
We covered the basics of Elasticsearch and how ScyllaDB is a perfect complement for it in part one of this blog. Today we want to give you specific how-tos on connecting ScyllaDB and Elasticsearch, including use cases and sample code.
Use Case #1
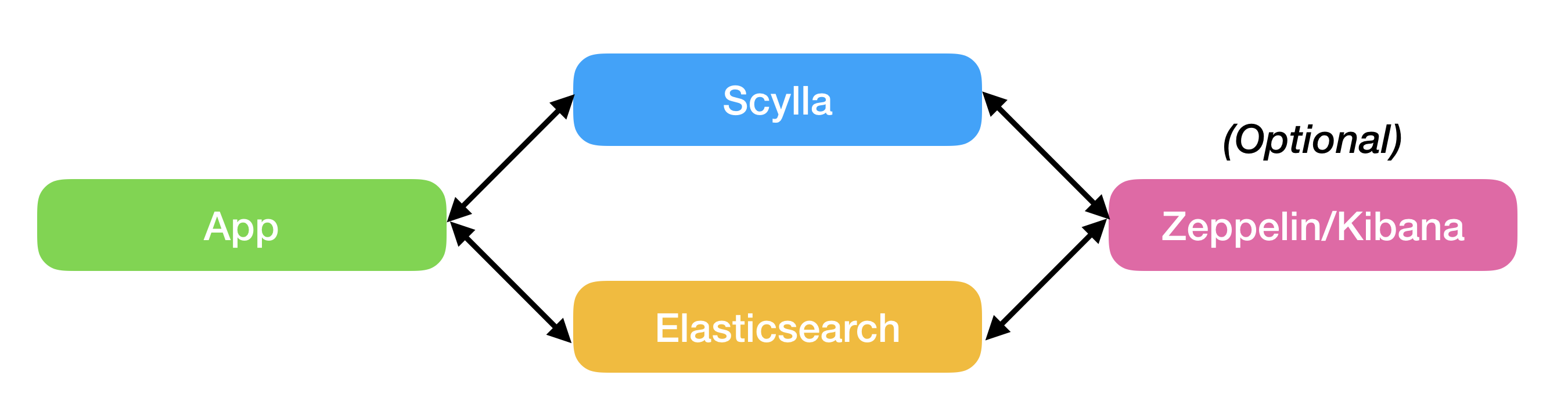
If combining a persistent, highly available datastore with full text search engine is a market requirement, then implementing a single, integrated solution is an ultimate goal that requires time and resources. To answer this challenge we describe below a way for users to use best-of-breed solutions that support full text search workloads. We chose Elasticsearch open source together with ScyllaDB open source NoSQL Database to showcase the solution.
In this use case we start with a fresh clean setup, meaning that you need to ingest your data into both ScyllaDB and Elasticsearch using dual writes and then perform the textual search.
The following example creates an apparel catalog consisting of 160 items, stored on ScyllaDB, and searchable using Elasticsearch (ES). The catalog.csv file comprised of 7 columns: Brand, Group, Sub_Group, Color, Size, Gender and SKU – Let’s describe them.
- Brand: companies who manufacture the clothing items (5 options)
- Group: clothing type (4 options)
- Sub_Group: an attribute that correlates to the clothing group type (9 options)
- Color: pretty much self explanatory (7 options) – very common query filter
- Size: ranging from Small to XLarge (4 options) – very common query filter
- Gender: People like to see the results for the relevant gender group (4 options) – very common query filter
- SKU: a unique product ID, usually made of the other product attributes initials
| Brand | Group | Sub_Group | Color | Size | Gender |
|---|---|---|---|---|---|
| North Face | Shirts | short sleeve | black | Small | men |
| Patagonia | Pants | long sleeve | red | Medium | women |
| Mammut | Shoes | gore-tex | grey | Large | boys |
| Garmont | Jackets | leather | green | XLarge | girls |
| Columbia | softshell | yellow | |||
| hiking | blue | ||||
| jeans | white | ||||
| bermuda | |||||
| UV_protection |
- Dual writes using the
insert_datascript for data ingestion, in our case an apparel catalog csv file. - Textual search using the
query_datascript, which is basically a 2-hop query that will retrieve the uniqueproduct_id (SKU)from Elasticsearch and then use the retrieved SKU to query other product attributes from ScyllaDB.
Prerequisites
- python installed
- pip installed
- Java 8 installed
- ScyllaDB cluster installed (see here)
- Node for Elasticsearch and python scripts (can be separate nodes)
Procedure
- Install the python drivers on the node to be used for the scripts
$ sudo pip install cassandra-driver
$ sudo pip install elasticsearch
- Install Elasticsearch (see here)
$ sudo apt-get update
$ curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.3.deb
$ sudo dpkg -i elasticsearch-6.2.3.deb
- Start Elasticsearch, verify status and health state
$ sudo /etc/init.d/elasticsearch start
[ ok ] Starting elasticsearch (via systemctl): elasticsearch.service.
curl http://127.0.0.1:9200/_cluster/health?pretty
{
“cluster_name” : “elasticsearch”,
“status” : “green“,
“timed_out” : false,
“number_of_nodes” : 1,
“number_of_data_nodes” : 1,
“active_primary_shards” : 0,
“active_shards” : 0,
“relocating_shards” : 0,
“initializing_shards” : 0,
“unassigned_shards” : 0,
“delayed_unassigned_shards” : 0,
“number_of_pending_tasks” : 0,
“number_of_in_flight_fetch” : 0,
“task_max_waiting_in_queue_millis” : 0,
“active_shards_percent_as_number” : 100.0
}
- Copy the following files to the location from which you will run them, and make them executable
- catalog.csv (the SKU is the unique product_id, made of other product attributes initials)
- insert_data_into_scylla+elastic.py
- query_data_from_scylla+elastic.py
- Run the insert_data script. The script will perform the following:
- Create the Schema on ScyllaDB (see Appendix-A)
- Create the Elasticsearch index (see Appendix-A)
- Dual write: insert the catalog items (csv file) to both DBs (using prepared statement for ScyllaDB)
-s/-eflags to insert a comma-separated list of IPs for the ScyllaDB and /or Elasticsearch (ES) nodes. If you are running Elasticsearch (ES) on the same node as the python scripts, no need to enter IP, 127.0.0.1 will be used as the default.$ python insert_data_into_scylla+elastic.py -husage: insert_data_into_scylla+elastic.py [-h] [-s SCYLLA_IP] [-e ES_IP]optional arguments: -h, --help show this help message and exit -s SCYLLA_IP -e ES_IP
- Once the “insert_data” script completes, you will find 160 entries in both ScyllaDB and Elasticsearch
| Elasticsearch | ScyllaDB |
$ curl http://127.0.0.1:9200/catalog/_count/?pretty |
cqlsh> SELECT COUNT (*) FROM catalog.apparel ; |
-
- Run the
query_datascript. The script will perform the following:- It will execute a textual search in Elasticsearch per the flag you provide, either searching for a single word (single filter) OR searching for multiple words (multiple filters), OR without any filter, which is basically a “match_all” query.
- It will then use the SKU value retrieved from the textual search to query ScyllaDB, while using prepared statements.As mentioned, there are 3 query types, use the
-nflag to select the query type. Optional values are:
- “single”: using a single filter (by group) to query for “pants”
- “multiple” (default): using multiple filters (by
colorANDsub_group) to query for “white softshell” - “none”: query without any filter = “match_all”
-s/-eflags to insert a comma-separated list of IPs for the ScyllaDB and /or Elasticsearch (ES) nodes. If you are running Elasticsearch (ES) on the same node as the python scripts, no need to enter IP, 127.0.0.1 will be used as the default. Note: Elasticsearch returns only the 1st 10 results by default. To overcome this we set the size limit to 1000 results. When retrieving a large set of results, we recommend using pagination (read more here: elasticsearch-py helpers).
$ python query_data_from_scylla+elastic.py -h
usage: query_data_from_scylla+elastic.py [-h] [-s SCYLLA_IP] [-e ES_IP] [-n NUM_FILTERS]
optional arguments:
-h, –help show this help message and exit
-s SCYLLA_IP
-e ES_IP
-n NUM_FILTERS
- It will execute a textual search in Elasticsearch per the flag you provide, either searching for a single word (single filter) OR searching for multiple words (multiple filters), OR without any filter, which is basically a “match_all” query.
- To delete Elasticsearch index and the keyspace in ScyllaDB run the following commands
- Elasticsearch:
$ curl -X DELETE "127.0.0.1:9200/catalog" - ScyllaDB:
cqlsh> DROP KEYSPACE catalog ;
- Elasticsearch:
- Run the
Use Case #2
In this use case we assume you already have your data in ScyllaDB and want to import it into Elasticsearch, to be indexed for textual search purposes. To accomplish this ,the first thing you will need to do is export the relevant table and its content from ScyllaDB into a .csv data file, this can be accomplished by using the cqlsh COPY TO command.
The second thing to do is export the table schema into a .cql schema file, a file for each table separately. This can be accomplished by running the following command cqlsh [IP] "-e DESCRIBE TABLE [table name] > [name].cql
Once you have your .csv and .cql files ready, you just need to have an Elasticsearch node installed and you’re good to go.
The following script (see Appendix-C) will use the.cql schema file and .csv data file as inputs to create an index in Elasticsearch (ES) and insert the data.
The ES index name will be created based on the .csv file name
The index _id field (index partition key) is based on the PRIMARY KEY taken from the .cql schema (simple/composite/compound).
The index _type field will represent the partition key (PK), in case of a compound key it will use `-` to concatenate the column names.
The script will print progress for every 1000 rows processed and total rows processed in its output.
Prerequisites
- python installed
- pip installed
- Java 8 installed
- ScyllaDB cluster installed (see here)
- Node for Elasticsearch and python scripts (can be separate nodes)
Procedure
- Install the python drivers on the node to be used for the scripts
$ sudo pip install cassandra-driver$ sudo pip install elasticsearch - Install Elasticsearch (see here)
$ sudo apt-get update$ curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.3.deb$ sudo dpkg -i elasticsearch-6.2.3.deb - Start Elasticsearch, verify status and health state
$ sudo /etc/init.d/elasticsearch start
[ ok ] Starting elasticsearch (via systemctl): elasticsearch.service.curl http://127.0.0.1:9200/_cluster/health?pretty
{"cluster_name" : "elasticsearch","status" : "green","timed_out" : false,"number_of_nodes" : 1,"number_of_data_nodes" : 1,"active_primary_shards" : 0,"active_shards" : 0,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0} - Copy the python file to the location from which you will run it, and make it executable. Place your
.csvand.cqlfiles in an accessible location (can be same dir as the python script) - Run the script (see below usage, important details and examples)
- Usage
$ python ES_insert_data_per_schema.py -husage: ES_insert_data_per_schema.py [-h] [-e ES_IP] [-c CSV_FILE_NAME][-s CQL_SCHEMA_FILE_NAME][-i IGNORE_CQL_SCHEMA]optional arguments:-h, --help show this help message and exit-e ES_IP-c CSV_FILE_NAME-s CQL_SCHEMA_FILE_NAME-i IGNORE_CQL_SCHEMA - Important Details
- Use
-eflag to insert a comma-separated list of IPs for Elasticsearch (ES) nodes. If ES is running locally, no need for this flag, default127.0.0.1will be used -iignore_cql_schema -> default:True. Meaning it will use the 1st column from the.csvfile for ES index_idfield. If you have a compound PK use-ino so not to ignore the.cqlschema-ccsv_file_name -> requires full path to file. Needs to be in the format as described in the prerequisites-scql_schema_file name -> requires full path to file. Checking schema for compound PK, if did not find it checking for simple PK- If
.cqlfile is not provided (but.csvfile was provided), script will fall back to ignoring.cqlschema and use the 1st column from the.csvfile for ES index_idfield - If both
.cql+.csvfiles are not provided, error is printed and script exists.
- Use
- Output Example Using Compound PK
ubuntu@ip-172-16-0-124:~/scylla_elastic$ python ES_insert_data_per_schema.py -c./cp_prod.product_all.csv -s./cp_prod_product_all.cql -i no## Check schema (./cp_prod_product_all.cql) for compound primary key to be used as index id## Did not find a compound primary key, checking for regular primary key to be used as index id## Connecting to ES -> Creating 'cp_prod.product_all' index, if not exist## Write csv file (./cp_prod.product_all.csv) content into Elasticsearch## Update every 1000 rows processed ##Rows processed: 1000Rows processed: 2000Rows processed: 3000Rows processed: 4000Rows processed: 5000Rows processed: 6000Rows processed: 7000Rows processed: 8000Rows processed: 9000## After all inserts, refresh index (just in case)### Total Rows Processed: 9715 ###
- Usage
Next Steps
We’ve given the case for using ScyllaDB and Elasticsearch together. And above we’ve shown you step-by-step model for how to implement it. The next step is up to you! Download ScyllaDB and Elasticsearch and try it out yourself.
If you do, we’d love to hear your feedback and experience. Either by joining our Slack channel, or dropping us a line.
Appendix A (Schema and Index for Use Case #1)
ScyllaDB schema Elasticsearch IndexAppendix B (Python Code for Use Case #1)
Insert_Data Query_DataAppendix C (Python Code for Use Case #2)



