Rethinking ScyllaDB’s shard-aware drivers for our new Raft-based tablets architecture
ScyllaDB recently released new versions of our drivers (Rust, Go, Python…) that will provide a nice throughput and latency boost when used in concert with our new tablets architecture. In this blog post, I’d like to share details about how the drivers’ query routing scheme has changed, and why it’s now more beneficial than ever to use ScyllaDB drivers instead of Cassandra drivers.
Before we dive into that, let’s take a few steps back. How do ScyllaDB drivers work? And what’s meant by “tablets”?
When we say “drivers,” we’re talking about the libraries that your application uses to communicate with ScyllaDB. ScyllaDB drivers use the CQL protocol, which is inherited from Cassandra (ScyllaDB is compatible with Cassandra as well as DynamoDB). It’s possible to use Cassandra drivers with ScyllaDB, but we recommend using ScyllaDB’s drivers for optimal performance. Some of these drivers were forked from Cassandra drivers. Others, such as our Rust driver, were built from the ground up.
The interesting thing about ScyllaDB drivers is that they are “shard-aware.” What does that mean? First, it’s important to understand that ScyllaDB is built with a shard-per-core architecture: every node is a multithreaded process whose every thread performs some relatively independent work. Each piece of data stored in a ScyllaDB database is bound to a specific CPU core.
ScyllaDB shard-awareness allows client applications to perform load balancing following our shard-per-core architecture. Shard-aware drivers establish one connection per shard, allowing them to load balance and route queries directly to the single CPU core owning it. This optimization further optimizes latency and is also very friendly towards CPU caches.
Before we get into how these shard-aware drivers support tablets, let’s take a brief look at ScyllaDB’s new “tablets” replication architecture in case you’re not yet familiar with it. We replaced vNode-based replication with tablets-based replication to enable more flexible load balancing. Each table is split into smaller fragments (“tablets”) to evenly distribute data and load across the system. Tablets are replicated to multiple ScyllaDB nodes for high availability and fault tolerance. This new approach separates token ownership from servers – ultimately allowing ScyllaDB to scale faster and in parallel.
For more details on tablets, see these blog posts.
How We’ve Modified Shard-Aware Drivers for Tablets
With all that defined, let’s move to how we’ve modified our shard-aware drivers for tablets. Specifically, let’s look at how our query routing has changed.
Before tablets
Without tablets, when you made a select, insert, update, or delete statement, this query was routed to a specific node. We determined this routing by calculating the hashes of the partition key. The ring represented the data, the hashes were the partition keys, and this ring was split into many vNodes.
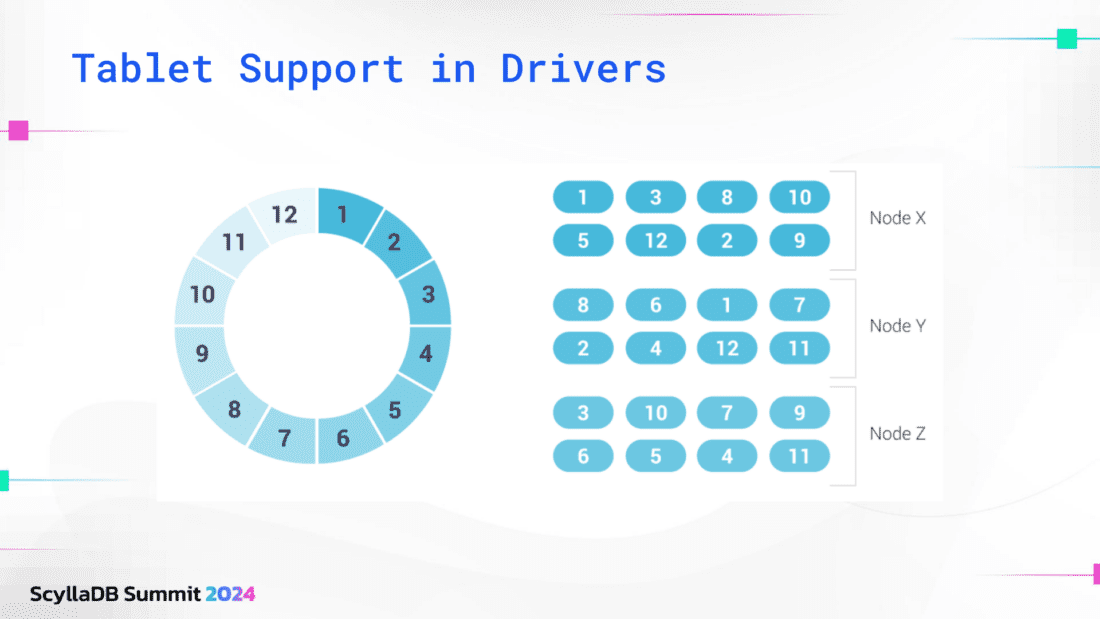
When data was replicated, one piece of the data was stored on many nodes.
The problem with this approach is that this mapping was fairly static. We couldn’t move the vNodes around and the driver didn’t expect this mapping to change. It was all very static. Users wanted to add and remove capacity faster than this vNodes paradigm allowed.
With tablets
With tablets, ScyllaDB now maintains metadata about the tablets. The tablet contains information about which table each tablet represents and the range of data it stores. Each tablet contains information about which replicas hold the data within the specified start and end range.

Interestingly, we decided to have the driver start off without any knowledge of where data is located – even though that information is stored in the tablet mapping table. We saw that scanning that mapping would cause a performance hit for large deployments.
Instead, we took a different approach: we learn the routing information “lazily” and update it dynamically. For example, assume that the driver wants to execute a query. The driver will make a request to some random node and shard – this initial request is guessing, so it might be the incorrect node and shard.
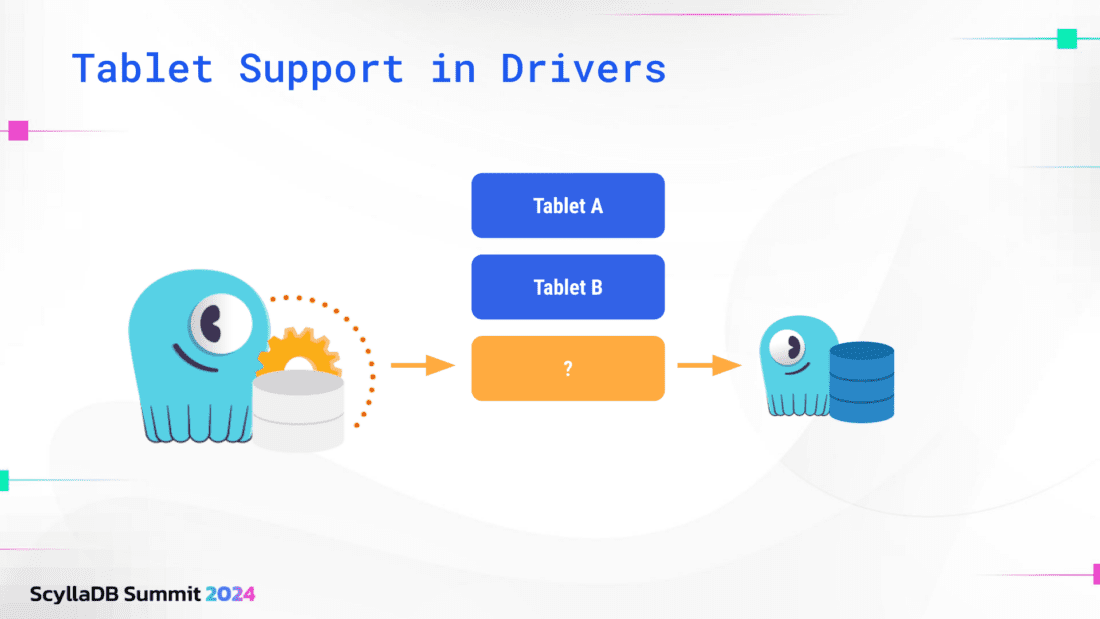
All the nodes know which node owns which data. Even if the driver contacts the wrong node, it will forward the request to the correct node. It will also tell the driver which node owns that data, and the driver will update its tablet metadata to include that information. The next time the driver wants to access data on that tablet, it will reference this tablet metadata and send the query directly to the correct node. If the tablet containing that data moves (e.g., because a new node is added or removed), the driver will continue sending statements to the old replicas – but since at least one of them is not currently a replica, it will return the correct information about this tablet.
The alternative would be to refresh all of the tablet metadata periodically (maybe every five seconds), which could place significant strain on the system. Another benefit of this approach: the driver doesn’t have to store metadata about all tablets. For example, if the driver only queries one table, it will only persist information about the tablets for that specific table. Ultimately, this approach enables very fast startup, even with 100K entries in the tablets table.
Why use tablet-aware drivers
When using ScyllaDB tablets, it’s more important than ever to use ScyllaDB shard-aware – and now also tablet-aware – drivers instead of Cassandra drivers. The existing drivers will still work, but they won’t work as efficiently because they won’t know where each tablet is located. Using the latest ScyllaDB drivers should provide a nice throughput and latency boost.