




This is a guest blog post by Soumya Simanta, an architect at Ola Cabs, the leading ride-hailing service in India.
On-demand ride-hailing is a real-time business where responding to quick spikes in demand patterns is a critical need. These spikes are more profound during unusual circumstances such as bad weather conditions, special events, holidays, etc. It is critical that our software systems are architected to support this real-time nature of our business. However, creating a distributed software system that can satisfy this requirement is a challenge. An important component of any web-scale system is the database. Given the rapid growth of our organization, we wanted our choice of database to support some critical quality attributes. Our primary concerns were support for high throughput, low latency, and high availability (multi-zone and multi-datacenter support). Other key requirements were that the product is open source, required minimal maintenance and administration, had a rich ecosystem of tools and, finally, a database that is battle-tested in production.
Like many web-scale companies, we quickly realized that we do not need an ACID-compliant database for all our use cases. With proper design, we could model many of our systems around “eventually consistency,” thereby trading-off consistency while gaining all the other goodness that comes with an AP-compliant database such as Cassandra. Although we were already using Cassandra for some use cases, we were not sure if it was the best long-term fit for us. Primarily because it leverages the JVM runtime and therefore has the well-known latency issues and tuning overhead that comes with the JVM’s garbage collector.
Around early 2016 a new database, ScyllaDB, caught our attention. The primary reason for our interest was that ScyllaDB was advertised as a drop-in replacement for Cassandra, was written in native language (C++) and was developed by the creators of battle-tested software products such as the KVM hypervisor, OSv, and Seastar. While we recognized that ScyllaDB did not yet support all the features of Cassandra and that it was not yet battle-tested in production, we were intrigued by the close-to-the-hardware approach they had taken in building their database. Very early on, we had discussions with ScyllaDB’s core team and they assured us that they would soon add many important features. With this assurance, we were confident that a long-term bet on ScyllaDB would yield a positive outcome for us. We created a roadmap where we would gradually adopt ScyllaDB into our software ecosystem based on application criticality.
For our first use case in March of 2016, we deployed ScyllaDB 1.0 in passive mode along with another database as our primary datastore. Only writes were performed to ScyllaDB. As expected, ScyllaDB being write-optimized by design performed reasonably well in terms of latency and throughput. However, what was surprising for us was the stability of the database. There were no errors or crashes and it ran without any maintenance for more than 3 months. This was very promising for us. Next, we started using ScyllaDB 1.4 for both reads and writes. We had to modify our data model, which is a limitation of the Cassandra architecture itself and not specific to ScyllaDB. For the initial few cases, we performed our installation of ScyllaDB from scratch. However, we quickly realized that we were not getting the performance that was advertised. So we moved to an official AMI image that has tuned OS and database configurations provided by the ScyllaDB folks.
Our initial configurations were based on using EBS volumes. The advantage of using EBS was the protection against data loss in case of node failures. However, for certain use cases, we decided to move to ephemeral (NVMe) disks. In another system, we used ScyllaDB as a persistent cache where we could tolerate the risk of data loss due to ephemeral node failures. We mitigated the risk of disk failures by setting the correct replication factor, storing data across multiple Availability Zones (AZs) and ensuring that we could regenerate data quickly. This gave us a significant performance boost in terms of latencies because ScyllaDB is optimized for NVMe and an extra network hop is avoided as compared to using EBS.
We have deployed ScyllaDB across multiple microservices and platforms in our organization. We currently run two types of workloads. First are real-time reads at high throughput along with batch writes from our machine learning pipelines and Spark jobs at daily or hourly intervals. The second type of workload is cases with a uniform mix of reads and writes. We initially used the standard Cassandra driver from Java. For the last year, we have been using the Gocql connector for Golang for most of our new use cases. In our experience, our overall application latencies provided by the Go-based apps are better with less jitter and significantly less application memory footprint when compared with Java-based applications. In most cases, we are using ScyllaDB without a caching layer because by using the proper hardware for the server nodes we were able to get our target latency profiles (< 5ms 99-tile) with just ScyllaDB. This not only resulted in a simplified architecture but also helped us save on the hardware cost for the caching layer.
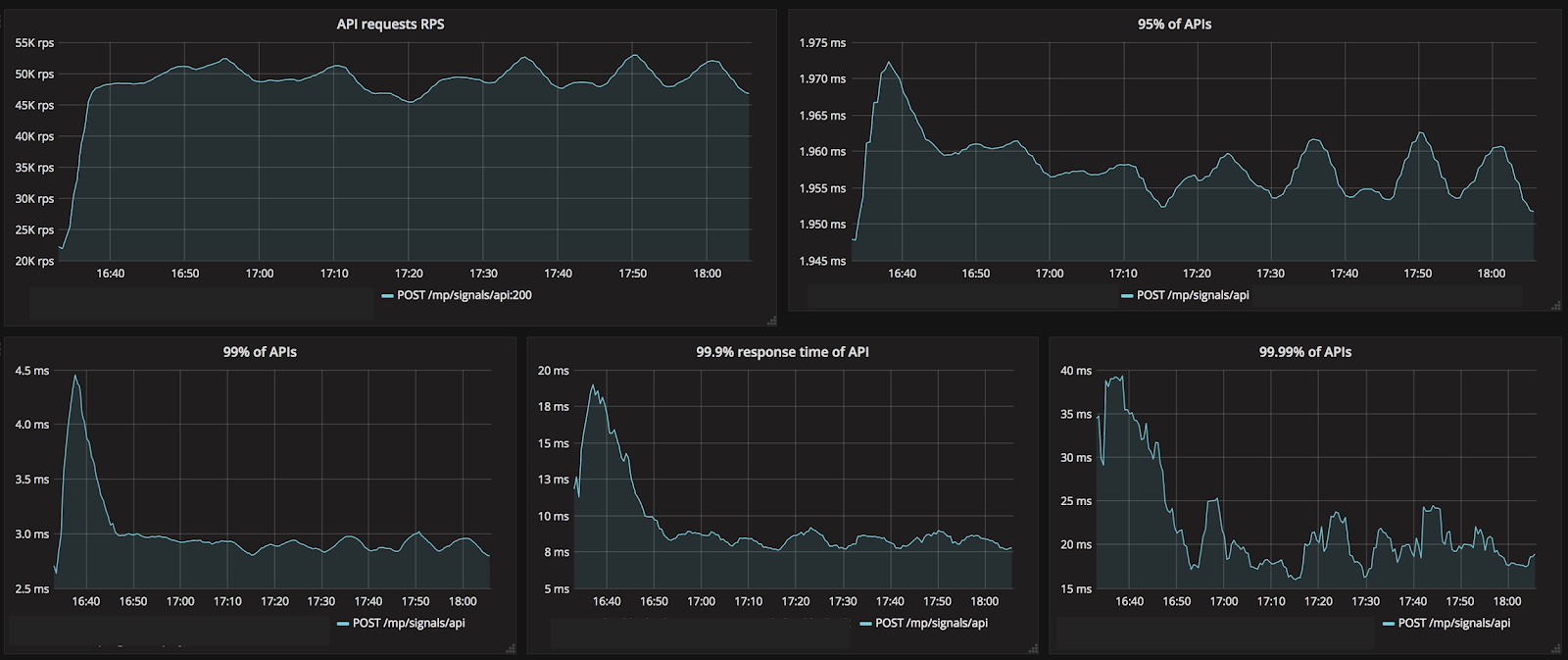
Figure 1. Application Latency Profile. Application Go code running on Docker using Gocql driver for ScyllaDB 2.1 on a 5 node i3.8xlarge cluster)
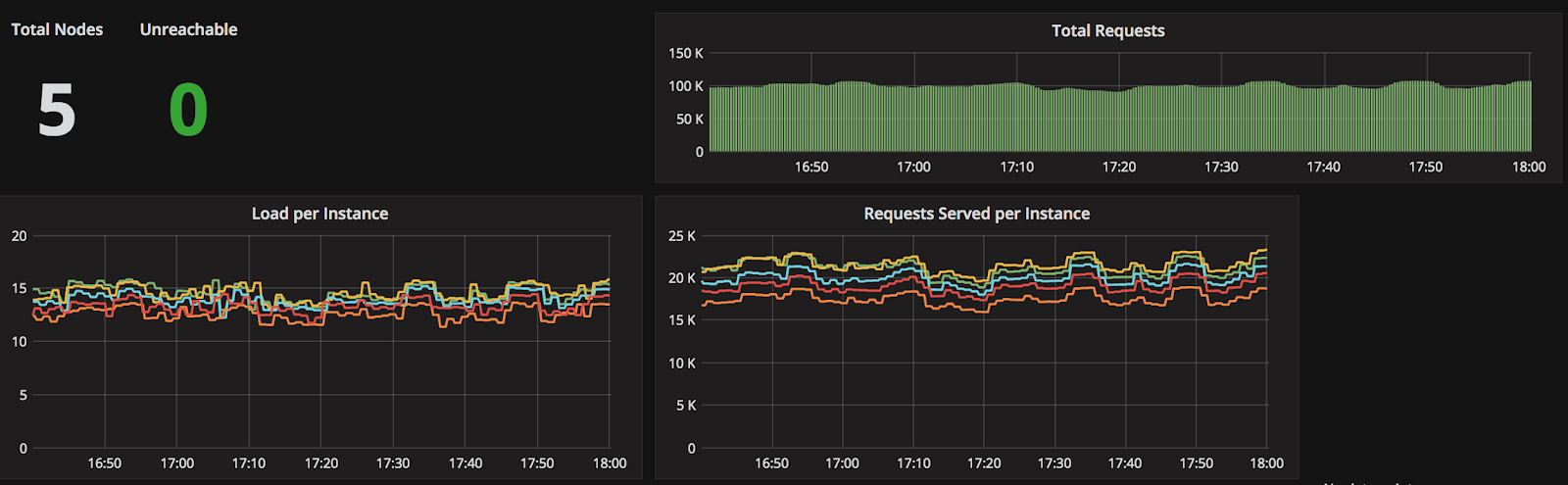
Figure 2. ScyllaDB Prometheus Dashboard (for the application shown in Figure 1)
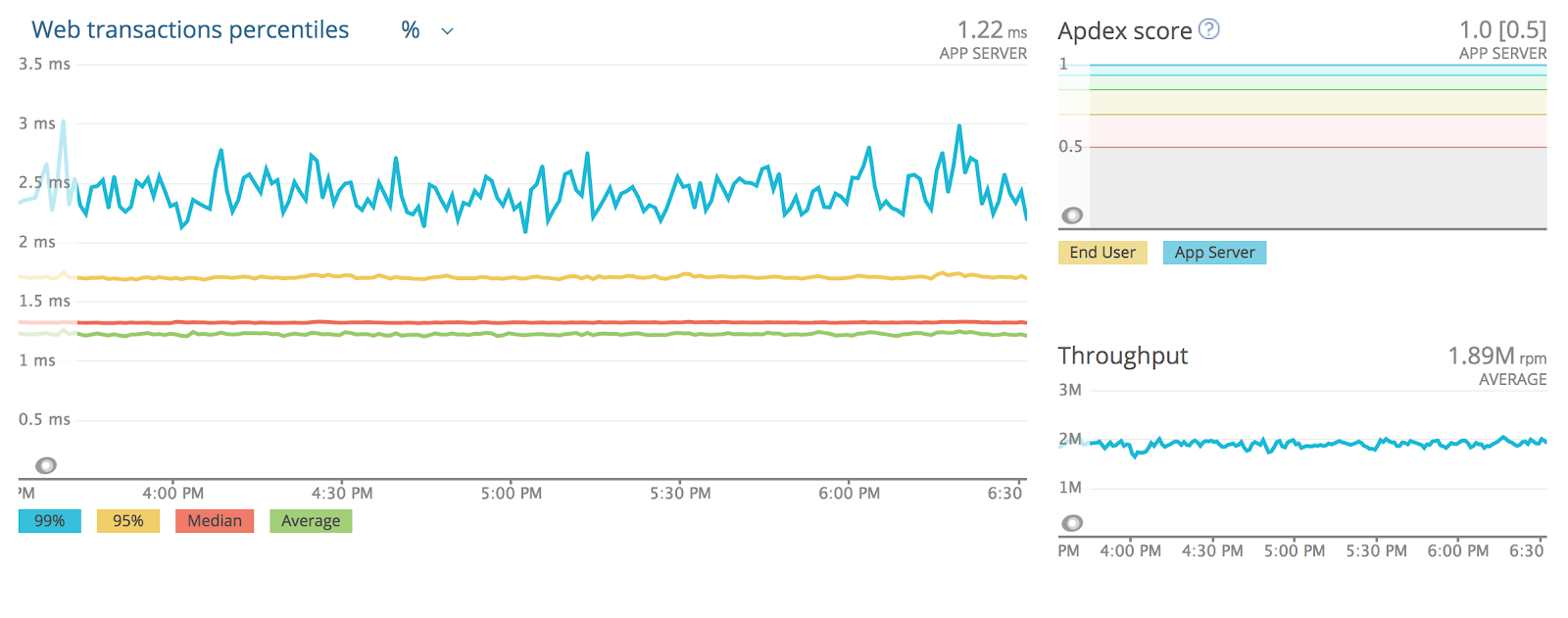
Figure 3: Application Latency Profile
Another valuable feature that was introduced in ScyllaDB was native metrics monitoring support for Prometheus. This was extremely helpful in debugging and identifying bottlenecks in our data model and sharing our results for debugging with the ScyllaDB community. Sharing all the metrics with the ScyllaDB community and core developers reduced the performance debugging cycle. Additionally, the metrics enabled us to make cost-performance tradeoffs by selecting the right hardware specs for our latency/throughput requirements. Another takeaway was that by tweaking the schema (e.g., reduction in partition sizes) we could get significant improvements in performance. We highly recommend that all ScyllaDB users configure the out-of-box monitoring provided by ScyllaDB from day one.
In our two-year journey of using it in production, ScyllaDB has lived up to our expectations. We have graduated from using ScyllaDB for very simple and non-critical use cases to deploying it for some of our mission-critical flows. ScyllaDB’s development team has delivered on their core promise of doing continuous releases to push out new features but has never compromised on the quality or performance of their product. The team is also very receptive to its community’s needs and is always ready to help on ScyllaDB’s Slack channel and mailing lists. Some features we are looking forward to are the secondary indexes (currently in experimental mode), incremental repair, support for Apache Cassandra 3.x storage (finally patches arrived in the dev mailing list) and user-defined types (UDTs).

