




Learn how ScyllaDB vector search simplifies scalable semantic search & RAG with real-time performance – plus see FAQs on vector search scaling, embeddings, and architecture
As a Solutions Architect at ScyllaDB, I talk a lot about vector search these days. Most vector search conversations start with RAG. Build a chatbot, embed some documents, do a similarity lookup. That’s an important use case, but it’s just the beginning of what vector search can do when you have a platform like ScyllaDB that can scale to massive datasets and hit those p99 latencies
At Monster Scale Summit, I showed two live demos that cover what I think are the two most practical patterns for vector search today: hybrid memory for RAG, and real-time anomaly detection. Both run entirely on ScyllaDB, without needing an external cache (e.g., Redis) or dedicated vector database (e.g., Pinecone). This post explains what I showed and also answers the top questions from attendees.
The Limits of Traditional Search and Anomaly Detection
The old way of doing anomaly detection, retrieving data, doing lookups, using inverted indexes, and running semantic search is brittle. Anyone who has tried to scale an index-based system has experienced this firsthand.
The first step was figuring out what was said before, what data was loaded. Redis caches, key-value stores, document databases, and SQL databases were used to handle that. Then, to determine what documents are relevant, we built custom search pipelines using Lucene-based indexes and similar tools. Next, we built complex rules engines that became difficult to troubleshoot and couldn’t scale.

These systems became extremely complex, with SQL-based regressions and similar mechanisms. The problem is that they’re hard to scale and very rigid. Every new failure mode required building a new rule, sometimes entirely new rules engines. Often, these detection paths required completely different systems.
The result was graph use cases, vector systems, and multiple databases: a collection of systems solving what are ultimately simple problems. As you might imagine, these systems become quite brittle and expensive to operate.
You could avoid this with a conceptual shift: from matching rules to finding things that look similar. That shift from rigid logic to semantic similarity is what vector search is trying to achieve, whether through text embeddings or other encodings.

RAG with Hybrid Memory
The first demo showed how we can build three distinct memory tiers for RAG, all living within ScyllaDB. This “hybrid memory” pattern allows you to handle everything from immediate context to long-forgotten conversations without a complex conglomerate of different databases.
Short-term memory: This handles the last five records of your interaction as a rolling window. It is very fast, uses a short TTL, and ensures the AI stays on track with the immediate conversation.
Long-term memory: This is where vectors shine. If you’ve been chatting with a bot for 6 days, that history won’t fit in a standard context window. We use vector search to retrieve specific conversation parts that matter based on embedded similarity, loading only the relevant history into the prompt. This is the piece that makes a chatbot feel like it actually remembers.
Document enrichment: This phase takes uploaded files (PDFs, Markdown files, etc.), chunks them semantically, embeds each chunk, and stores those vectors in ScyllaDB. When you ask a question, the system retrieves the most relevant chunks and feeds them to the model.

Basically, I used ScyllaDB to manage key-value lookups, vector similarity, and TTL expiration in a single cluster, which meant I didn’t need extra infrastructure like Redis or Pinecone. It processed LinkedIn profiles by breaking them into semantic chunks (one profile generated 43 chunks) and stored those embeddings in ScyllaDB Cloud to be queried in real-time.
The frontend is built in Elixir, the backend is ScyllaDB Cloud with vector search enabled. The code is on my GitHub. Pull it, run it, and try it out with your own documents.
Anomaly Detection: Three Paths, One Database
The second demo is where vector search truly earns its keep. The setup models an IoT pipeline:
- Devices generate metrics every 10 seconds
- Metrics stream through Kafka
- They’re aggregated into 60-second windows
- Finally, they land in ScyllaDB as 384-dimensional embeddings generated by Ollama.

From there, three detection paths run in parallel against every snapshot.
Path 1: Rules engine. This is classic Z-score analysis. If four or more metrics exceed a Z-score of 6.0, flag it. This is fast and interpretable. It catches known anomaly patterns and misses everything else.
Path 2: Embedding similarity. Build a behavioral fingerprint for each device. Compare every new snapshot against that fingerprint using cosine similarity. If the score drops below 0.92, something has drifted. This catches gradual behavioral changes that hard thresholds miss.
Path 3: Vector search. Run an ANN query across the device’s historical snapshots in ScyllaDB. Post-filter for the same device, non-anomalous records, and a cosine similarity above 0.75. If fewer than five similar normal snapshots exist, that snapshot is anomalous.

You don’t need to write any rules or tune thresholds per device. The data tells you what normal looks like.
In the demo, I showed a sensor drift scenario where power consumption dropped slightly and a few other metrics shifted just enough to be unusual. This slipped past the rules engine and embedding similarity, but vector search caught it. It’s Exhibit A for how vector search exposes subtle anomalies that rigid systems can’t see.
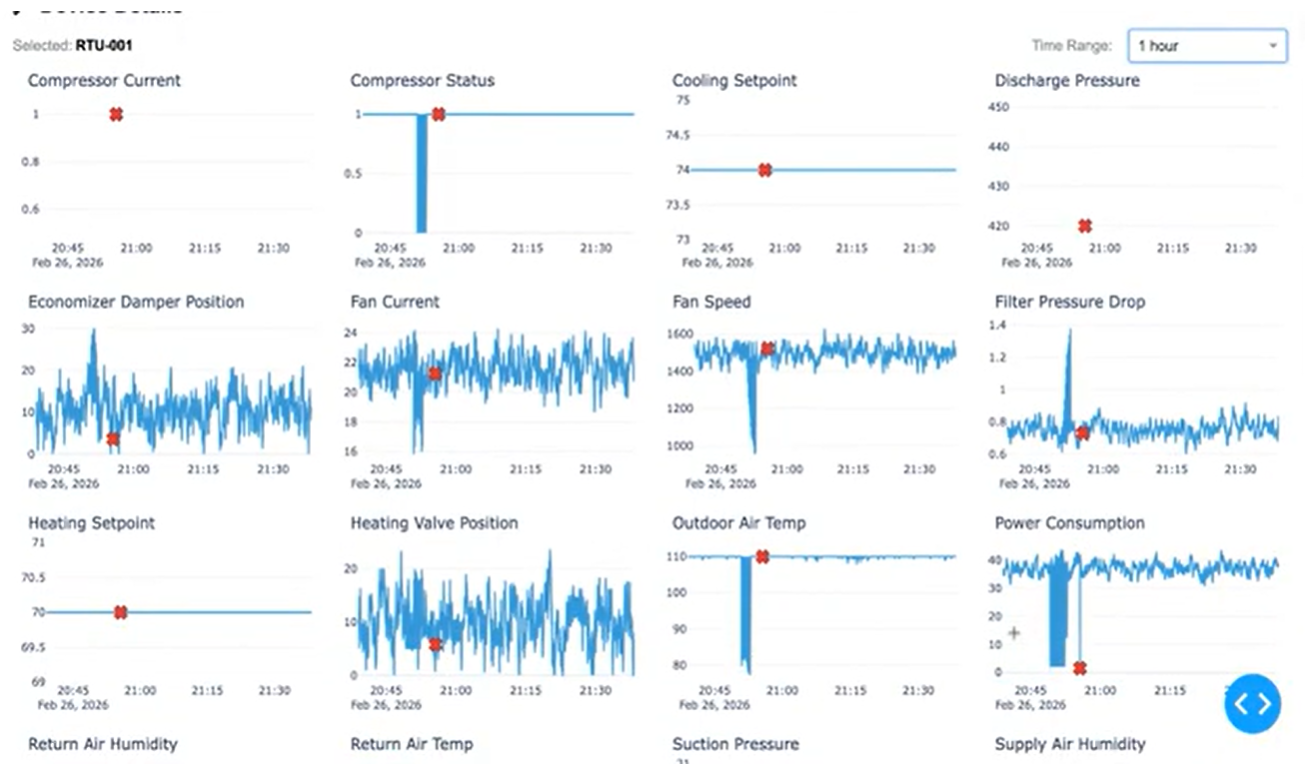
The reason this works on a single cluster is that ScyllaDB handles vectors alongside time series, key-value, and TTL data with sub-10 millisecond queries under heavy concurrent load. Snapshots, profiles, anomaly events, and the vector index all live in one place. The anomaly detection demo runs in Docker if you want to try it on your own data.
Common Questions About ScyllaDB Vector Search
Technical demos naturally lead to questions, and we heard plenty at MonsterScale (thanks for keeping us busy in the chat). Here are responses to the top questions we fielded…
“What about new devices with no history?” Fair concern. Path 3 decides “anomaly” when it finds fewer than five similar normal snapshots. A brand new device with ten records will trigger on everything. The fix is a minimum history gate. Don’t run the vector path until a device has enough baseline data to make comparisons meaningful. In practice, the rules engine and embedding similarity cover the gap while the device builds history.
“How do I know my embeddings are good enough?” Test them against known anomalies before you go to production. Bad embeddings produce bad neighbors, and similarity search will give you confidently wrong answers. Run a batch of labeled data through your embedding model, query for nearest neighbors, and check whether the results make sense. If your model does not capture the right features, no amount of tuning the similarity threshold will save you.
“Does this scale to millions of devices?” The ANN query itself scales; the part you want to watch is post-filtering. The query returns candidates, and your application code still has to filter by device, status, and similarity threshold. At millions of devices, that step needs to be efficient. Batch your comparisons and keep your filter criteria tight. Someone at the talk asked about the performance impact of deletions on the vector index as old snapshots expire. ScyllaDB’s index structure is optimized for deletion, so the index stays healthy as data churns through.
“Can I just use vector search and skip the rules engine?” Yes, you can…but you’ll regret it. The three-path approach works because each path catches a different class of problem. Rules engines are still the fastest way to catch known, well-defined failures. Someone at the talk asked whether an LLM with MCP could just explore the context and find anomalies itself. It can. But vector search is cheaper. No LLM invocation, no context window limit, and it runs at the speed of a database query. Use each tool for what it is good at.
Try It Yourself
If you want to see what ScyllaDB can do for your vector workloads, sign up for a demo. I’m always happy to walk through architectures and talk through what makes most sense for your specific requirements.
Connect with me on LinkedIn if you have questions, want to collaborate, or just want to talk about distributed systems. I read every message.



