




benchANT’s comparison of ScyllaDB vs MongoDB in terms of throughput, latency, scalability, and cost for a caching workload
BenchANT recently benchmarked the performance and scalability of the market-leading general-purpose NoSQL database MongoDB and its performance-oriented challenger ScyllaDB. You can read a summary of the results in the blog Benchmarking MongoDB vs ScyllaDB: Performance, Scalability & Cost, see the key takeaways for various workloads in this technical summary, and access all results (including the raw data) from the benchANT site.
This blog offers a deep dive into the tests performed for the caching workload. The caching workload is based on the YCSB Workload A. It creates a read-update workload, with 50% read operations and 50% update operations. The workload is executed in two versions, which differ in terms of the request distribution patterns (namely uniform and hotspot distribution). This workload is executed against the small database scaling size with a data set of 500GB, the medium scaling size with a data set of 1TB and a large scaling size with a data set of 10TB. In addition to the regular benchmark runtime of 30 minutes, a long-running benchmark over 12 hours is executed.
Before we get into the benchmark details, here is a summary of key insights for this workload.
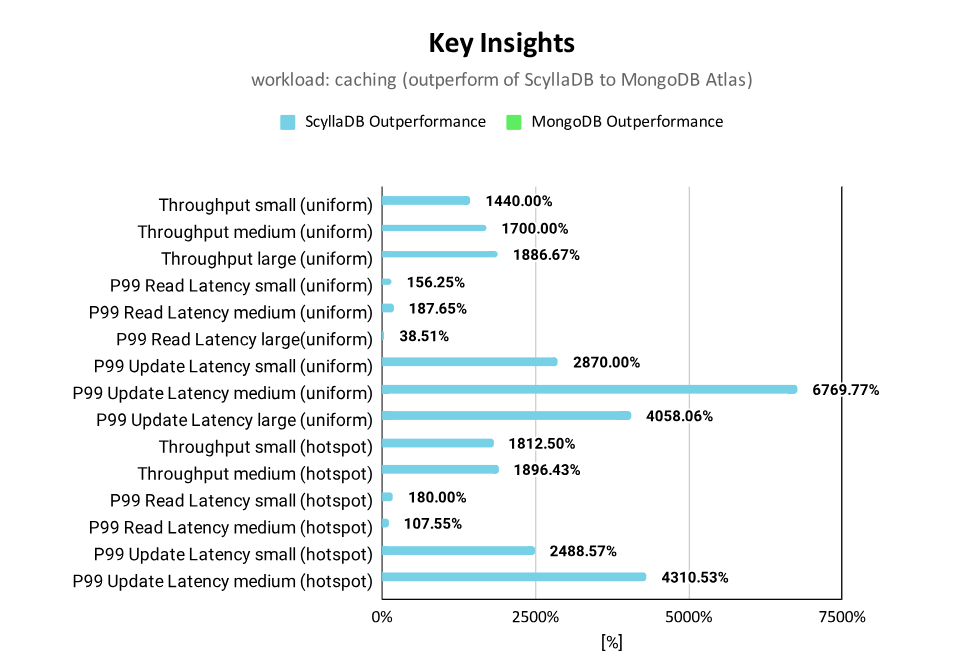
- ScyllaDB outperforms MongoDB with higher throughput and lower latency for all measured configurations of the caching workload.
- Even a small 3-node ScyllaDB cluster performs better than a large 18-node MongoDB cluster
- ScyllaDB provides constantly higher throughput that increases with growing data sizes to up to 20 times
- ScyllaDB provides significantly better update latencies (down to 68 times) compared to MongoDB
- ScyllaDB read latencies are also lower for all scaling sizes and request distributions, down to 2.8 times.
- ScyllaDB achieves near linear scalability across the tests. MongoDB achieves 340% of the theoretically possible 600% and 900% of the theoretically possible 2400%.
- ScyllaDB provides 12-16 times more operations/$ compared to MongoDB Atlas for the small scaling size and 18-20 times more operations/$ for the scaling sizes medium and large.
Throughput Results for MongoDB vs ScyllaDB
The throughput results for the caching workload with the uniform request distribution show that the small ScyllaDB cluster is able to serve 77 kOps/s with a cluster utilization of ~87% while the small MongoDB serves only 5 kOps/s under a comparable cluster utilization of 80-90%. For the medium cluster sizes, ScyllaDB achieves an average throughput of 306 kOps/s by ~89% cluster utilization and MongoDB 17 kOps/s. For the large cluster size, ScyllaDB achieves 894 kOps/s against 45 kOps/s of MongoDB.
Note that client side errors occurred when inserting the initial 10TB on MongoDB large; as a result, only 5TB of the specified 10TB were inserted. However, this does not affect the results of the caching workload because the applied YCSB version only operates on the key range 1 – 2.147.483.647 (INTEGER_MAX_VALUE); for more details, see the complete report on the bencHANT site. This fact leads to an advantage for MongoDB because MongoDB’s cache had only to deal with 2,100,000,000 accessed records (i.e. 2.1TB) while ScyllaDB’s cache had to deal with the full 10,000,000,000 records (i.e. 10TB).

The caching workload with the hotspot distribution is only executed against the small and medium scaling size. The throughput results for the hotspot request distribution show a similar trend, but with higher throughput numbers since the data is mostly read from the cache. The small ScyllaDB cluster serves 153 kOps/s while the small MongoDB only serves 8 kOps/s. For the medium cluster sizes, ScyllaDB achieves an average throughput of 559 kOps/s and MongoDB achieves 28 kOps/s.

Scalability Results for MongoDB vs ScyllaDB
The throughput results allow us to compare the theoretical throughput scalability with the actually achieved scalability. For ScyllaDB, the maximum theoretical scaling factor for throughput for the uniform distribution is 1600% when scaling from small to large. For MongoDB, the theoretical maximal throughput scaling factor is 2400% when scaling from small to large.
The ScyllaDB scalability results show that scaling from small to medium is very close to achieving linear scalability by achieving a throughput scalability of 397% of the theoretically possible 400%. Considering the maximal scaling factor from small to large, ScyllaDB achieves 1161% of the theoretical 1600%.
For the hotspot distribution, the small and medium cluster sizes are benchmarked. ScyllaDB achieves a throughput scalability of 365% of the theoretical 400%.


The MongoDB scalability results for the uniform distribution show that MongoDB scaled from small to medium achieves a throughput scalability of 340% of the theoretical 600%. Considering the maximal scaling factor from small to large, MongoDB achieves only 900% of the theoretically possible 2400%.
MongoDB achieves a throughput scalability of 350% of the theoretical 600% for the hotspot distribution.


Price-Performance Results for MongoDB vs ScyllaDB
In order to compare the costs/month in relation to the provided throughput, we take the MongoDB Atlas throughput/$ as baseline (i.e. 100%) and compare it with the provided ScyllaDB Cloud throughput/$.
The results for the uniform distribution show that ScyllaDB provides 12 times more operations/$ compared to MongoDB Atlas for the small scaling size and 18 times more operations/$ for the scaling sizes medium and large.

For the hotspot distribution, the results show a similar trend where ScyllaDB provides 16 times more operations/$ for the small scaling size and 20 times for the medium scaling size.

Latency Results for MongoDB vs ScyllaDB
The P99 latency results for the uniform distribution show that ScyllaDB and MongoDB provide stable P99 read latencies. Yet, the values for ScyllaDB are constantly lower compared to the MongoDB latencies. An additional insight is that the ScyllaDB read latency doubles from medium to large (from 8.1 to 16.1 ms). The MongoDB latency decreases by 1 millisecond (from 23.3 to 22.3 ms), but still does not match the ScyllaDB latency.
For the update latencies, the results show a similar trend as for the social workload where ScyllaDB provides stable and low update latencies while MongoDB provides up to 73 times higher update latencies.
For the hotspot distribution, the results show a similar trend as for the uniform distribution. Both databases provide stable read latencies for the small and medium scaling size with ScyllaDB providing the lower latencies.
For updates, the ScyllaDB latencies are stable across the scaling sizes and slightly lower than for the uniform distribution. Compared to ScyllaDB, the MongoDB update latencies are 25 times higher for the small scaling size and 44 times higher for the medium scaling size respectively.


Technical Nugget A – 12 Hour Benchmark
In addition to the default 30 minute benchmark run, we also select the scaling size large with the uniform distribution for a long-running benchmark of 12 hours.
For MongoDB, we select the determined 8 YCSB instances with 100 threads per YCSB instance and run the caching workload in uniform distribution for 12 hours with a target throughput of 40 kOps/s.

The throughput results show that MongoDB provides the 40 kOps/s constantly over time as expected.
The P99 read latencies over the 12 hours show some peaks in the latencies that reach 20ms and 30ms and an increase of spikes after 4 hours runtime. On average, the P99 read latency for the 12h run is 8.7 ms; for the regular 30 minutes run, it is 5.7 ms.
The P99 update latencies over the 12 hours show a spiky pattern over the entire 12 hours with peak latencies of 400 ms. On average, the P99 update latency for the 12h run is 163.8 ms while for the regular 30 minutes run it is 35.7 ms.


For ScyllaDB, we select the determined 16 YCSB instances with 200 threads per YCSB instance and run the caching workload in uniform distribution for 12 hours with a target throughput of 500 kOps/s.
The throughput results show that ScyllaDB provides the 500 kOps/s constantly over time as expected.

The P99 read latencies over the 12 hours stay constantly below 10 ms except for one peak of 12 ms. On average, the P99 read latency for the 12h run is 7.8 ms.
The P99 update latencies over the 12 hours show a stable pattern over the entire 12 hours with an average P99 latency of 3.9 ms.


Technical Nugget B – Insert Performance
In addition to the three defined workloads, we also measured the plain insert performance for the small scaling size (500 GB), medium scaling size (1 TB) and large scaling size (10 TB) into MongoDB and ScyllaDB. It needs to be emphasized that batch inserts were enabled for MongoDB but not for ScyllaDB (since YCSB does not support it for ScyllaDB).
The following results show that for the small scaling size, the achieved insert throughput is on a comparable level. However, for the larger data sets of the medium and large scaling sizes, ScyllaDB achieves a 3 times higher insert throughput for the medium size benchmark. For the large-scale benchmark, MongoDB was not able to fully ingest the full 10TB of data due to client side errors, resulting in only 5TB inserted data. Yet, ScyllaDB outperforms MongoDB by a factor of 5.

Technical Nugget C – Client Consistency Performance Impact
In addition to the standard benchmark configurations, we also run the caching workload in the uniform distribution with weaker consistency settings. Namely, we enable MongoDB to read from the secondaries (readPreference=secondarypreferred) and for ScyllaDB we set the readConsistency=ONE.
The results show an expected increase in throughput: for ScyllaDB 23% and for MongoDB 14%. This throughput increase is lower compared to the client consistency impact for the social workload since the caching workload is only a 50% read workload and only the read performance benefits from the applied weaker read consistency settings. It is also possible to further increase the overall throughput by applying weaker write consistency settings.

Continue Comparing ScyllaDB vs MongoDB
Here are some additional resources for learning about the differences between MongoDB and ScyllaDB:
- Benchmarking MongoDB vs ScyllaDB: Results from benchANT’s complete benchmarking study that comprises 133 performance and scalability measurements that compare MongoDB against ScyllaDB.
- A Technical Comparison of MongoDB vs ScyllaDB: benchANT’s technical analysis of how MongoDB and ScyllaDB compare with respect to their features, architectures, performance, and scalability.
- ScyllaDB’s MongoDB vs ScyllaDB page: Features perspectives from users – like Discord – who have moved from MongoDB to ScyllaDB.



