ScyllaDB Open Source 5.1 is now available. It is a feature-based minor release for the ScyllaDB Open Source 5.0 major release of earlier this year. It also resolves over 100 issues, bringing improved capabilities, stability and performance to our NoSQL database server and its APIs.
DOWNLOAD SCYLLADB OPEN SOURCE 5.1 NOW
You can read the release notes to get all the details, but for now let’s go over the main new features.
Distributed SELECT COUNT (*)
Historically, we know full well that counting all the rows in a table can be slow. It can even result in a ReadTimeout error. This is because it does a full-scan query on all nodes. And while we’ve implemented USING TIMEOUT to alter the normal timeout of operations, wouldn’t it be better to just make the query run faster?
Well, now it is. Because in ScyllaDB Open Source 5.1 we’ve added a distributed SELECT COUNT feature. In the original implementation, the coordinator node sends a request and gets a count returned from one node, then asks the next node, and so on around the cluster ring sequentially. Each node needs to return a count to the coordinator before it goes on to ask the next node for its count. For a large cluster with many nodes, this can artificially bottleneck the process.
Starting with this release, we’ve created a new node role for such queries, known as the “super coordinator.” The query is divided into separate workloads, with each sent out from the super coordinator to other selected coordinator nodes around the cluster. The coordinators each work with a part of the overall query, polling the individual nodes where data is stored, then marshaling and returning results back to the super coordinator. The super coordinator gathers all the responses from the coordinators and then sends the collective SELECT COUNT response back to the client.
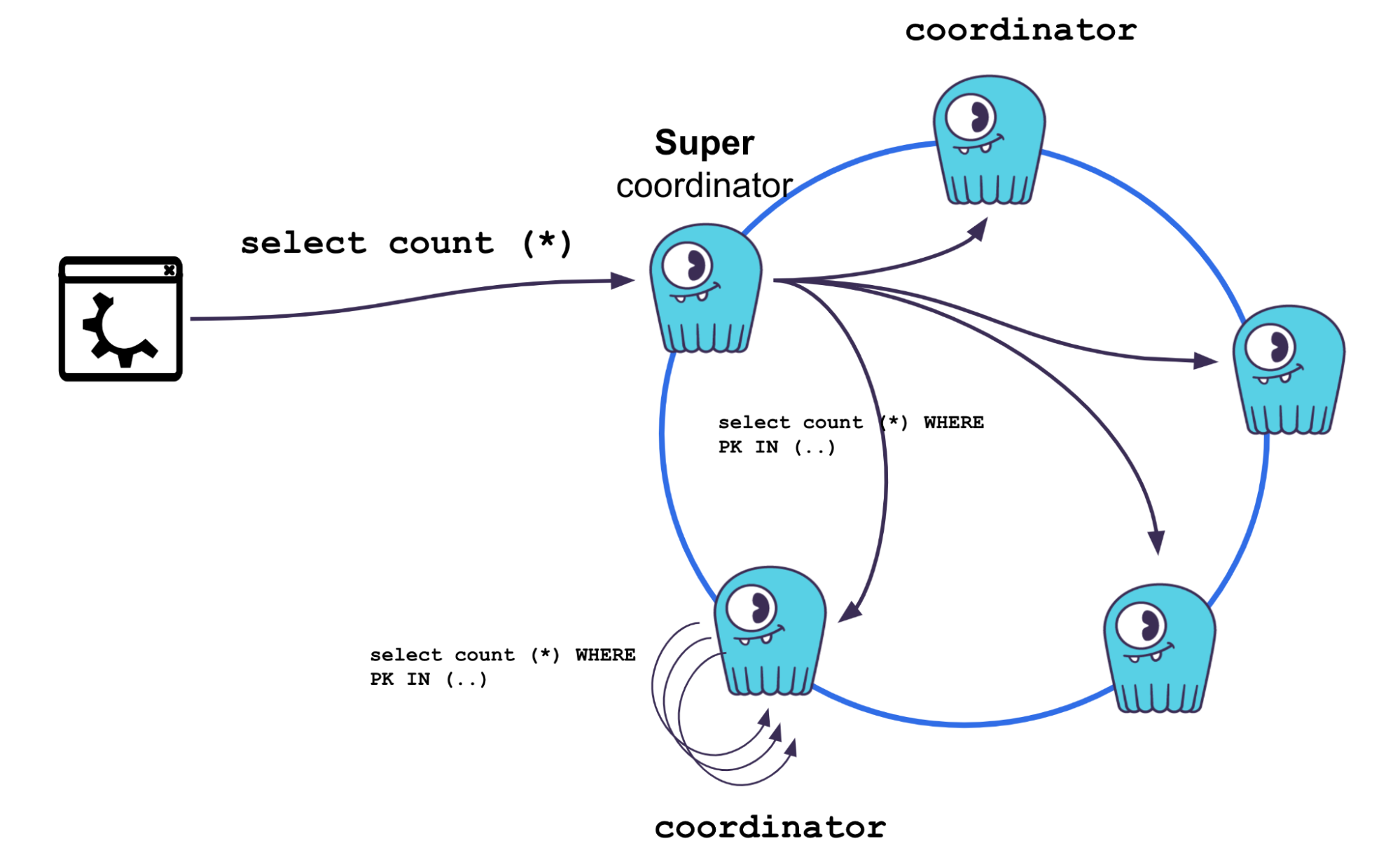
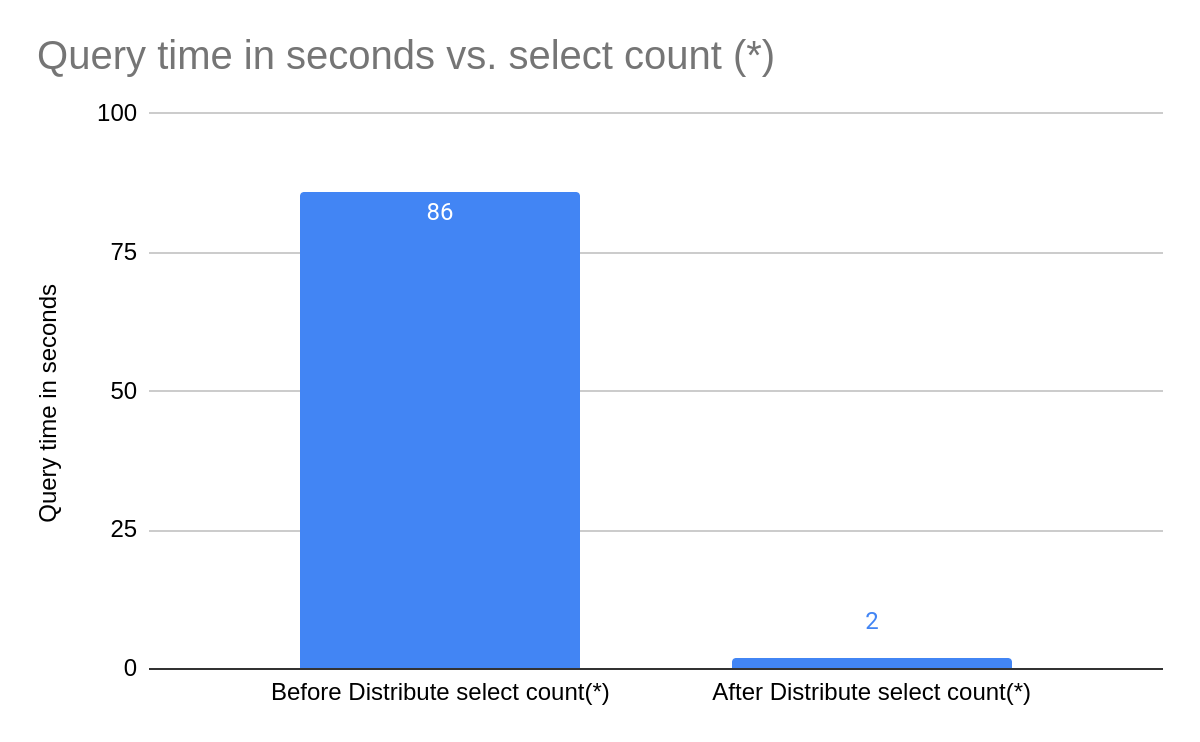
The advantage of this approach is that SELECT COUNT results can complete much faster by running in parallel across all the nodes in the cluster. By allowing the query to occur in parallel, we were able to get a SELECT COUNT (*) operation running against a 96 vCPU cluster that used to return results in 86 seconds down to only 2 seconds response time.
The corresponding disadvantage is that it will impact all the vCPUs in the cluster at once, so we suggest being judicious in running such expensive queries.
Once this feature is available in an upcoming release for ScyllaDB Enterprise and ScyllaDB Cloud, it would be natural to combine its use with Workload Prioritization to put some limits upon how intensive its impact will be to your production clusters.
Rate Limit Per Partition
Speaking of managing performance impacts, we’re also allowing you to put per-partition rate limits for reads or writes per second. Consider the following CQL example:
CREATE TABLE tab ( ... )
WITH PER PARTITION RATE LIMIT = {
'max_writes_per_second': 150,
'max_reads_per_second': 400
};You can set different rates for writes and reads per partition. Queries exceeding these limits will be rejected. This helps the database avoid hot partition problems or mitigate issues external to the database, such as spam bots. This feature pairs well with ScyllaDB’s shard-aware drivers because rejected requests will have the least cost. You can read more about this feature in the ScyllaDB documentation and in the feature design note on Github.
Load and Stream
Historically when restoring from backup, you needed to place the restored SSTables on the same number of nodes as the original cluster. But sometimes you may find the cluster topology has changed radically by adding or removing nodes from the topology used when the backup was made. If that’s the case, then the new token distribution will be mismatched to the SSTables. With ScyllaDB’s Load and Stream feature, you don’t need to worry about the details of what the cluster topology was when you made your backup. You can just place the SSTables on one of the nodes of the current cluster, run nodetool refresh, and the system will automatically determine how to reshard and rebalance the partitions across the cluster, streaming data to the new owning nodes.
Performance: Eliminate Exceptions from Read and Write Path
When a coordinator times out, it generates an exception which is then caught in a higher layer and converted to a protocol message. Since exceptions are slow, this can make a node that experiences timeouts become even slower. To prevent that, the coordinator write path and read path has been converted not to use exceptions for timeout cases, treating them as another kind of result value instead. Further work on the read path and on the replica reduces the cost of timeouts, so that goodput is preserved while a node is overloaded. This results in the following performance improvement:
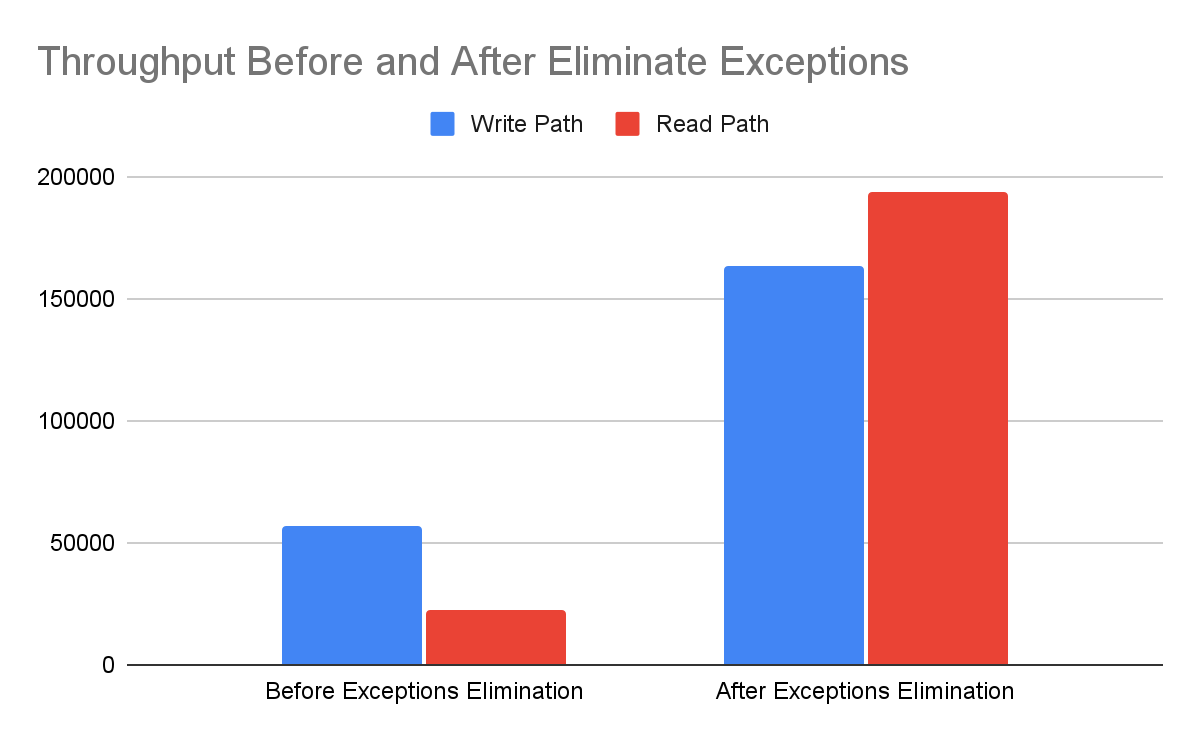
You can read more about the commands to generate this exception elimination in the release notes.
Raft Updates
While strongly consistent schema management remains experimental, the work on the Raft consensus algorithm continues toward more use cases, such as safe topology updates, improving traceability and stability. You can read the release notes to find out the latest Raft implementation updates in ScyllaDB Open Source 5.1.
Prune Materialized Views
Another new feature is a CQL extension, PRUNE MATERIALIZED VIEW. This statement can be used to remove inconsistent rows, known as “ghost rows,” from materialized views.
ScyllaDB’s materialized views have been production-ready since ScyllaDB 3.0, and we continuously strive to make them even more robust and problem-free. A ghost row is an inconsistency issue which manifests itself by having rows in a materialized view which does not correspond to any base table rows. Such inconsistencies should be prevented altogether and ScyllaDB strives to avoid them. Yet if they happen, this statement can be used to restore a materialized view to a fully consistent state without rebuilding it from scratch.
Example usages:
PRUNE MATERIALIZED VIEW my_view;
PRUNE MATERIALIZED VIEW my_view WHERE v = 19;
PRUNE MATERIALIZED VIEW my_view WHERE token(v) > 7 AND token(v) < 1535250;Materialized Views Synchronous Mode
There is now a synchronous mode for materialized views. In ordinary, asynchronous mode materialized views operations return before the view is updated. In synchronous mode materialized views operations do not return until the view is updated. This enhances consistency but reduces availability as in some situations all nodes might be required to be functional.
For example:
CREATE MATERIALIZED VIEW main.mv
AS SELECT * FROM main.t
WHERE v IS NOT NULL
PRIMARY KEY (v, id)
WITH synchronous_updates = true;<
ALTER MATERIALIZED VIEW main.mv WITH synchronous_updates = true;Learn more in our documentation.
Alternator TTL (Experimental)
This release supports Time-to-Live (TTL) expirations of data in our DynamoDB-compatible API, known as “Alternator.” While ScyllaDB already supported TTL on its CQL interface, its implementation differs from how DynamoDB handles expirations. For example, in CQL the expiration can be set at both the table level and at the individual column level. In DynamoDB, TTLs are set based on specific attribute names. Also, in DynamoDB, the TTL has a deletion delay of up to 48 hours.
With ScyllaDB’s Alternator, you can set a custom deletion delay (by default set to 24 hours). Also, Alternator will BYPASS CACHE for scans employed in TTL expiration, reducing the impact on user workloads. We’ve also implemented new metrics to observe TTL expirations.
While the implementation in this release is considered fully-featured, it has not been extensively tested or optimized; thus, we still consider it experimental. You can read more about enabling it in the documentation.
Web Assembly (WASM)-based UDA/UDF (Experimental)
We’ve been telling you about WebAssembly (Wasm) for some time, and it is now here in experimental form with ScyllaDB Open Source 5.1, providing the infrastructure for User Defined Aggregates (UDAs) and User Defined Functions (UDFs). The CQL syntax is compatible with Apache Cassandra. You can read more about how to enable and use them in the release notes.
Have Questions? Ask Them in Our Open Source Community!
If you have any comments, questions or feedback about our latest release, or about ScyllaDB, the fastest NoSQL Database, in general, feel free to add your voice to a thread on our new ScyllaDB community forum. Your questions there and any subsequent answers will be readily viewable (and searchable) to the Internet at large. But if you prefer the immediacy and interactiveness of chat, you can also bring your more real-time conversational issues to our thriving Slack community.