Much has changed since the first ever ScyllaDB Summit, when ~100 people gathered in San Jose, CA in 2016. The ScyllaDB database, company, and community have all developed quite substantially. But one thing remains the same: my favorite part of the event is hearing about what our users are achieving with ScyllaDB.
I want to share some of the highlights from these great tech talks by our users, and encourage you to watch the ones that are most relevant to your situation. As you read/watch, you will notice that some of the same themes appear across multiple talks:
- Sheer scale, latency, and throughput stories
- Migration from other good databases that couldn’t tackle all of the performance, availability, and replication needs
- NVMe caching (not a surprise, we plan on doing it ourselves)
- Elimination of event streaming/queuing by using ScyllaDB
ZeroFlucs
About: ZeroFlucs’ technology enables bookmakers and wagering service providers to offer same-game betting. Their simulation-based architecture enables unique and innovative bet types that maximize profits for bookmakers as well as engage end users.
Use Case: Customer Experience
Takeaways: ZeroFlucs first caught our attention by publishing a blog on Charybdis: a cleverly named library that they created to “simplify and enhance the developer experience when working with ScyllaDB in Go.” We invited them to ScyllaDB Summit to share more about this “other sea monster” as well as their broader ScyllaDB use case – and their Director of Software Engineering, Carly Christensen, joined us to share their story.
In short, ZeroFlucs uses a really smart approach to figuring out exactly how data should be replicated to support low latency for their global usage patterns without racking up unnecessary storage costs. Their business is processing sports betting data, and it’s extremely latency sensitive. Content must be processed in near real-time, constantly, and in a region local to both the customer and the data. And they face incredibly high throughput and concurrency requirements – events can update dozens of times per minute and each one of those updates triggers tens of thousands of new simulations (they process ~250,000 in-game events per second).
They considered MongoDB, Cassandra, and Cosmos DB, and ultimately selected ScyllaDB due to it meeting their performance and regional distribution requirements at a budget-friendly cost. Carly walked us through the ScyllaDB setup they use to keep data local to customers, and also talked about the Charybdis (open source) library that they created to orchestrate the management of keyspaces across their many global services.

Discord
About: Discord is “a voice, video and text app that helps friends and communities come together to hang out and explore their interests — from artists and activists, to study groups, sneakerheads, plant parents, and more. With 150 million monthly users across 19 million active communities, called servers, Discord has grown to become one of the most popular communications services in the world.”
Use Case: Customer Experience
Migration: MongoDB to Cassandra, then to ScyllaDB
Takeaways: ScyllaDB and Discord have worked closely for many years as both organizations grew. I was thrilled when they finally moved 100% from Cassandra to ScyllaDB – and even more excited to hear that they would be sharing their experiences with our community in two great ScyllaDB Summit talks.
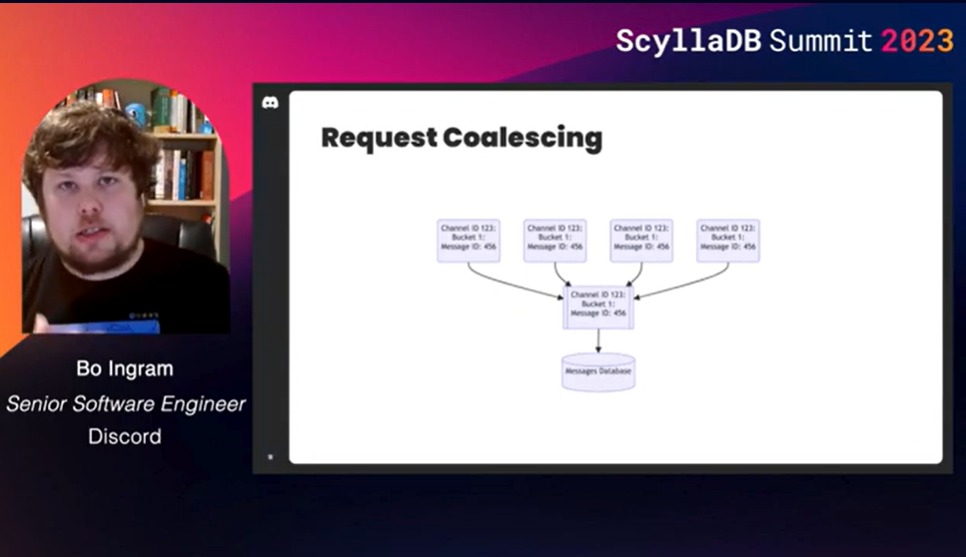
First, Bo Ingram shared how Discord stores trillions of messages on ScyllaDB. He explained their reasons for moving from Apache Cassandra to ScyllaDB, their migration strategy, the role of Rust, and how they designed a new storage topology – using a hybrid-RAID1 architecture – for extremely low read latency on GCP. There’s even a great World Cup example at the end!
Stephen Ma also took a technical deep dive into Discord’s approach to more quickly and simply onboarding new data storage use cases. Discord developed a key-key-value store service that abstracts many ScyllaDB-specific complexities–like schema design and performance impacts from tombstones and large partitions–from developers. (Note: ScyllaDB has addressed many of those shortcoming in our recent releases).
Discord just wrote a great blog about this massive achievement. Give it a read!
Watch Discord’s talk (Stephen)
Epic Games
About: Epic Games develops Unreal Engine, the 3D engine that powers the world’s leading games (e.g., Fortnite) and is used across industries such as film and television, architecture, automotive, manufacturing, and simulation. With 7.5 million active developers, the Unreal Engine is one of the world’s most popular game development engines.
Migration: DynamoDB to ScyllaDB
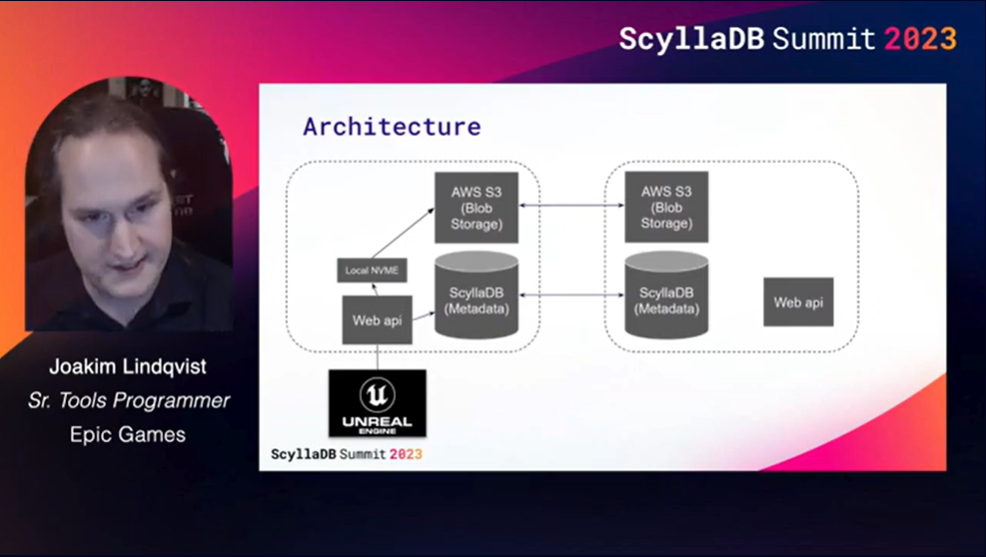
Takeaways: Epic Games uses ScyllaDB as a binary cache in front of NVMe and S3 to accelerate global distribution of large game assets used by Unreal Cloud DDC (the asset caching system Unreal Engine). The cache is used to accelerate game “cook time” – taking texture + mesh and converting it to a specific platform like PlayStation 5 or Xbox. A developer does this once, then it’s replicated across the world.
They store structured objects with blobs that are referenced by a content hash. The largest payload is stored within S3, whereas the content hash is stored in ScyllaDB. When Unreal Engine goes to ScyllaDB to fetch the metadata, they get sub-millisecond responses. They selected ScyllaDB for a number of reasons. They started looking for alternatives to DynamoDB in search of cloud agnosticity. DynamoDB was simple to adopt, but they later realized the value of having a database that was not tied to any particular cloud provider and can also work on-premises. Looking at ScyllaDB, they found that the lower latency was a better match for their performance-sensitive workload and the cost was much lower as well.
Numberly
About: Numberly is a digital data marketing technologist and expert helping brands connect and engage with their customers using all digital channels available. They are proud to be an independent company with solid internationally recognized expertise in both marketing and technology – and they just celebrated their 23rd anniversary!
Use case: Recommendation & Personalization
Migration: Kafka + Redis to ScyllaDB
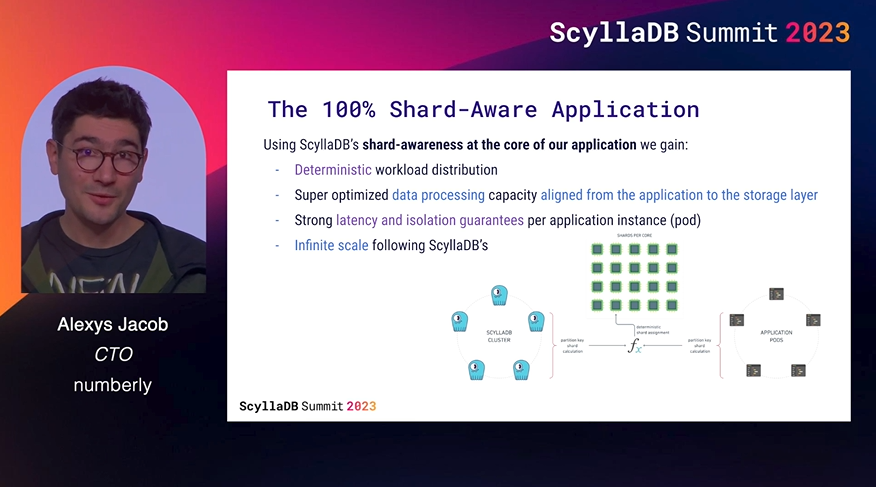
Takeaways: Numberly’s team are longtime ScyllaDB power users and dedicated community contributors. They continuously push the boundaries of what is possible, and their latest “crazy idea” to replace Kafka and Redis with a (Rust-based) ScyllaDB shard-aware application is no exception. It’s an impressive example of how, in many situations, you don’t need a Kafka queue (or Redis cache) and use a lookup into ScyllaDB itself.
With ScyllaDB as their only backend, they managed to reduce operational costs while benefiting from core architectural paradigms like predictable data distribution and processing capacity, idempotence. I have to admit that I am personally quite proud to see this cool new use of ScyllaDB’s shard-per-core architecture. 🙂 I hope it inspires others to use it for their own trailblazing projects.
ShareChat
About: ShareChat provides India’s leading multilingual social media platform (ShareChat) and India’s biggest short video platform (Moj). ShareChat serves 180M Monthly Active Users and Moj serves 300M Monthly Active Users. Together, they are changing the way the next billion users will interact on the internet.
Migration: Their cloud provider’s DBaaS + some Cassandra instances to ScyllaDB
Use Case: Customer Experience
Takeaways: This is a team with a lot of achievements to share! Just a couple months ago, ShareChat’s Geetish Nayak provided an overview of their rapid ScyllaDB ramp up and expansion to ~50 use cases in a detailed webinar. And now they shared two more technical talks at ScyllaDB Summit.
Charan Movva talked about ShareChat handles the aggregations of a post’s engagement metrics/counters at scale with sub-millisecond P99 latencies for reads and writes (note that they operate at the scale of 55k-60k writes/sec and 290k-300k reads/sec, respectively). By rethinking how they handle events – by using ScyllaDB with their existing Kafka Streams – they were to maintain ultra-low latency while reducing database costs by at least 50%.
Anuraj Jain and Chinmoy Mahapatra also introduced us to the live migration framework they designed to move ~100TB of raw data for their various use cases over to ScyllaDB without downtime or even any noticeable latency hits. It’s a very rich framework, with support for both counter and non-counter use cases, support for Go, Java, and Node.js, fallback, recovery, auditing, and support for many corner cases. If you’re thinking of moving data into ScyllaDB, definitely take a look. I’m truly amazed by what this entire team has achieved so far and look forward to partnering with them on what’s next.

Watch ShareChat’s talk (Charan)
Watch ShareChat’s talk (Anuraj and Chinmoy)
SecurityScorecard
About: SecurityScorecard aims to make the world a safer place by transforming the way thousands of organizations understand, mitigate, and communicate cybersecurity. Their rating platform is an objective, data-driven and quantifiable measure of an organization’s overall cybersecurity and cyber risk exposure.
Migration: Redis, Aurora, and Presto + HDFS to ScyllaDB and Presto + S3
Use case: Fraud & thread detection
Takeaways: You can read the explanation before or just skip to their results slide that speaks for itself.
This is the first migration from Redis and Aurora to ScyllaDB that I’m aware of. Some data modeling work was required, but there were strong payoffs. Their previous data architecture served them well for a while, but couldn’t keep up with their growth. Their platform API queried one of three data stores: Redis (for faster lookups of 12M scorecards), Aurora (for storing 4B measurement stats across nodes), or a Presto cluster on HDFS (for complex SQL queries on historical results).
As data and requests grew, challenges emerged. Aurora and Presto latencies spiked under high throughput. The largest possible instance of Redis still wasn’t sufficient, and they didn’t want the complexity of working with Redis Cluster. To reduce latencies at their new scale, they moved to ScyllaDB Cloud and developed a new scoring API that routed less latency-sensitive requests to Presto + S3 storage. Look at the slide below to see the impact:
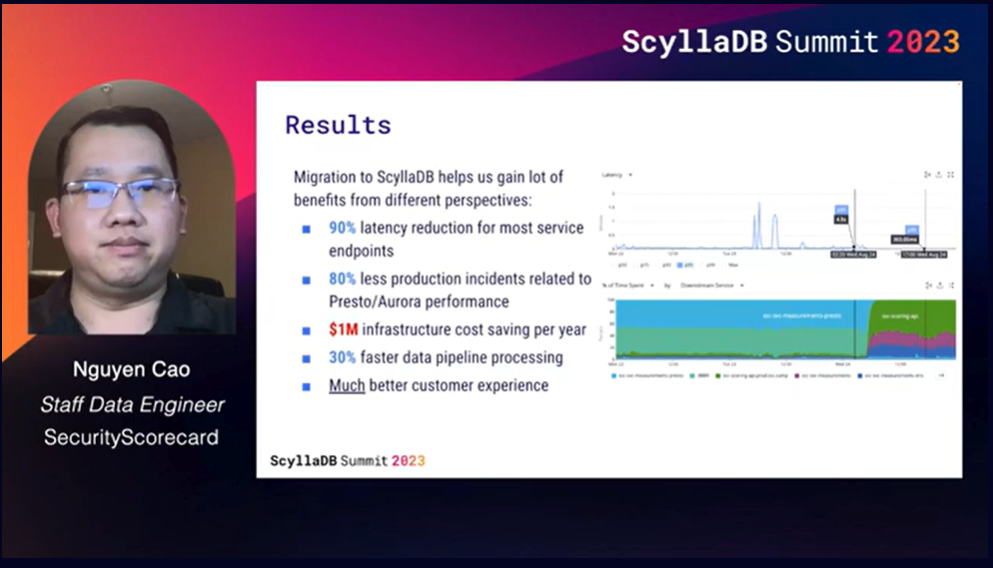
Watch SecurityScorecard’s talk
Strava
About: Strava is the largest sports community in the world. Strava’s platform enables 100M+ athletes across 195 countries to connect and compete by sharing data collected via 400+ types of devices throughout the day.
Use Case: IoT
Migration: Cassandra to ScyllaDB
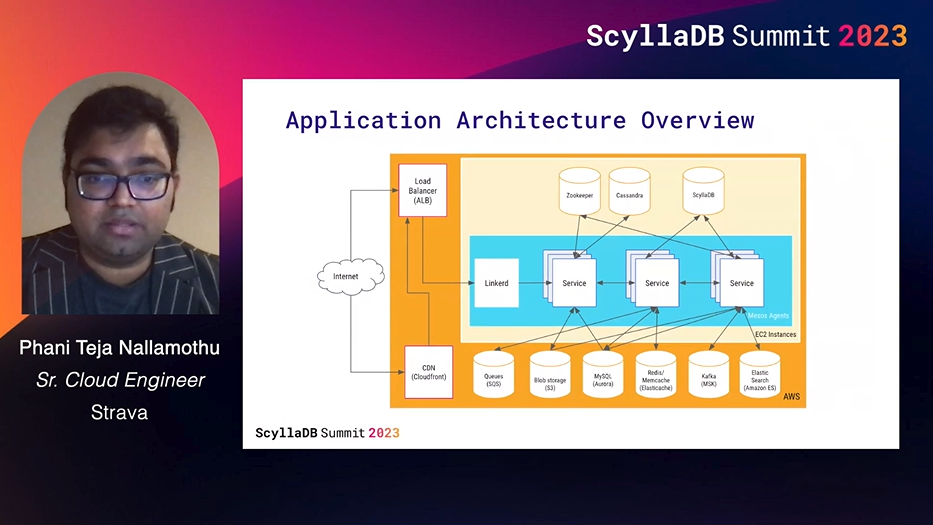
Takeaways: As an avid mountain biker, I’m quite a fan of Strava – so it was fun to see the architecture behind Strava platform’s segment tracking, matched rides, performance metrics, route discovery, etc. After an overview of the overall architecture, Phani Teja talked about a few of the use cases they recently moved from Cassandra to ScyllaDB. Horton is a flexible scalar value store for activity data such as distance, max/avg speed, max/avg heart rate, bikeID, shoeID, and so on. Segments is a write-heavy use case that stores athletes’ progress reports on segments and loads them into their feeds. And Neogeo is read-heavy (with a fair volume of writes) use case that stores encoded map styles for static images.
I was pleased to see that they are using the powerful new I4i instances, which ScyllaDB can take great advantage of. They use i4i.large all the way through i4i.8xlarge, and they vary those instances based on the load prediction.
Level Infinite
About: Level Infinite is the global game publishing division of Tencent Games, the world’s leading video game platforms. Some of the titles they are currently running include PUBG Mobile, Arena of Valor, and Tower of Fantasy.
Use case: Analytics
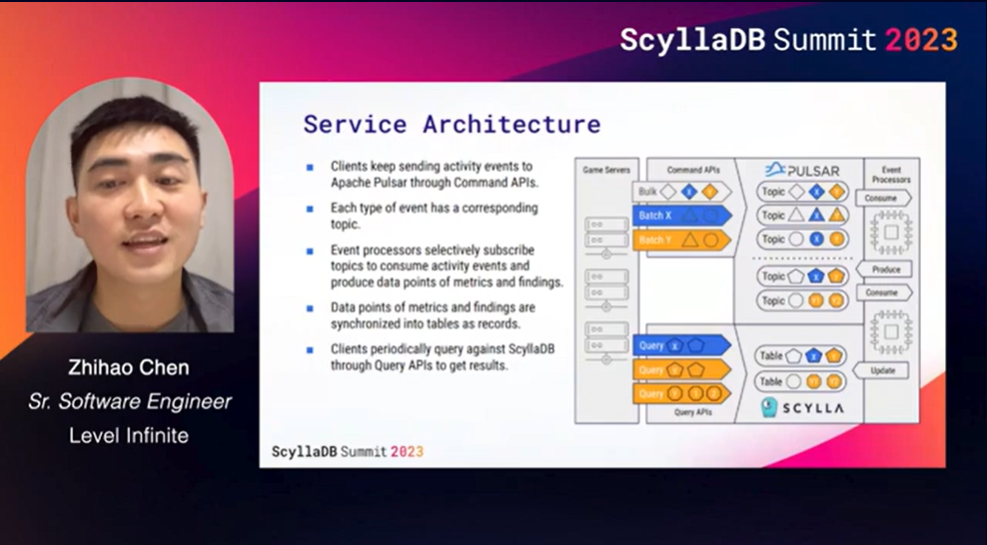
Takeaways: This talk explains how Level Infinite uses ScyllaDB along with Apache Pulsar to solve the problem of dispatching events to numerous gameplay sessions. It’s for a very interesting use case: monitoring and responding to risks that can occur in Tencent games – for example, cheating and harmful content.
Fully aware that using Cassandra as a distributed queue has historically been considered an antipattern, they recognized the potential to defy expectations here and they architected a great solution. In particular, I encourage you to look at their “pseudo-now” approach to finding new events even when events are not committed to ScyllaDB in the order indicated by the event id.
Coralogix
About: DevOps and Security engineers around the world use Coralogix’s real-time streaming analytics pipeline to monitor their stacks and fix production problems faster. Their ML algorithms continuously monitor data patterns and flows between system components and trigger dynamic alerts.
Use Case: Data ingest and storage
Migration: Postgres to ScyllaDB
Takeaways: The spoiler alert here is that Coralogix shrank query processing times for their next generation distributed query engine from 30 seconds (!!!) to 86 ms by moving from PostgreSQL to ScyllaDB. The engine queries semi-structured data and the underlying data is stored in object storage (e.g., EBS, S3) using a specialized Parquet format. It was originally designed as a stateless query engine on top of the underlying object storage, but reading Parquet metadata that way was too much of a latency hit.
So, they developed a “metastore” that would take the Parquet metadata needed to execute a large query and put it into a faster storage system that they could query quickly. The work is technically impressive – listen to the different components of Parquet’s metadata that needed to be queried together to retrieve data from 50,000 Parquet files.
They moved from first discovering ScyllaDB to getting into production with terabytes of data within just 2 months (and this was a SQL to NoSQL migration requiring data modeling work vs a simpler Cassandra or DynamoDB migration).

Beyond ScyllaDB Adoption/Migration Stories
To conclude, I also want to encourage you to watch two other awesome talks presented by ScyllaDB users.
Optimizely
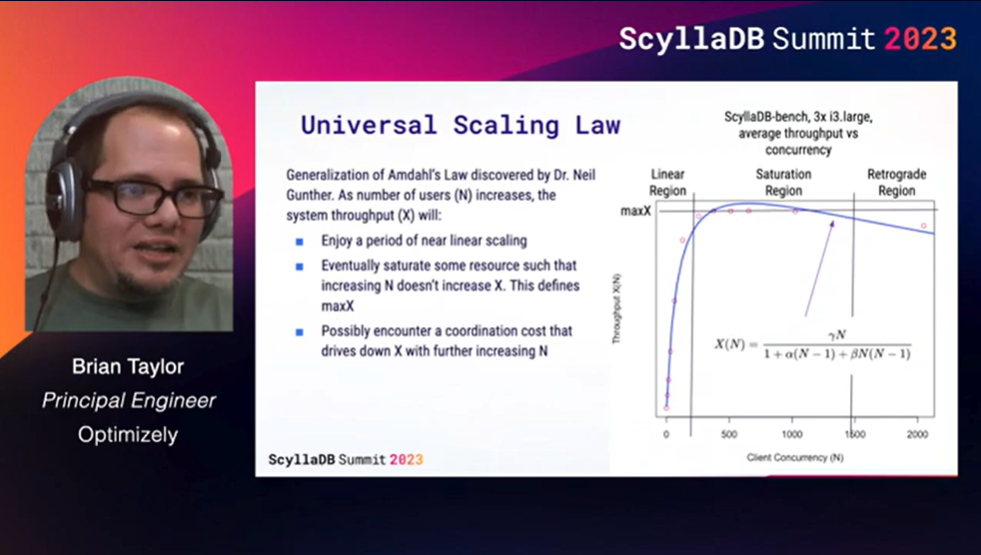
Brian Taylor from Optimizely shared their tips for getting the most out of ScyllaDB’s “amazing” concurrency (his word, not mine – but I do agree). It’s a really smart technical presentation; I think anyone considering or using ScyllaDB should watch it very carefully.
iFood
Also, if you’re working with (or curious about) Quarkus, take a look at the nice live-coding Quarkus + ScyllaDB session by iFood’s João Martins!