





Repair-Based Node Operations provides a more robust, reliable, and safer data streaming for node operations like node-replace and node-add/remove
ScyllaDB 5.4 marks a major milestone for our monstrously fast and scalable database: Repair-Based Node Operations (RBNO) is now enabled by default for all operations. What are node operations? Topology changes (add, remove, decommission a node) as well as replacing and rebuilding nodes. Such operations require data exchange among nodes. With this release, that data exchange shifts from using streaming to using repair. We’ll unravel all that in a bit. But, the TL;DR is that this change makes node operations faster and more reliable.
To understand the benefits of RBNO, let’s recap what streaming involves (in this context) and some of the drawbacks it introduces. Then, we’ll look at repair-based node operations in ScyllaDB, as well as two other features that impact the performance and safety of node operations: off-strategy compaction and gossip-free node operations.
Streaming
Streaming was traditionally the main component involved in exchanging data among nodes during cluster operations. For example, whenever you had to replace a dead node in your cluster, streaming would kick in to transfer data to the new node. Similarly, when removing a dead node, existing nodes used streaming to pull data from existing replicas in order to satisfy your configured replication factor.
Streaming performs well in theory. However, it doesn’t address several consistency concerns involved in running some of these operations. For concrete examples of the potential problems, let’s look at the replace node operation.
Assume you have a 3-node cluster running, and your application is constantly writing data to it:
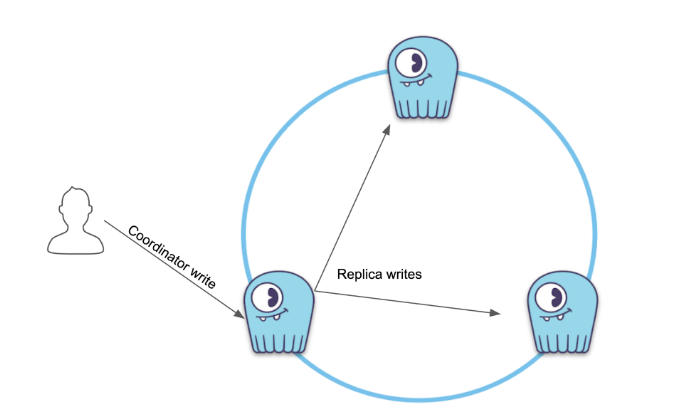
Writes to the coordinator node get replicated to replicas
So far so good: The client driver routes a query to a coordinator node and then replicates the mutation to other replicas.
Let’s consider the not-so-uncommon situation where a given write fails to reach a given replica, yet that write still satisfied your consistency level requirements (say QUORUM):
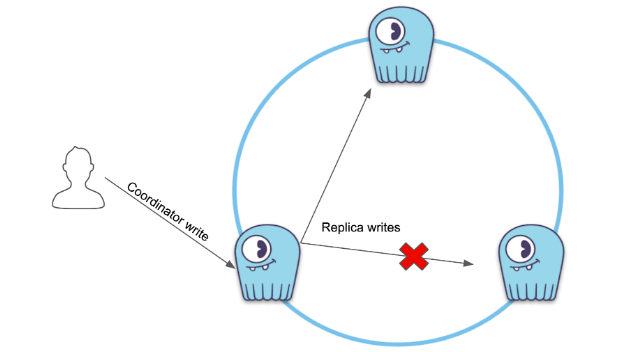
Writes reached all but one replica, satisfying our QUORUM requirements
At this point, there are different ways to bring the inconsistent replica back to a consistent state: hints, a read repair, or even a full repair. However, what if none of these happened – and the fates decided that you would lose a node:
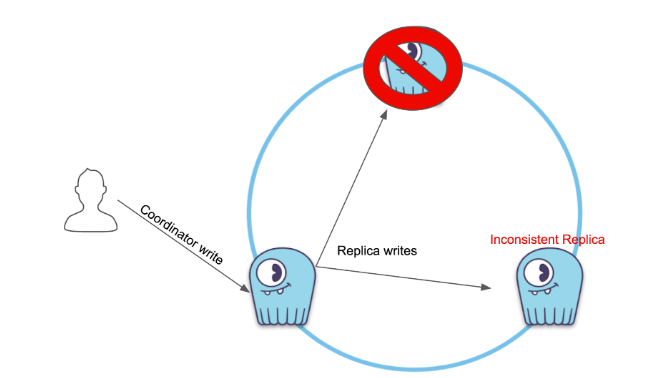
When a node goes down, it’s (somehow) usually the worst possible node
Obviously, you want to get your cluster back into shape. So, you follow the Replace a Dead Node procedure in your cluster. You spin up a fresh new node and tell it to replace the old lazy fellow.
This kicks off streaming, and (un)fortunately for you, streaming happened to pick up the inconsistent replica to exchange data for the affected inconsistent data:
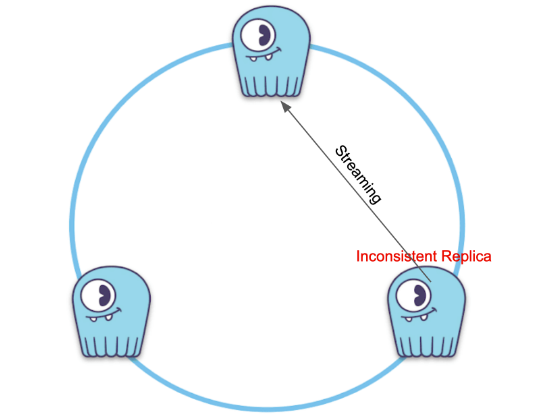
Streaming pulls data from only one of the replicas and doesn’t guarantee the latest copy
As streaming pulls data from only one of the replicas for a given token range, you could end up in a situation where stale data silently becomes a majority in the cluster. Even worse, if you happened to lose the only consistent replica, you would effectively lose data.
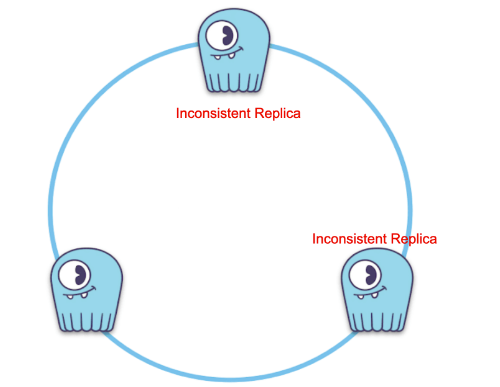
Stale data silently became a majority; at this point, losing the only consistent replica causes data loss
To overcome that, you would run repair after every replace node operation, thus getting the cluster to reconcile data.
Let’s recap what we’ve covered so far:
- Writes may fail to reach a replica given ScyllaDB’s eventual consistency model
- A node operation will kick off streaming
- Streaming will pull data from any replica in the cluster
- Some node operations (replace, rebuild and removenode) still require a repair afterward
It should be clear by now that the streaming logic introduces data durability and consistency concerns. This is not surprising. It’s the approach we inherited from Apache Cassandra years back, and the Cassandra community even acknowledged some of these design flaws:
(…) While a problem with streaming is a relatively minor reduction in durability guarantees, a problem with disagreeing read/write sets is a transient data loss, a consistency violation that likely goes unnoticed on a regular basis. (…)
This inherited design also required the redundant need to repair the cluster after some operations. The Cassandra community is still planning how to address this shortcoming.
We thought: why not resolve these problems once and for all by using the existing repair mechanism? Enter Repair-Based Node Operations (RBNO).
Repair-Based Node Operations
RBNO is a new feature that uses row-level repair as the underlying mechanism to sync data between nodes instead of streaming for node operations like adding or removing a node.
There are multiple benefits of using repair-based node operations:
- Resumable: Improve performance and data safety. For example, we can resume from a failed bootstrap operation without transferring data already synced on this node. This speeds up the operation.
- Consistency: Guarantee that the replacing node has the latest replica to avoid data-consistency issues.
- Simplified: Simplify the procedures so that there is no need to run repairs before or after operations like replacing or removing nodes.
- Unified: Use the same mechanism for all the node operations.
ScyllaDB 4.6 introduced RBNO by default for replacing nodes, covering the most common node operation run by users. Starting with ScyllaDB 5.4, RBNO is enabled for all node operations by default. Although not recommended, you can opt-out from using RBNO for specific operations and fallback to streaming. The allowed_repair_based_node_ops configuration option in scylla.yaml allows you to specify which operations should use repair instead of the old-fashioned streaming logic.
Off Strategy Compaction
Streaming involved exchanging data among nodes, and the streamed data resulted in SSTables. The resulting SSTables created a compaction backlog and required compactions to speed up its operations according to its strategy. As the backlog continued to grow, this situation ended up reducing the available bandwidth for streaming, delaying the operation. It could potentially end up affecting latencies until compaction could process its backlog.
Off strategy compaction increases the efficiency of compaction during node operations, speeding up the process. It’s not necessarily a new concept in ScyllaDB, but wiring it both for legacy streaming and repair-based node operations is.
Off-strategy compaction stores the SSTables created in a disjoint set, deferring its compaction until the underlying node operation completes. After, it integrates the disjoint SSTables into the main set.
Simply splitting node operations’ generated SSTables to a separate set (rather than directly adding them to the main set) reduces compaction work during node operations, allowing them to complete faster.
We enabled off-strategy compaction for all node operations, including regular repairs. Since repairs are non-deterministic, off-strategy compaction is triggered on a per table basis. A timer is set up to kickstart the process of integrating SSTables to the main set as soon as it expires. For other (deterministic) node operations, offstrategy gets triggered immediately at the end of the operation on a per table basis.
Gossip-Free Node Operations
Last but not least, let’s talk about gossip-free node operations. This feature, introduced in ScyllaDB 5.0, uses RPC verbs instead of gossip status during node operations.
Why gossip-free node operations? First, it is safe to run node operations by default. It requires all the nodes in the cluster to participate in topology changes. This avoids data consistency issues if the nodes are network partitioned. For example, if a node is partitioned and they’re not aware of a bootstrap operation, the partitioned node may refer to a wrong token ring to route the traffic – and that may end up introducing data inconsistency.
Another important improvement introduced by this feature is that all the nodes in the cluster can automatically revert to a previous state if an error occurs during operations. For example, if a replace operation fails, the existing nodes will remove the replacing node as a pending endpoint immediately – making it as if the replace operation was never performed.
Another benefit lies in the fact that, currently, node operations must be done serially. You cannot add nodes in parallel or perform multiple node operations at the same time. Gossip-free node operations can reliably detect whether any pending operations are in progress in order to avoid operation mistakes. Each operation is now assigned a unique ID to make it easier to identify node operations cluster-wide.
We have enabled this feature for bootstrap, replace, decommission, and remove node operations. No new action is needed to use it.
Conclusion
We have covered how Repair-Based Node Operations addresses previous consistency concerns involved with data movement. Off-strategy goes even further and speeds up both legacy streaming and node operations. Finally, gossip-free node operations guarantee operation safety by mitigating both human mistakes and infrastructure failures that aren’t so unlikely to happen. It’s all part of our deep-seated commitment to ensuring data integrity, efficiency, and safety for your business-critical use cases.


