





Day 1 of ScyllaDB Summit was an exercise in extremes.
On the one hand, it was all about massive scale. Moving trillions of messages from Cassandra to ScyllaDB. Tracking activity data for the world’s largest sports community, 100 million strong. And amping up the flexibility and elasticity for ScyllaDB’s monstrously fast and scalable database.
But it was also about less. Reducing costs with an open source DynamoDB API, object storage, and impressive price performance. Fewer literal “Cassandra migraines.” And freedom from worrying about database sizing and servers.
There were more engineering talks than attendees had time to watch – and Day 2 brings access to 14 more time-boxed talks, as well as 10 additional instant access talks. This blog provides a quick look at the Day 1 keynotes and a gallery of highlights from the parallel track talks.
Update: ScyllaDB Summit 2023 is now complete. All the on-demand recordings and speaker slide decks are available now.
To Serverless and Beyond
Dor Laor, ScyllaDB
ScyllaDB co-founder and CEO, Dor Laor, kicked off the event with his perspective on ScyllaDB past, present, and future. “ScyllaDB was born for brute power: to crush high OPS with a unique and innovative shard per core architecture,” Laor began. ScyllaDB, a high performance NoSQL Database, then rapidly evolved with Cassandra parity, an open source DynamoDB-compatible API, and a host of other unique capabilities for predictable low latencies at high throughput – with the industry’s top price performance.
Dor characterized ScyllaDB circa 2022 as an “all-weather, all-terrain high throughput, low latency database.” Major developments of 2022 include more gains from our relentless obsession with performance – including the fifth generation of our I/O scheduler, per-partition rate limiting (more on this during Day 2), highly-performant distributed aggregates, 2X throughput and lower latency on the AWS I4i instances and more. On the “ruggedness” front, there were also a host of maintenance improvements, including repair-based tombstone garbage collection. And there was impressive progress on our drive to bring strongly consistent features to ScyllaDB via Raft. Dor revealed a bit about what’s already here (safe schema changes) and what’s next (safe topology changes) then left the Raft deep dive in Kostja Osipov’s very capable hands.
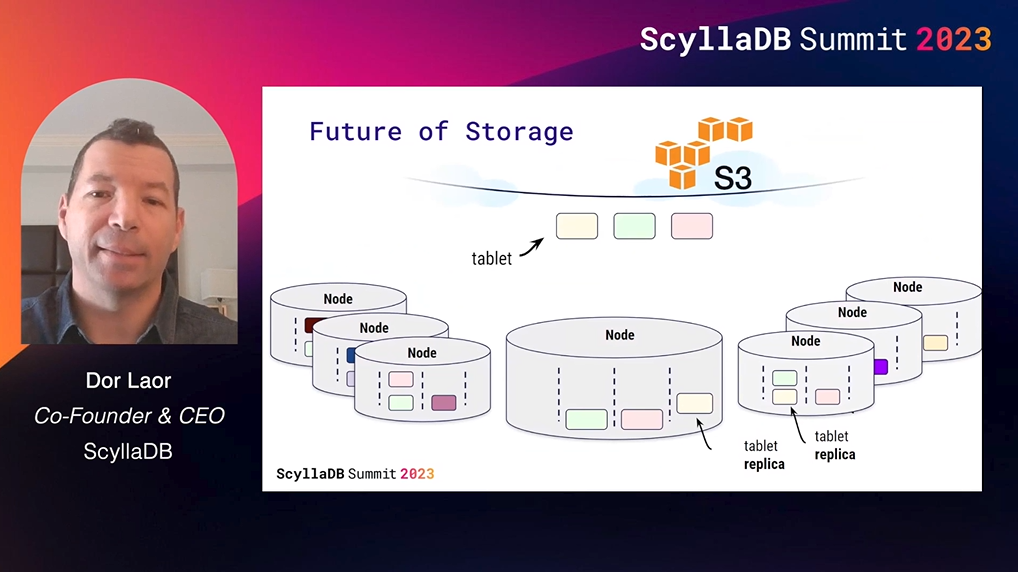
What’s next for ScyllaDB? Dor brought up three major initiatives: serverless, tablets, and object storage. Watch the session for Dor’s explanation of why these are the top properties on the roadmap.
How Discord Stores Trillions of Messages on ScyllaDB
Bo Ingram, Discord
Next, we learned why and how Discord’s persistence team recently completed their most ambitious migration yet: moving their massive set of trillions of messages from Cassandra to ScyllaDB. Bo Ingram, Senior Software Engineer at Discord, provided a technical look, including:
- Their reasons for moving from Apache Cassandra to ScyllaDB
- Their strategy for migrating trillions of messages
- How they designed a new storage topology – using a hybrid-RAID1 architecture – for extremely low latency on GCP
- The role of their existing Rust messages service, new Rust data service library, and new Rust data migrator in this project
- What they’ve achieved so far, lessons learned, and what they’re tackling next

ScyllaDB at Strava
Phani Teja Nallamothu, Strava
Strava, the largest sports community in the world, then took the stage to share their own large-scale Cassandra migration. Phani Teja Nallamothu started off by sharing the challenges involved in supporting 100 million athletes in ~200 countries as they track and compete on 30+ different activity types. He revealed what their underlying system architecture looks like, walking us through how the various components interconnect and where ScyllaDB fits in.
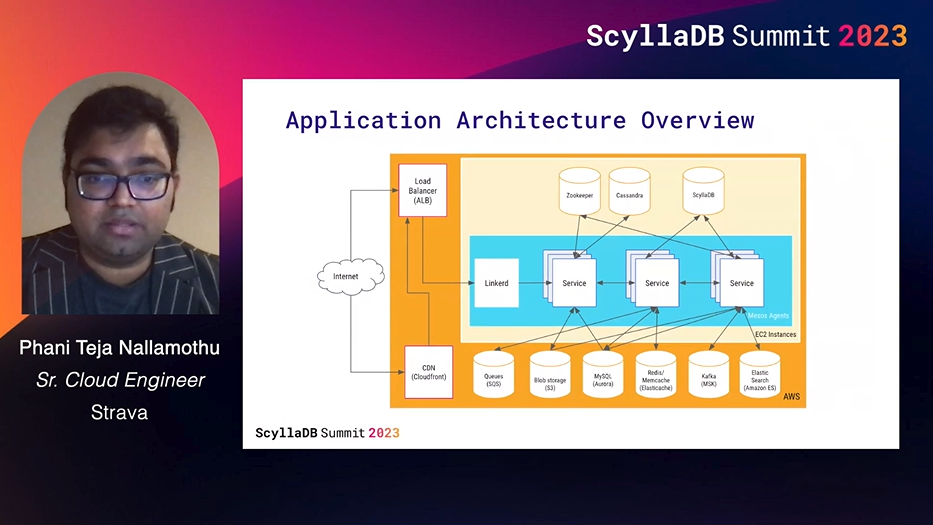
Nallamothu then provided a close look at Strava’s first ScyllaDB use case (a flexible scalar value store for activity data), including their approach to query analysis and data modeling. He then gave a glimpse at two of Strava’s other ScyllaDB use cases: one which stores athletes’ progress reports on segments, and another that stores encoded map styles for static images. The session wrapped up with a look at why they moved from Cassandra to ScyllaDB, and the benefits they’ve experienced so far.
ScyllaDB 5.2 and Beyond: Fresh from the ScyllaDB Oven
Avi Kivity, ScyllaDB
Who can resist the lure of database innovations fresh from the oven? Avi Kivity, ScyllaDB co-founder and CTO, offered up a tantalizing assortment of new ScyllaDB capabilities that provide performance, resilience, and ecosystem advantages:
- Increasing streaming robustness
- Autoparallel queries
- WebAssembly (WASM) user-defined functions (UDFs)
- Per-partition throttling
- DynamoDB API (Alternator) updates
- Consistent schema and topology
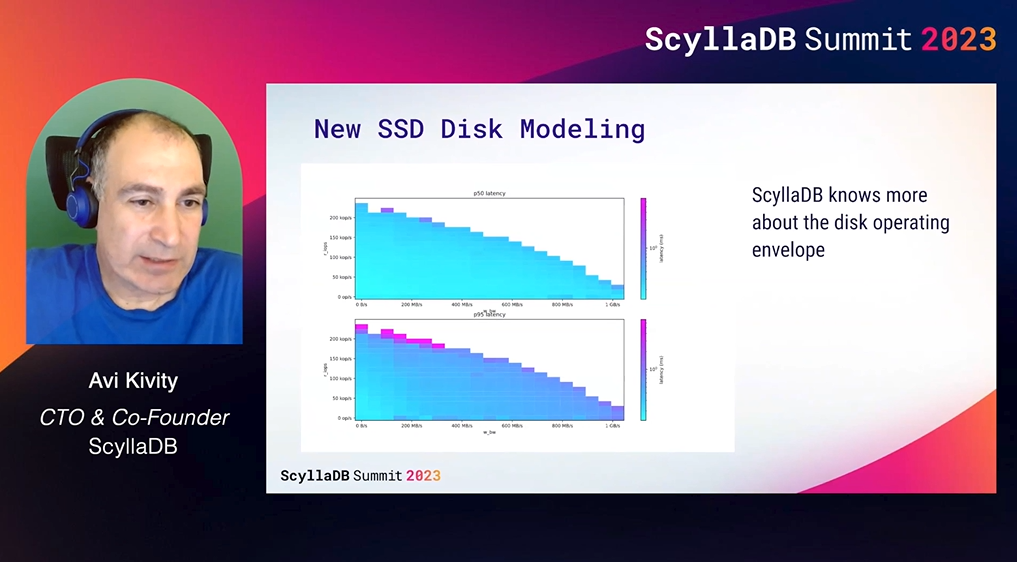
- New SSD disk modeling
Next, the focus shifted to how the team tamed a few troublesome corner cases: reverse queries, tombstone handling, out-of-memory handling, and repair-based tombstone garbage collection.
Finally, Avi provided a peek into two additional treats that the ScyllaDB engineering team is busy cooking up now: how the team is nudging the CQL grammar towards its SQL cousin, as well as a look at the tradeoffs and design decisions involved in ScyllaDB’s move to object storage with S3.
Use ScyllaDB to Replace Amazon DynamoDB: Everywhere, Better, More Affordable, All at Once
Tzach Livyatan, ScyllaDB
Despite the cinematic title, Tzach Livyatan didn’t opt for a cliffhanger ending in his keynote. Without even a spoiler alert, he started off with the conclusion – a conclusion so intriguing that it kept everyone on the edge of their seats, chatting off a flurry of questions and comments throughout the session:
- ScyllaDB is compatible with Amazon DynamoDB and can run on multiple platforms
- ScyllaDB is less expensive and has lower tail latency than Amazon DynamoDB
- You can migrate from Amazon DynamoDB to ScyllaDB without downtime
First up: a head-to-head faceoff between ScyllaDB and DynamoDB. Tzach shared some lessons learned that can save anyone benchmarking DynamoDB some headaches, then went into the results across a number of different scenarios. DynamoDB’s sweet spot proved to be read-heavy workloads, while ScyllaDB excelled in write-heavy workloads. Other takeaways: ScyllaDB experienced single-digit millisecond P99 latencies where DynamoDB was incurring double-digit ones. There was also a marked discrepancy on the cost. In one scenario with 50% reads and 50% writes at 100K OPS throughput, the annual reserved capacity cost for DynamoDB was nearly 10X that of ScyllaDB ($278,172 vs $29,172).

Tzach then talked a bit about DynamoDB pricing models (on-demand vs. provisioned) and the challenge of determining what provisioned capacity to set across your tables. For example, what if you have 9 tables, each with 20K sustained capacity – but any given table might peak to 100K for an hour or two per month or per day?
The latter half of the talk focused on reducing existing DynamoDB costs and latencies by migrating to ScyllaDB. Tzach introduced “Alternator,” ScyllaDB’s open source DynamoDB compatible API – which allows teams to take any application written for DynamoDB and run it against ScyllaDB on any public cloud or on-premises. Tzach then provided a quick look at strategies for migrating from DynamoDB to ScyllaDB and a look at what it’s like to work with ScyllaDB once you’ve migrated.
Parallel Track Session Highlights
Some highlights across the parallel track sessions…
Raft After ScyllaDB 5.2: Safe Topology Changes
Kostja Osipov shared what you need to know about ScyllaDB’s first use of Raft – for reliable propagation of schema changes – and what’s next on the path to strong consistency.

The Consistency vs Throughput Tradeoff in Distributed Databases
Daniel Abadi, the inventor of the PACELC theorem, explored whether there is a consistency vs throughput tradeoff in distributed database systems that guarantee ACID transactions.

Worldwide Local Latency With ScyllaDB
Carly Christensen shared how ZeroFlucs uses ScyllaDB and Go to offer low-latency data processing in a geographically distributed way, with each customer’s data always locally available.

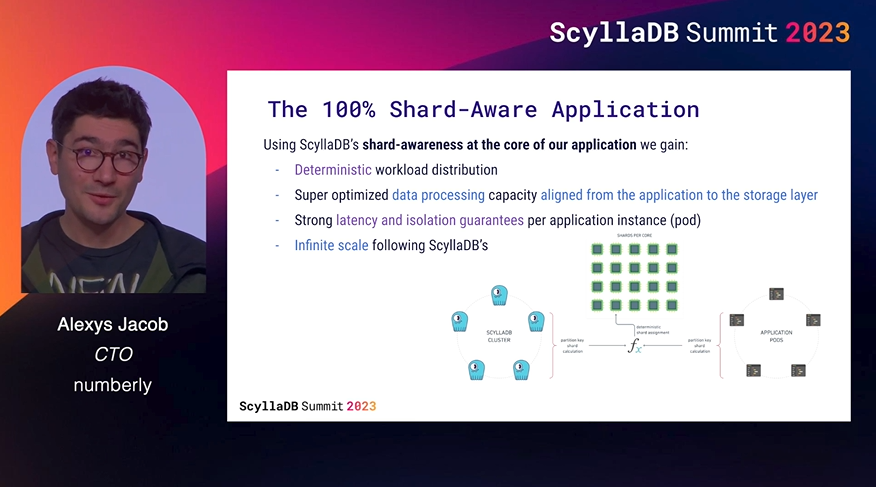
Building a 100% ScyllaDB Shard-Aware Application using Rust
ScyllaDB community superstar Alexys Jacob and his colleagues Yassir Barchi and Joseph Perez shared Numberly’s experience designing and operating a distributed, idempotent, and predictable application 100% based on ScyllaDB’s low-level shard-aware topology using Rust.
From Postgres to ScyllaDB: Migration Strategies and Performance Gains
Sebastian Vercruysse and Dan Harris shared how Coralogix – a full-stack observability platform – shrank query processing times from 30 seconds (not a typo) to 86 ms by moving from Postgres to ScyllaDB.

Maximum Uptime Cluster Orchestration with Ansible
Ryan Ross shared actionable tips and patterns to build confidence in orchestrating ScyllaDB in Production with Ansible– including specific code snippets you can use for inspiration.

Everything in its Place: Putting Code and Data Where They Belong
Code runs on computers and data is stored in databases. Right? Maybe. Brian Sletten, author of WebAssembly, The Definitive Guide, explored the changing trends and the issues with getting it wrong.
libSQL
Long-time ScyllaDB contributor Piotr Sarna shared an overview of the SQLite architecture and introduced us to his latest project: libSQL, an open-source fork of SQLite that accepts contributions, uses Rust for new features, and integrates with WebAssembly.

Key-Key-Value Store: Generic NoSQL Datastore with Tombstone Reduction and Automatic Partition Splitting
Stephen Ma shared Discord’s approach to more quickly and simply onboarding new data storage use cases with their key-value store service that hides many ScyllaDB-specific complexities from developers.
