’s retry behavior is safe. This practice prevents the risk of duplicate writes when a failure is ambiguous (e.g., due to a network timeout).
How ScyllaDB Handles Throughput Without Throttling
ScyllaDB uses a preemptive task scheduler built on the Seastar framework, which allocates CPU time across concurrent requests without enforcing any external capacity quota. Each shard processes its own requests in a non-blocking event loop, and the scheduler preempts long-running tasks to maintain responsiveness. ScyllaDB avoids artificial throughput ceilings, but it does use backpressure and load shedding to maintain system stability. Instead of a ‘ProvisionedThroughputExceededException,’ ScyllaDB prioritizes requests using its internal scheduler.
For workloads with mixed read and write traffic, ScyllaDB’s I/O scheduler supports configurable shares per workload class, providing priority-based throughput allocation. Background operations like compaction run at reduced priority and do not directly compete with client-facing requests. Heavy maintenance operations slow down gracefully instead of producing hard errors equivalent to DynamoDB throttling errors.
At hardware saturation, ScyllaDB increases tail latency rather than rejecting requests. For most production workloads, p99 latency increases as a leading indicator, giving teams time to scale before request errors occur. The operational profile is fundamentally different from DynamoDB’s hard-limit throttling model, where requests are rejected without warning when partition capacity is exhausted.
DynamoDB Throttling Limitations Explained
DynamoDB distributes provisioned capacity evenly across partitions, but production traffic is rarely uniform. A single high-traffic partition key can exhaust its partition’s capacity share and be throttled even when the overall table has available throughput. Even though DynamoDB dynamically reallocates throughput to hot partitions, this operation can still take time to reflect in capacity.Resolving hot partition throttling typically requires restructuring partition keys or implementing write sharding — both of which require application changes and can be time-consuming to deploy safely.
DynamoDB on demand throttling still occurs when requests exceed 2x the table’s previous peak throughput. Workloads with infrequent but large traffic spikes — seasonal applications, event-driven architectures, batch jobs — can reach this threshold unexpectedly, with limited warning and no manual control to raise the ceiling ahead of time.
DynamoDB GSI throttling on a heavily queried index can degrade specific query patterns while the base table operates normally. Tables with multiple GSIs require separate per-index capacity monitoring and tuning, multiplying the operational footprint of capacity management and making root cause diagnosis for throttle incidents non-obvious.
Handling DynamoDB throttling errors correctly at high request rates requires careful configuration of retry counts, delay intervals, jitter algorithms, and idempotency guarantees for retried writes. This complexity scales with the number of tables and write patterns in the system. At organizational scale, ensuring consistent retry correctness across all services and teams becomes a significant engineering governance challenge.
How Much Does DynamoDB Throttling Cost?
DynamoDB’s cost is based on consumed capacity units. In provisioned capacity mode, you pay for allocated RCUs and WCUs regardless of utilization. Under-provisioning minimizes the capacity bill but introduces DynamoDB throttling errors and the engineering cost of handling them; over-provisioning eliminates throttling but results in paying for capacity that is never consumed.
On-demand mode charges per request at a higher per-unit rate than provisioned capacity. For sustained, high-throughput workloads, it is typically more expensive than provisioned mode with reserved capacity. The DynamoDB throttling limit in on-demand mode is determined by the 2x-previous-peak rule rather than an explicit setting, making it harder to predict and plan around.
Reserved capacity is available for provisioned-mode tables, offering 1- and 3-year commitments at reduced rates. This lowers steady-state cost but creates planning risk: workloads that scale faster than anticipated require purchasing additional capacity at full price or accepting throttling until the next reservation cycle.
ScyllaDB Costs vs DynamoDB Pricing
ScyllaDB Cloud pricing is based on the cluster: you pay for compute and storage of cluster nodes, not for individual read or write operations. For workloads with stable throughput requirements, this model is typically more predictable and more cost-efficient than DynamoDB’s per-unit pricing. There is no equivalent of DynamoDB throttling limit management — capacity is provisioned at the node level and scales linearly with hardware.
To compare pricing on different workload patterns, see the DynamoDB cost calculator.
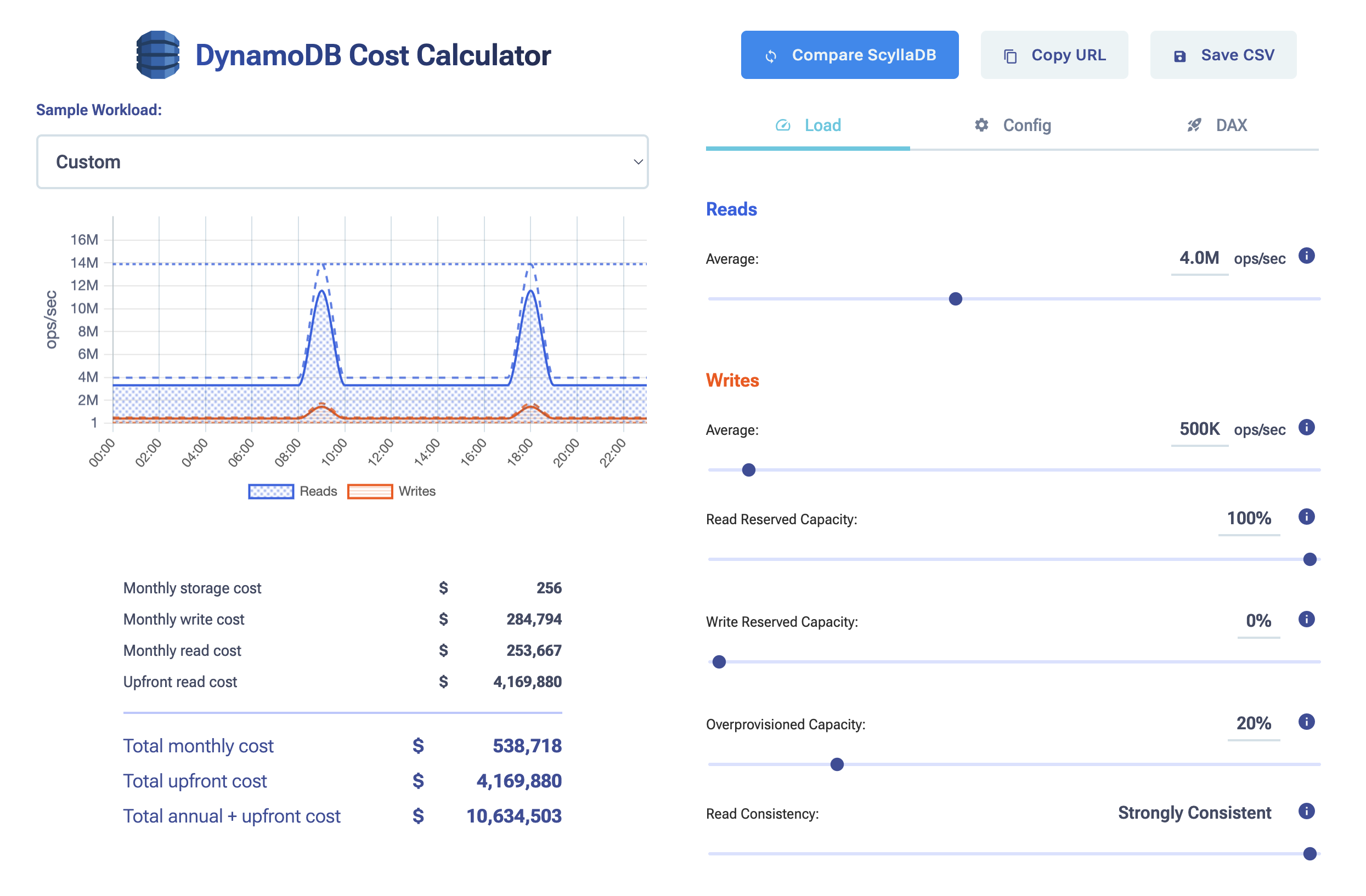
At high throughput (hundreds of thousands of requests per second sustained), the cost difference is significant. DynamoDB costs scale linearly with request volume; ScyllaDB costs scale with cluster size. Teams that have modeled costs at production scale consistently find that ScyllaDB reduces database spend while also eliminating the engineering overhead of throttle management and capacity planning. ScyllaDB’s DynamoDB-compatible API allows cost modeling using existing application code before any migration commitment is made.