




How to combine LangGraph and ScyllaDB for durable state management, crash recovery, and a highly available backend for your agentic AI applications.
Most agent implementations today are request-response loops. The challenge with this approach is that you are just one network issue or server restart away from losing context and progress. We have more powerful LLMs than ever, yet we’re wrapping them in fragile infrastructure.
As an example, assume you have an agent process that takes three minutes and involves seven API calls. There are a lot of places where it can go wrong. The process dies, the state disappears, and the agent starts over with no recollection of what it was doing.
Implementing a well-designed workflow orchestration client is not enough to solve this problem. You also need to implement a distributed and highly available backend to support your agents, something with:
- multi-region, durable storage
- automatic data replication
- fault tolerance
- high-throughput
This post shows you how you can simplify your backend by using a single mature database that handles both high availability and durable storage for your agents. You write agent state to a persistent store, it survives crashes by default, and you can still meet 5ms P99 latency requirements.
Pair that with an orchestration framework like LangChain’s LangGraph that saves state after every step, and you get a reliable and scalable agentic backend.
Let’s see why and how you should implement a system like that with ScyllaDB.
Achieving zero agent downtime with ScyllaDB
ScyllaDB is a high-performance distributed NoSQL database designed to stay up and available for mission-critical applications.
The Raft consensus algorithm handles topology changes and schema updates with strong consistency. Replication is automatic: you set a replication factor and ScyllaDB distributes copies across nodes, racks, and datacenters.
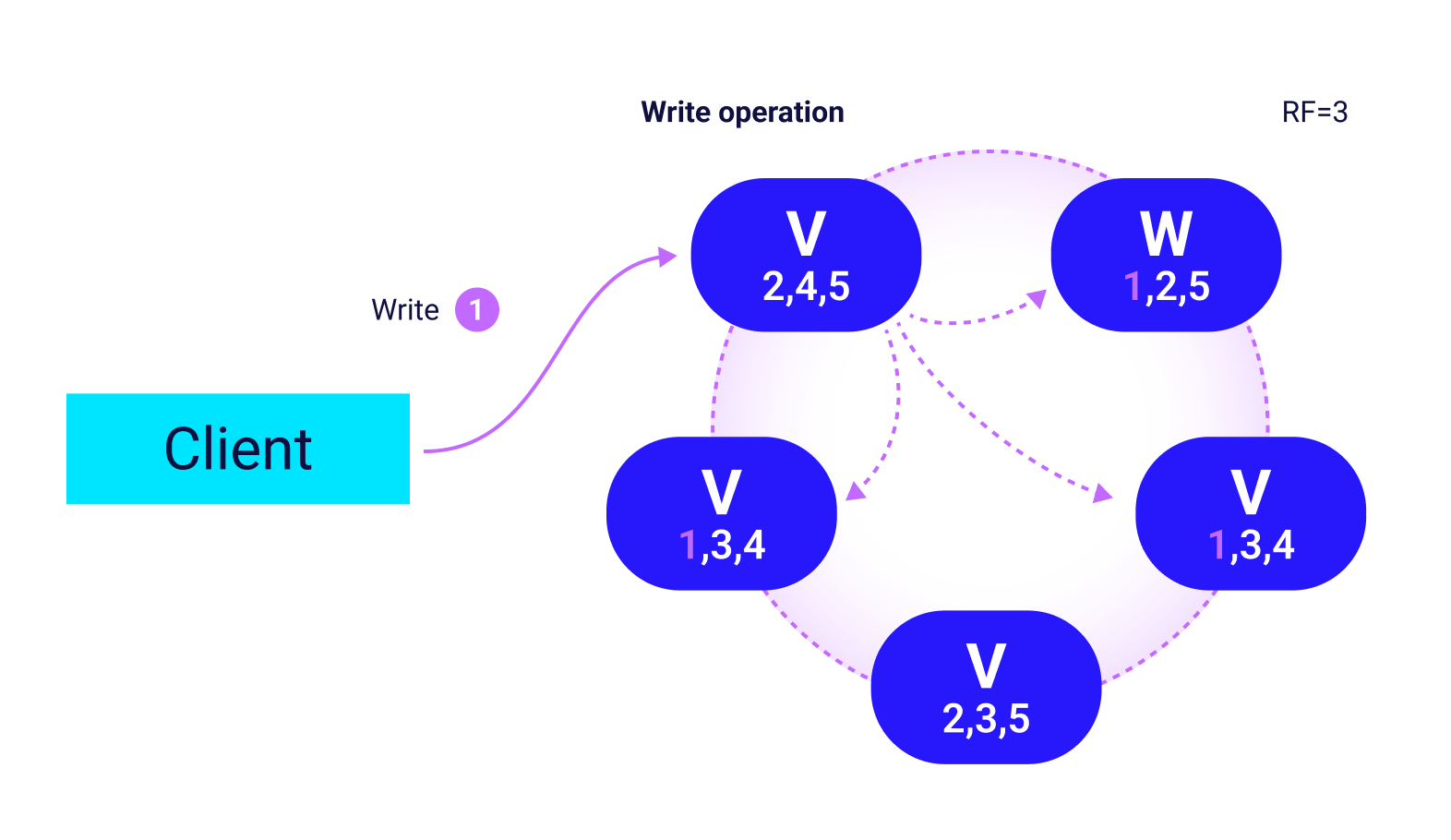
On temporary node loss, Hinted Handoffs record missed writes and replay them when the node returns. For longer outages, row-level repair brings a replacement node up to date in the background. You don’t need load balancers, external replication jobs, or manual failover steps.
ScyllaDB Cloud is a mature cloud offering. Multi-region clusters with tunable replication factors per datacenter, rack and availability-zone awareness, and zero-downtime operations are all available out of the box, with no extra components required.
ScyllaDB also provides practical features for agentic use cases…
Persistent by design
Every write goes to durable storage. There is no configuration flag to enable durability; it is the default, not an option. Persistence allows your agent to recover from crashes and continue a process.
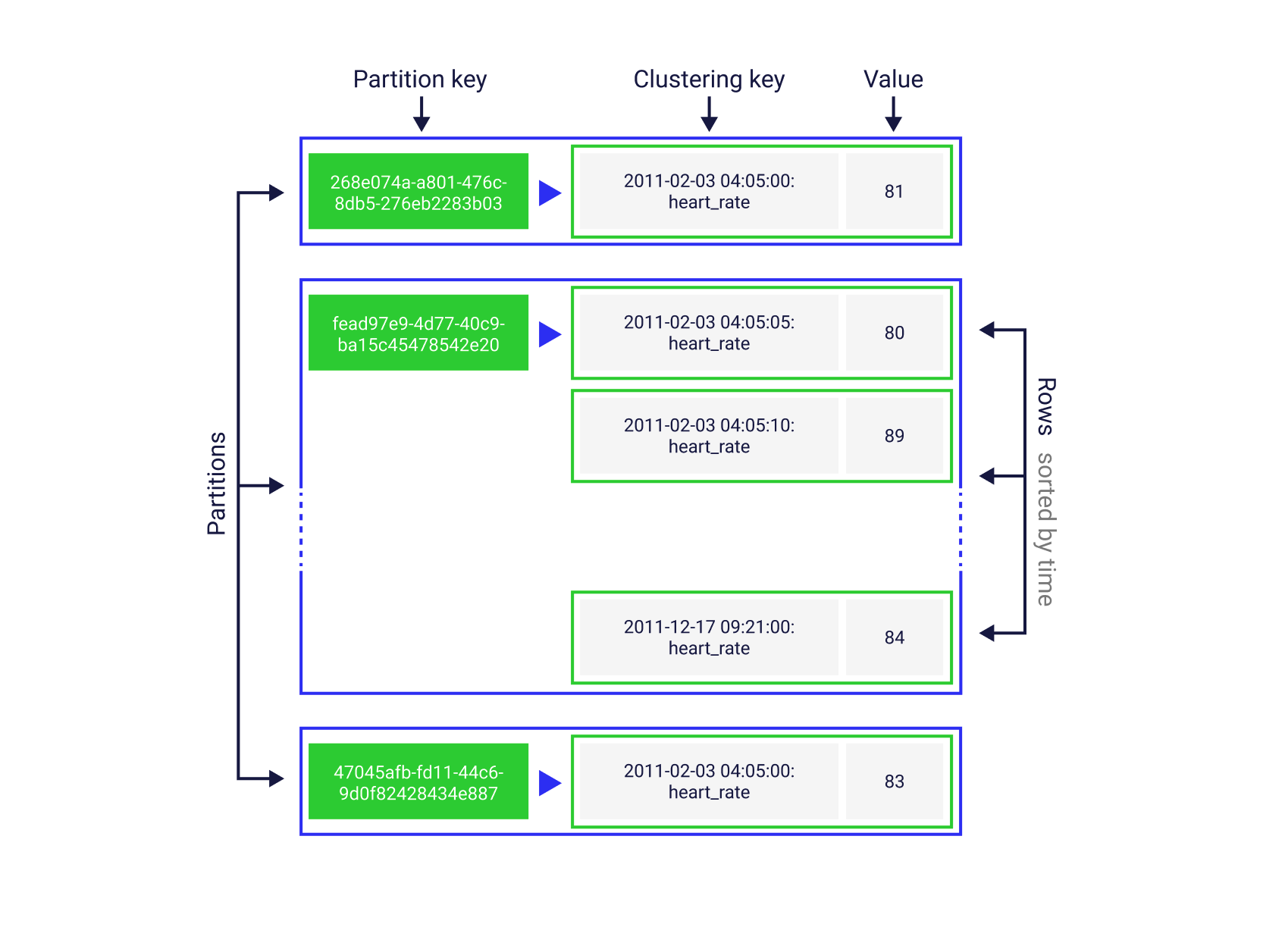
Data model
In ScyllaDB, you design tables around the queries your application will run. A partition key determines which node owns the data, rows within a partition are sorted by a clustering key, and that sort order is fixed at schema creation time. This design is a great fit for key-value agentic systems.
Lightweight transactions
ScyllaDB supports LWTs to provide compare-and-set semantics natively, without client-side locking:
INSERT IF NOT EXISTS and UPDATE ... IF ...
This feature enables idempotent checkpoint writes.
Time-to-live
Agentic sessions eventually go stale. ScyllaDB provides a native way to expire old data from your database.
ScyllaDB’s role in your agentic infrastructure
Now let’s explore specific use cases where ScyllaDB helps you build agentic applications. The following examples use LangGraph (TypeScript) and the community-created ScyllaDBSaver checkpointer.
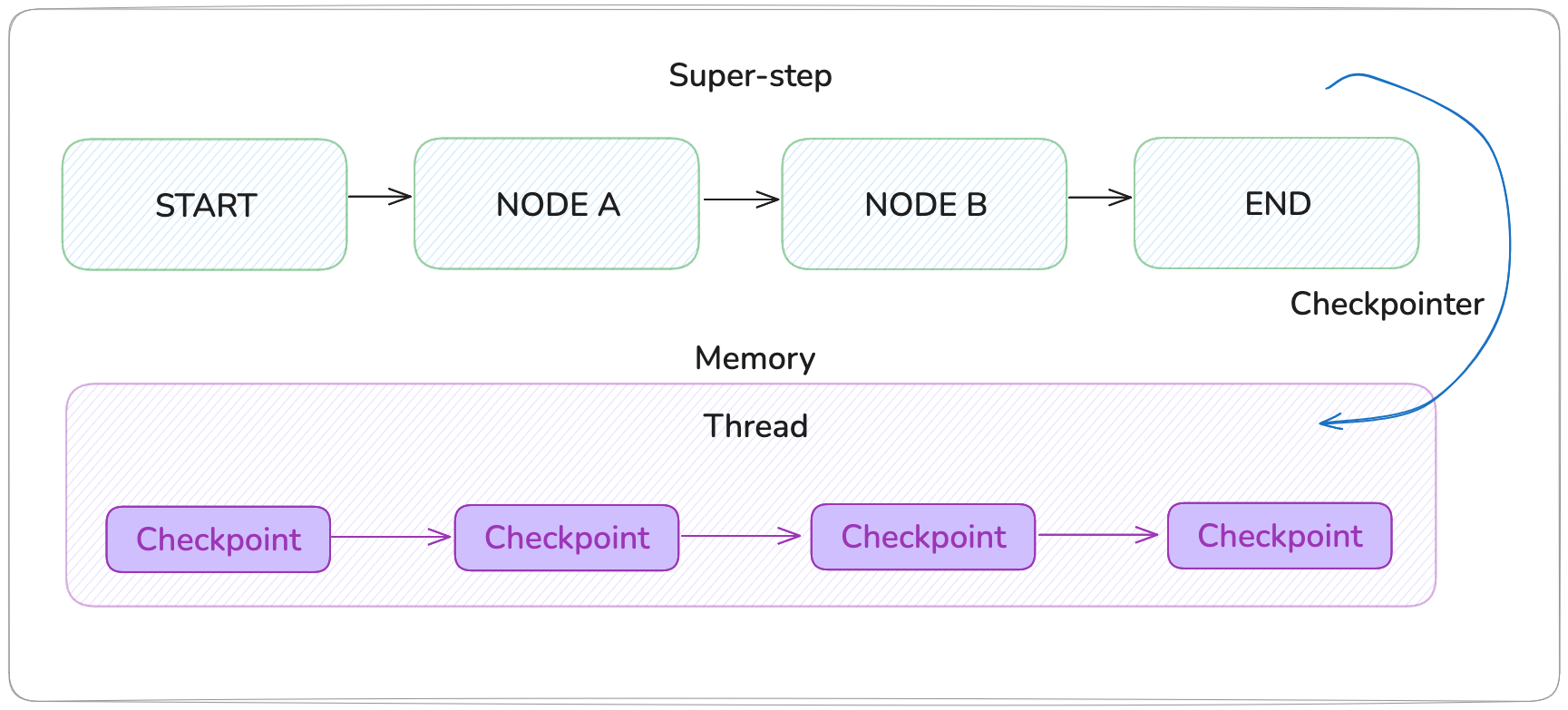
What is a checkpointer?
Checkpointer is LangGraph’s abstraction for a persistence backend. This is how LangGraph integrates with databases.
Durable conversation memory
One of the main technical problems with agents is handling failures such as:
- network hiccups
- server restarts
- other reasons a process gets killed midway through
The in-memory state is gone, and the agent behaves as if the conversation never happened.
LangGraph’s MemorySaver (built-in in-memory checkpointer) makes this reproducible. Run two turns, discard the saver object, create a new one, and run a third turn:
thread_id: a named conversation/session in LangGraph; all checkpoints for one conversation share the same thread.
With ScyllaDB as the checkpointer, all three requests operate identically from an application standpoint. The agent picks up exactly where it left off because the conversation state lives in the database rather than in the server process.
ScyllaDBSaver example:
The query that loads state on every invoke() is:
Note that we don’t use ORDER BY or run a full-table scan. There’s only one row returned: the most recent checkpoint for the thread.
Why does LIMIT 1 return the newest row without an explicit sort? Let’s see how the ScyllaDB data model enables this kind of query.
Source: https://aws.amazon.com/blogs/database/build-durable-ai-agents-with-langgraph-and-amazon-dynamodb/
Query-first schema design: reading the latest checkpoint
LangGraph reads the latest checkpoint on every invoke(). In a busy agent server, that is a read-heavy query pattern.
The checkpoints table is defined with a compound primary key:
The partition key is (thread_id, checkpoint_ns). That means this key will be used to partition your data across the ScyllaDB cluster. All checkpoints for a single conversation land in the same partition.
“Get all steps for this conversation” never requires cross-node coordination.
The clustering key is checkpoint_id DESC. It makes sure that the rows within each partition are sorted according to that column in descending order.
Because checkpoint_id is a UUIDv6 (which encodes a timestamp in its bit layout), rows are physically stored on disk with the newest checkpoint first. LIMIT 1 on a partition scan reads only the first row; no full scan is required.
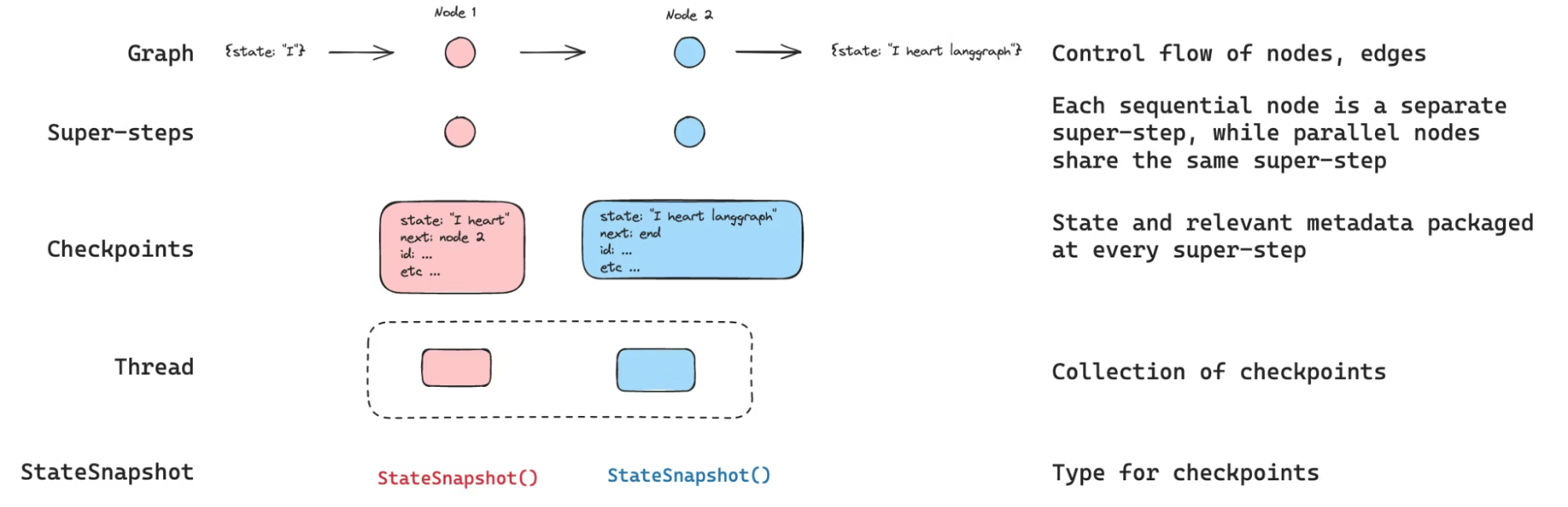
Source: https://docs.langchain.com/oss/python/langgraph/persistence
Crash recovery with idempotent writes
A node in an agent graph can fail mid-execution after it has already written some of its output. Without a write-ahead log, the only safe option on retry is to re-run the node from scratch. This may produce duplicates, trigger external side effects, or be expensive for long-running LLM calls.
ScyllaDB and LangGraph solves this with a second table, checkpoint_writes, that acts as a write-ahead log at the channel level:
Before a checkpoint row is written to checkpoints, each individual channel write is staged in checkpoint_writes using a lightweight transaction:
IF NOT EXISTS is an idempotent insert. Here’s what happens if the server crashes after three of five channel writes have landed and then restarts:
- LangGraph loads the latest
checkpointsrow - It loads the pending
checkpoint_writesfor that checkpoint ID - It finds the three completed writes
- It resumes from there without re-running successful steps
The partition key on checkpoint_writes is (thread_id, checkpoint_ns, checkpoint_id). All pending writes for a single checkpoint are in the same partition.
“Load all pending writes for checkpoint X” is a single-partition scan, not a cross-cluster lookup.
The two tables serve different query patterns. Keeping them separate makes both queries efficient.
Time-travel and conversation history
LangGraph exposes historical snapshots through the checkpointer’s list() method:
Each tuple is a full CheckpointTuple: the serialized state at that step, the metadata (source, step number, what changed), and the config needed to resume from that exact point.
That last part is what enables time-travel: pass a past checkpoint_id as the starting configuration and LangGraph replays from there, branching the conversation into an alternative trajectory without modifying the original history.
Here’s the underlying ScyllaDB query:
You get all rows for one thread in one partition, sorted newest-first. This is the same partition that hosts the latest-checkpoint read. No additional indexes are required for the history use case.
The source field indicates what kind of step produced it:
"input"(user message ingested, before any node ran)"loop"(a node executed)"update"(state was patched directly viagraph.updateState()).
Secondary indexes on source and step allow filtering across all threads when needed:
Auto-expire data with time-to-live
Production agent deployments accumulate checkpoint data continuously. A customer support agent with 10,000 active threads, each with a 10-turn history, generates tens of thousands of checkpoint rows. Sessions eventually go stale. You might decide, for example, that a thread abandoned by the user after one message can be deleted and stored elsewhere after a certain period of time.
In ScyllaDB, TTL is part of the data model. You attach it directly to the inserted row at write time:
USING TTL 86400 tells ScyllaDB to delete this row after 24 hours. The same TTL clause appears on checkpoint_writes in the same write batch.
The ScyllaDBSaver accepts a ttlConfig parameter that applies this clause to every write:
Change defaultTTLSeconds and every subsequent write picks up the new expiry. No migration required.
Integrate ScyllaDB into your LangGraph project
To use ScyllaDB as a persistent store in your LangGraph application, you need to install the ScyllaDB checkpointer. This package will handle the migration and all subsequent CQL queries for you.
Install the package:
npm install @gbyte.tech/langgraph-checkpoint-scylladb
Create the schema:
npm run migrate
# runs: CREATE KEYSPACE IF NOT EXISTS langgraph ...
# CREATE TABLE IF NOT EXISTS langgraph.checkpoints ...
# CREATE TABLE IF NOT EXISTS langgraph.checkpoint_writes ...
Wire the checkpointer into your graph:
Wrapping up
By combining LangGraph with ScyllaDB’s built-in durability and high availability, you move from fragile, stateful processes to resilient agent systems. Restarts, retries, or lost context won’t be a problem because your architecture treats failure as a normal condition and continues seamlessly.
This shift simplifies your infrastructure as well as enables more ambitious, long-running agent workflows to operate reliably at scale.
Learn more about ScyllaDB and agentic applications:
- Clone the example application
- Read how others use ScyllaDB for AI use cases
- Sign up for ScyllaDB Cloud



