



Why distribute aggregates in a distributed database?
Have you ever tried to run SELECT COUNT(*) on a table with millions of rows? If you don’t increase the timeout drastically, you’ve probably seen your query time-outing. Does it mean the database cannot count? Not exactly.
In the world of data-intensive applications, efficient data processing and analysis is essential. As datasets continue to grow exponentially, traditional monolithic databases face significant challenges in handling complex queries and aggregations within reasonable timeframes.
However, distributed databases make new solutions possible, offering a scalable and efficient solution to tackle these obstacles. By distributing aggregation calculations across multiple nodes, the workload can be parallelized, resulting in considerably faster query processing times.
In this blog, we explore the merits of distributing aggregates in a distributed database, delving into the benefits it provides and shedding light on the mechanisms we used to enable this transformative capability in ScyllaDB Let’s embark on a journey to uncover the secrets behind distributing aggregation calculations and how it can revolutionize the efficiency of query execution.
How does distributed aggregration work?
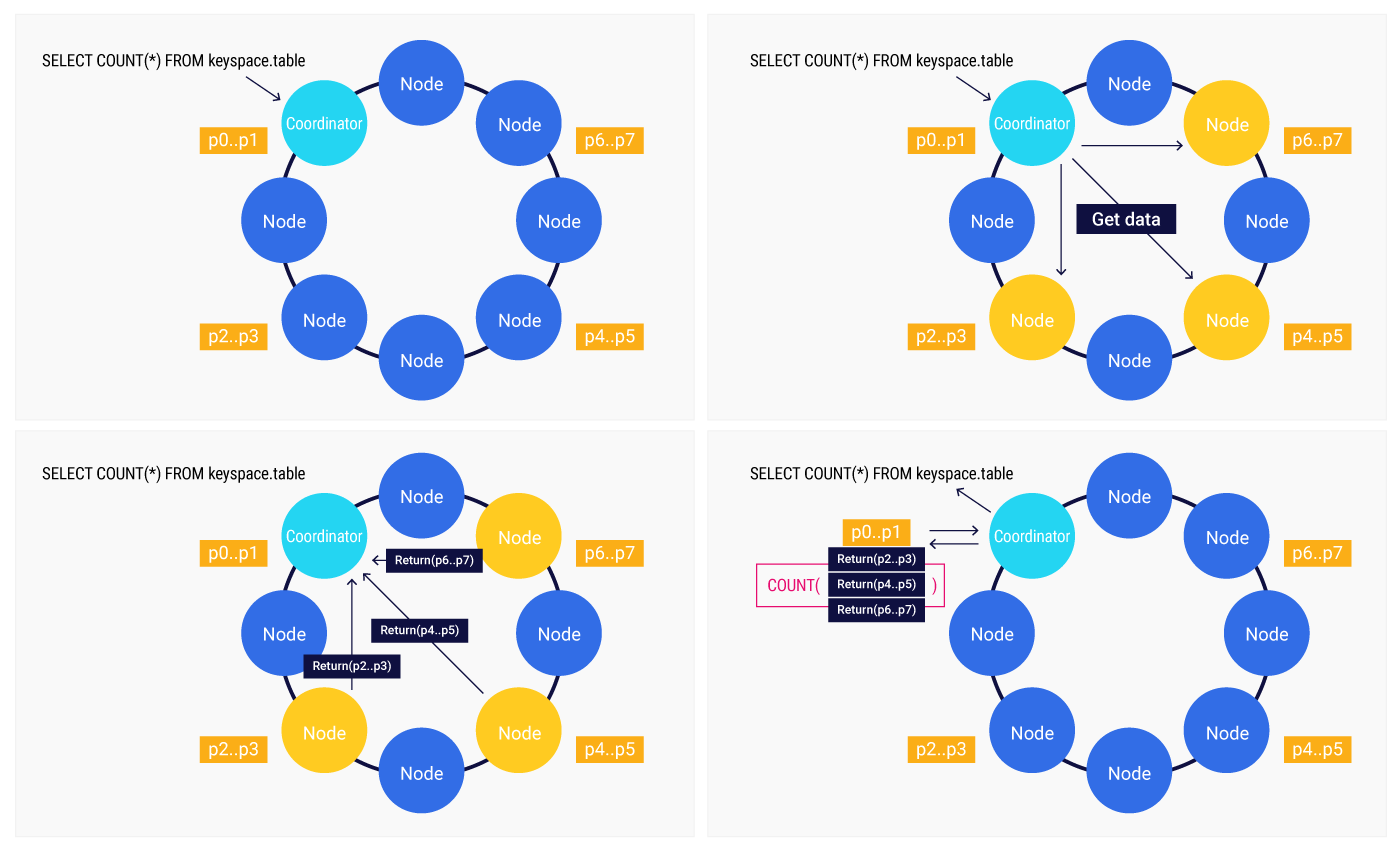
To better understand why the distribution of the aggregation is so beneficial, let’s start by reviewing how aggregation queries traditionally work.
When the node receives the query, it becomes the coordinator. This coordinator node is responsible for requesting data from all other nodes in the cluster and retrieving the necessary information for the aggregation calculation. Subsequently, the coordinator node downloads the data from the other nodes and performs the aggregate calculation locally, combining all the data to generate the final result.
This approach, while functional, presents certain limitations. The workload is concentrated on a single node, potentially leading to performance bottlenecks and increased query response times.
By distributing the aggregation calculations, a different approach is applied. The node that receives the query acts as the “super-coordinator” in this scenario. Instead of retrieving all the data and performing the aggregation locally, the super-coordinator divides the query into subqueries and dispatches them to the respective nodes in the cluster. Each individual node calculates the aggregate solely based on its local data, leveraging the distributed nature of the database. After completing the calculation, each node returns its partial result to the super-coordinator. Finally, the super-coordinator merges all the partial results received from the nodes, combining them into the final result.
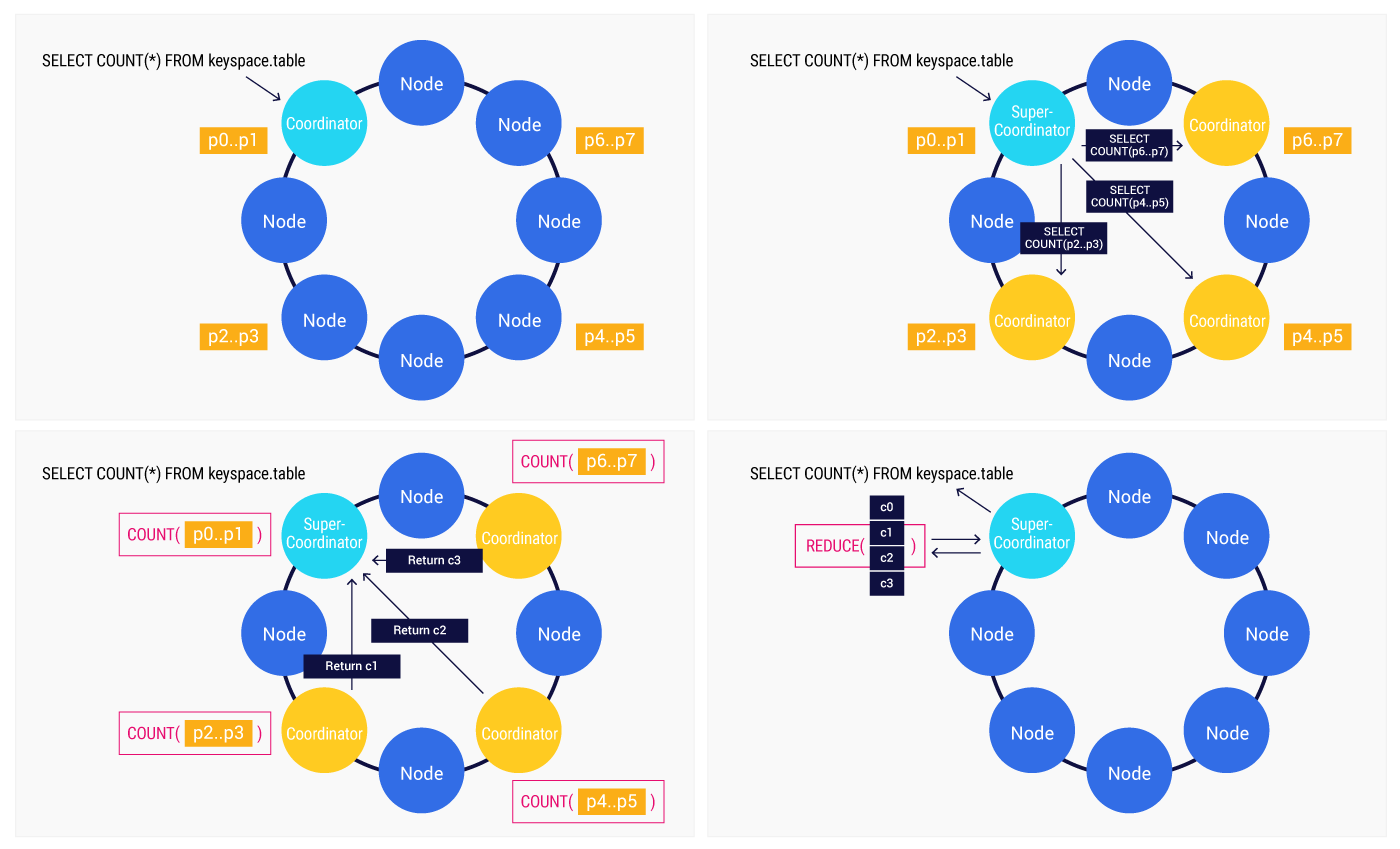
This distributed approach ensures that the workload is balanced across multiple nodes, leading to improved query performance and more efficient utilization of the cluster’s resources.
Native Aggregates and User-Defined Aggregates
As mentioned previously, the aggregate distribution requires the database to be able to calculate partial results and to merge them into the final result of the query. In ScyllaDB, we can distinguish two types of aggregations. First, there are native aggregates implemented in the database itself:
- COUNT
- SUM
- MIN/MAX
- AVG
In order to distribute those aggregates, we have simply extended the implementation of them.
The second type of aggregates are User-Defined Aggregates (UDA). UDAs enable the database users to create specialized calculations and operations tailored to their specific needs, going beyond built-in aggregates. This flexibility allows users to leverage their domain-specific knowledge and requirements, enabling complex calculations and statistical analyses on groups of data within their database.
To be able to distribute a UDA, its definition was extended with an optional parameter `REDUCEFUNC`.
The “reduce function” is a user-defined function (UDF) which shows how to merge two partial results into a new one. The signature of the function must be: (state_type, state_type) -> state_type.
Handling failures
In a distributed system, where multiple nodes collaborate to perform tasks and store data, the possibility of failures is an inherent reality that must be taken into account. Despite the advantages and scalability offered by distributed systems, the complexity of coordinating various nodes introduces potential points of failure.
Considering the case of distributed aggregates, any of the subqueries to other nodes may fail for a variety of reasons. When a failure occurs, the super-coordinator takes responsibility for the subquery and executes on its behalf. This way, the super-coordinator may choose another alive replica of the subquery data range.
If retrying the failed subquery also fails, the whole aggregation query will fail as well.
Calculating TOP 3 elements
Let’s see how to create a UDA that calculates the top 3 elements and can be distributed. First, we need to create a state function, which takes an accumulator and a value and returns a new accumulator:
The function simply adds a `val` to the current accumulator, sorts it and removes the fourth element if needed.
With the `state_f` function, we are able to create a non-distributed UDA calculating the top 3. But we’d like to leverage distributed aggregation, so we also need a reduce function:
Because the type of accumulator matches the type we want the UDA to return, we can create the final UDA now:
Benchmarks
We’ve compared distributed aggregates with non-distributed (sequential) ones. The benchmark specification was:
- 3 node cluster on AWS
- Instances: i3.4xlarge (16 vCPUs, memory 112 GiB)
- 50 millions rows
- Queries executed with “BYPASS CACHE”
Here are the benchmark results:

As you can see, the improvement on execution time is significant both in native and user-defined aggregations. It’s up to 20X faster.
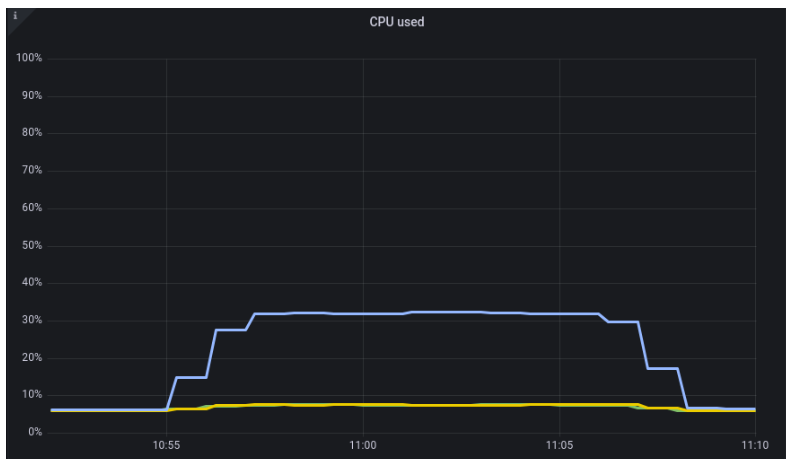
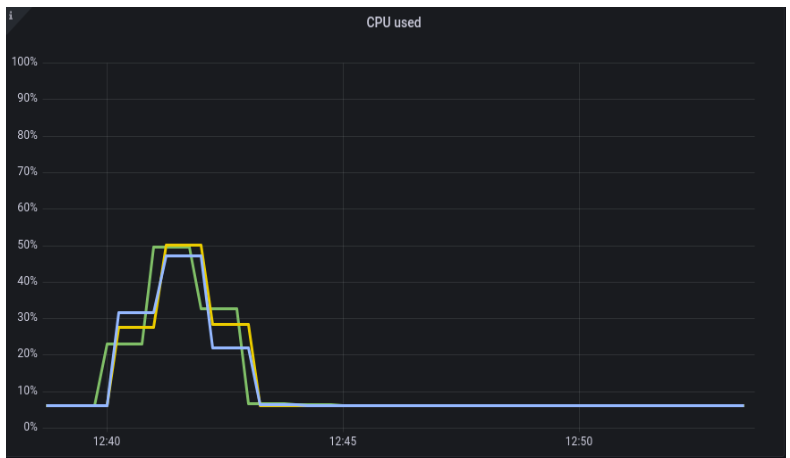
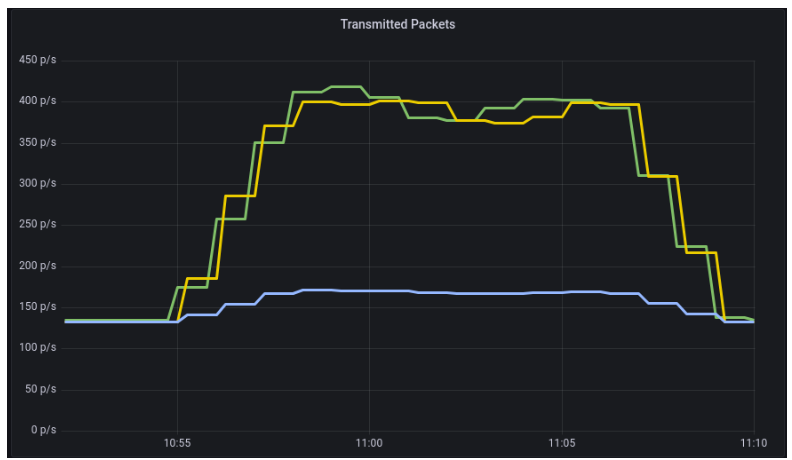
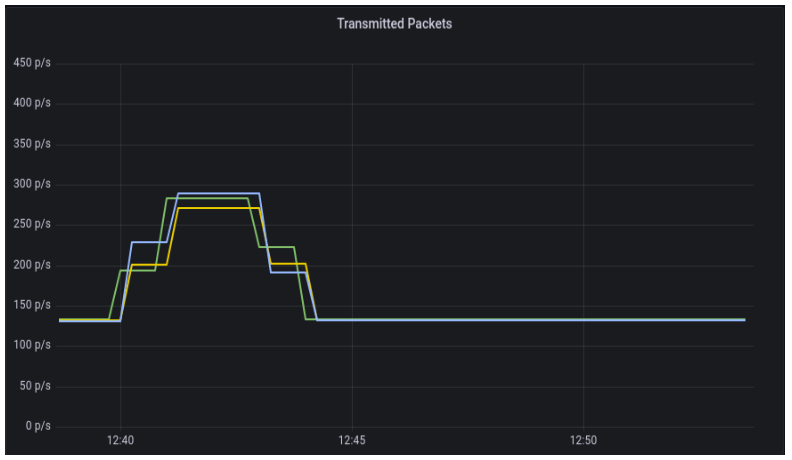
Another difference can observed in network traffic. In a sequential aggregation, we need to send data from all other nodes to the coordinator, which generates lots of traffic. On the other hand, we are sending only subqueries and their results during the distributed execution of aggregation.
Limitations
It’s important to note that there are some limitations to which aggregation queries can be distributed. ScyllaDB cannot distribute queries with WHERE clause (filtering) or GROUP BY clause (grouping). This filtering limitation is strictly a technical issue with serializing the query. To allow grouping in distributed aggregates we would need to introduce a temporary table mechanism, as the partial results from a node could contain multiple rows that could potentially be required to be stored on disk.
Learn about more performance optimizations…at P99 CONF
Editor’s note: Michał first presented his work on these optimations at P99 CONF 2022. You can watch his talk, and over a hundred others, on-demand at the P99 CONF site. Also, if you enjoy learning about low-latency engineering, and performance optimizations, join us for P99 CONF 2023. It’s free + virtual…and registration is now open.


