




Let’s talk about a financial use case where streaming and near-real-time messaging is used through Kafka and ScyllaDB. We will model a system that allows subscribers to follow stock prices for companies of their interest, similar to a simplified use of a trading terminal.
Our system follows an architectural pattern in which updates of stock prices are pushed to a Kafka queue, and subscribers consume messages that contain company stock information. These consumed messages are then stored in ScyllaDB instances, where they can be used later for more sophisticated analysis (for example, using an engine like Spark).
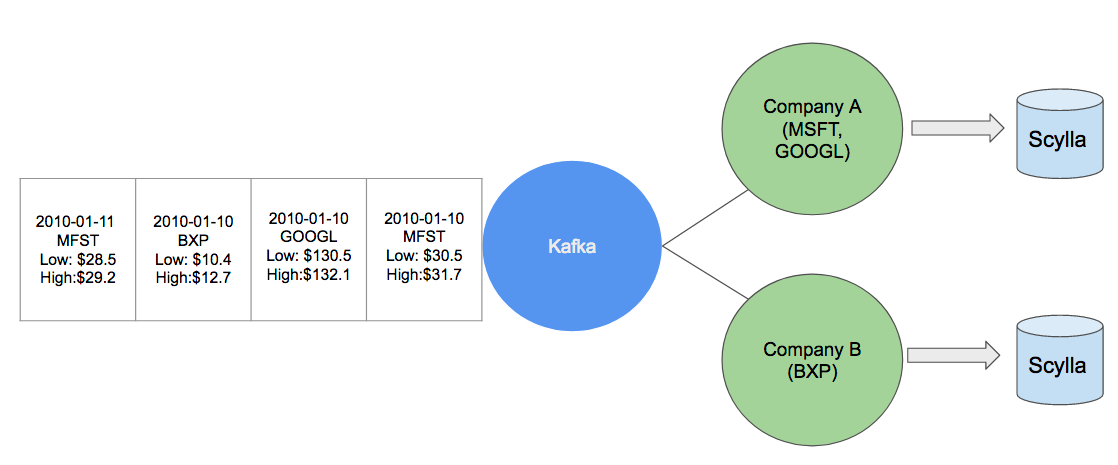
Let’s say Company A is interested in capturing stock prices for Microsoft and Google. At the end of each day, Company A captures the messages that arrive in the Kafka queue with information about MSFT and GOOGL, and stores them in a ScyllaDB cluster for later use.
Data Modeling
Our use case uses Kaggle’s New York Stock Exchange dataset, a public dataset that contains information about S&P 500 company prices from 2010 to 2016 (price.csv). This time-series data allows us to simulate real-time messaging as exchanges close at the end of the day and capture summary information about the stock trades that were made that day. The structure of the data is as follows:
- date: date of the summary information (day of trades)
- symbol: company symbol (code) as it is known in the exchange
- open: opening price of the stock
- close: closing price of the stock
- low: lowest price of the stock during the day
- high: highest price of the stock during the day
- volume: total amount of money traded
We are going to use the structure of this data as we model our system. The company symbol will define our Kafka topics (such that consumers subscribe only to stocks of their interest) and date + symbol will define our keys in ScyllaDB (such that we can efficiently do analysis by companies, periods, etc.)
Data Pipeline
We will write code for the following stages of our data pipeline. When all steps are completed, we will have a simple and scalable ecosystem for stock price generation and consumption:
- Parse data, defining topics and messages.
- Simulate stream of messages to the Kafka queue.
- Simulate consumption of messages by topic of interest (for example, companies followed).
- Use ScyllaDB as our data store: each consumer will store its companies of interest in ScyllaDB.
Software Setup
Prerequisites
For this entire tutorial, we assume that at least Java 1.7 and Maven 3.0.5 are installed throughout all machines in the cluster. We are writing all code in Java with Maven, but it is also necessary for Kafka, Zookeeper, and the Cassandra Java core driver. We also assume familiarity with Apache stack ecosystems.
ScyllaDB
Installing ScyllaDB is quite straightforward. Depending on the target setup, we can follow slightly different processes. Click here for access to the downloads and instructions.
Zookeeper
Running Zookeeper is a prerequisite for Kafka. Installation is also straightforward, and details can be found here.
Basically, we need to modify
conf/zoo.cfg
and then start Zookeeper with a provided script:
bin/zkServer.sh start
Kafka
The Kafka quickstart provides a wonderful guide to installing and running Kafka. You can find it here.
Note that we have to configure config/server.properties with all of our brokers IPs (if more than one). Please also notice that in the latest versions, topics don’t need to be defined manually: if we push a message with a non-existing topic, Kafka will create it automatically.
For the rest of this article, we assume that we are running at least one instance of each: ScyllaDB, Zookeeper, and Kafka.
Building Our Use Case
The complete code for the use case can be found here:
https://github.com/scylladb/scylla-code-samples/tree/master/kafka-scylladb
Java and Maven
We are going to use Maven as the building tool for the Java project. You can see the exact definition in the pom.xml in the project:
https://github.com/scylladb/scylla-code-samples/blob/master/kafka-scylladb/pom.xml
We will need the following dependencies:
org.apache.kafka, cassandra-driver-core, com.google.code.gson, net.sf.opencsv, apache commons-lang and the maven compiler plugin.
With this setup, we can generate an executable jar file containing all necessary parts of the pipeline.
mvn clean compile assembly:single
A helper script for this purpose can be found in:
https://github.com/scylladb/scylla-code-samples/blob/master/kafka-scylladb/scripts/buildJar.sh
Parsing Data, Defining Topics and Messages
Our goal is to take the dataset (prices.csv) and process one line at a time. Each line contains information about a company’s stock price on a given day, which is the information we wish to push to consumers of our system. Then we will build a message that will be submitted to the Kafka queue with a topic defined by the company code. The body of the message will be a JSON object describing said line of input.
For example, line:
2010-01-04,MSFT,30.620001,30.950001,30.59,31.1,38409100
will be translated into a Kafka message with topic MSFT and content:
{"open":"30.620001","symbol":"MSFT","volume":"38409100","high":"31.1","low":"30.59","date":"2010-01-04","close":"30.950001"}
Our csv data parser SP_DataParser is specified in:
Once SP_DataParser is initialized with the data file path, it will store the csv header and we then can convert any number of lines to a JSON message.
Using the above class, we can read all of our data and produce Kafka messages and topics. Our parser is used extensively when simulating the pushing of messages to the Kafka queue:
ArrayList linesJson;
while (!(linesJson = parser.read(30)).isEmpty()) {
ArrayList msgs = new ArrayList<>();
for (String s : linesJson) {
msgs.add(new Producer.KafkaMessage(parser.getKey(s, "symbol"), s));
}
kafkaProducer.send(msgs);
// Sleep two seconds to simulate time delays between incoming of real quotes.
Thread.sleep(2000);
}
Using our parser, we can instantiate the KafkaMessage class, which will contain a topic for the message and the JSON body we wish to transmit.
Simulate Stream of Messages to the Kafka Queue
Now that we have a way to parse and construct our messages, we need to be able to transmit them to a Kafka queue. For this, we need a Producer:
Having such a class, we can send messages to Kafka in a relatively simple way:
public void send(List msgs) {
for (KafkaMessage msg : msgs) {
System.out.println("Sending message to topic '" + msg.topic + "' at " + new Date());
ProducerRecord<String, String> rec = new ProducerRecord<String, String>(msg.topic, msg.message);
producer.send(rec);
}
producer.flush();
}
Now, we have everything we need to completely run the producer side of our data pipeline, which includes reading the data, constructing the messages, and pushing them to Kafka. Our entry point to run the production is the ProductionSimulator:
In addition to the above, we need to provide our simulator with the data file path and several Kafka configuration parameters. To simplify deployment, Kafka parameters are passed in a configuration file that looks like this:
key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer key.deserializer=org.apache.kafka.common.serialization.StringDeserializer bootstrap.servers=localhost:9092 value.serializer=org.apache.kafka.common.serialization.StringSerializer value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
An example of Kafka configuration file can be found here:
https://github.com/scylladb/scylla-code-samples/blob/master/kafka-scylladb/config/kafka.config
After building the jar, we can run ProductionSimulator as follows:
java -cp com.scylladb.sim.ProductionSimulator
A helper script for this task can be found in:
Running the script will start pushing our data file contents to the running Kafka broker specified in the configuration:
./runProductionSimulation.sh -c config/kafka.config -d data/prices.csv log4j:WARN No appenders could be found for logger (org.apache.kafka.clients.producer.ProducerConfig). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. Sending message to topic 'A' at Fri Mar 31 00:55:05 EDT 2017 Sending message to topic 'AAL' at Fri Mar 31 00:55:06 EDT 2017 Sending message to topic 'AAPL' at Fri Mar 31 00:55:07 EDT 2017 Sending message to topic 'AAPL' at Fri Mar 31 00:55:07 EDT 2017 Sending message to topic 'MSFT' at Fri Mar 31 00:55:07 EDT 2017
We can verify everything is working properly so far with Kafka’s out-of-the-box consumer, subscribing to any topic (company symbol). In this case, let’s subscribe to MSFT:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic MSFT
{"open":"30.620001","symbol":"MSFT","volume":"38409100","high":"31.1","low":"30.59","date":"2010-01-04","close":"30.950001"}
Processed a total of 1 messages
Simulate Consumption of Messages by Topic of Interest (or Following Companies)
For example, a company wishes to follow how Google (GOOGL) stock is doing and run some after-the-fact analysis on the stock prices data.
In order to extract company information from the Kafka queue, we need a consumer:
Each consumer will continuously run in its own thread, polling the queue for new messages that arrive with the subscribed topic. As messages arrive, the consumer will also be responsible for persisting the messages to our ScyllaDB datastore.
public void run() {
consumer.subscribe(Arrays.asList(topic));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
// Write to ScyllaDB what we consumed.
…..
}
}
} catch (Exception ex) {
System.out.println("Exception caught " + ex.getMessage());
} finally {
consumer.close();
System.out.println("After closing KafkaConsumer");
}
}
Use ScyllaDB as Our Data Store
Having a consumer in place allows us to move on to the persistence layer. As consumers receive messages, they write transactions to ScyllaDB.
Let’s go ahead and create a simple Column Family to hold our data in the ScyllaDB clusters:
create table keyspace1.s_p_prices (
date timestamp,
symbol varchar,
open varchar,
close varchar,
low varchar,
high varchar,
volume varchar,
PRIMARY KEY (date, symbol)
);
A helper script to create the Column Family in the ScyllaDB cluster can be found here:
https://github.com/scylladb/scylla-code-samples/blob/master/kafka-scylladb/scripts/scylla_run_cql.sh
Once our table is created, all we need to do to write to the cluster is indicate consumers. The following class provides a simple manager for our ScyllaDB-related operations, including query building, insertion, and data retrieval. And, as we read messages in our consumers, we write them to ScyllaDB:
public void run() {
// subscribe to topic.
consumer.subscribe(Arrays.asList(topic));
// Write to ScyllaDB what we have consumed.
// ScyllaDBManager is singleton for every consumer thread.
ScyllaDBManager manager = ScyllaDBManager.getInstance(scyllaConfigProperties);
try {
while (true) {
// poll Kafka queue every 100 millis.
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
manager.insert(SP_DataParser.decode(record.value()));
System.out.println("Inserting message from topic "
+ this.topic
+ " in "
+ scyllaConfigProperties.getProperty("scylla.keyspace")
+ "." + scyllaConfigProperties.getProperty("scylla.table"));
}
}
} catch (Exception ex) {
System.out.println("Exception caught " + ex.getMessage());
} finally {
consumer.close();
System.out.println("After closing KafkaConsumer");
}
}
Now, we have everything we need to completely run the consumer side of our data pipeline, which includes retrieving the relevant messages and writing them to ScyllaDB. Our entry point to run the consumption is the ConsumptionSimulator:
We need to provide our simulator with several parameters.
- topic: topic to subscribe to
- Kafka config: Kafka configuration file
- group: Kafka group id for these consumers
- number of consumers: number of consumer threads to start
- ScyllaDB config: ScyllaDB config file
The ScyllaDB configuration file will look like this:
scylla.host=ec2-54-172-175-128.compute-1.amazonaws.com scylla.keyspace=keyspace1 scylla.table=s_p_prices
An example of a ScyllaDB configuration file can be found here:
https://github.com/scylladb/scylla-code-samples/blob/master/kafka-scylladb/config/scylla.config
After building the jar, we can run ConsumptionSimulator as follows:
java -cp <jar file> com.scylladb.sim.ConsumptionSimulator <topic> <kafka config file> <groupid> <nconsumers> <ScyllaDB config file>
A helper script for this task can be found in:
Running the script would start pulling relevant messages and writing to our ScyllaDB instance:
./scripts/runConsumptionSimulation.sh -t MSFT -kc config/kafka.config -g group1 -n 1 -sc config/scylla.config
0
log4j:WARN No appenders could be found for logger (org.apache.kafka.clients.consumer.ConsumerConfig).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Connecting to ScyllaDB Cluster ec2-54-172-175-128.compute-1.amazonaws.com at keyspace: keyspace1
INSERT INTO keyspace1.s_p_prices (open,symbol,volume,high,low,date,close) VALUES ('30.620001','MSFT','38409100','31.1','30.59','2010-01-04','30.950001')
Inserting message from topic MSFT in keyspace1.s_p_prices
We can verify that MSFT records were consumed and written to ScyllaDB.
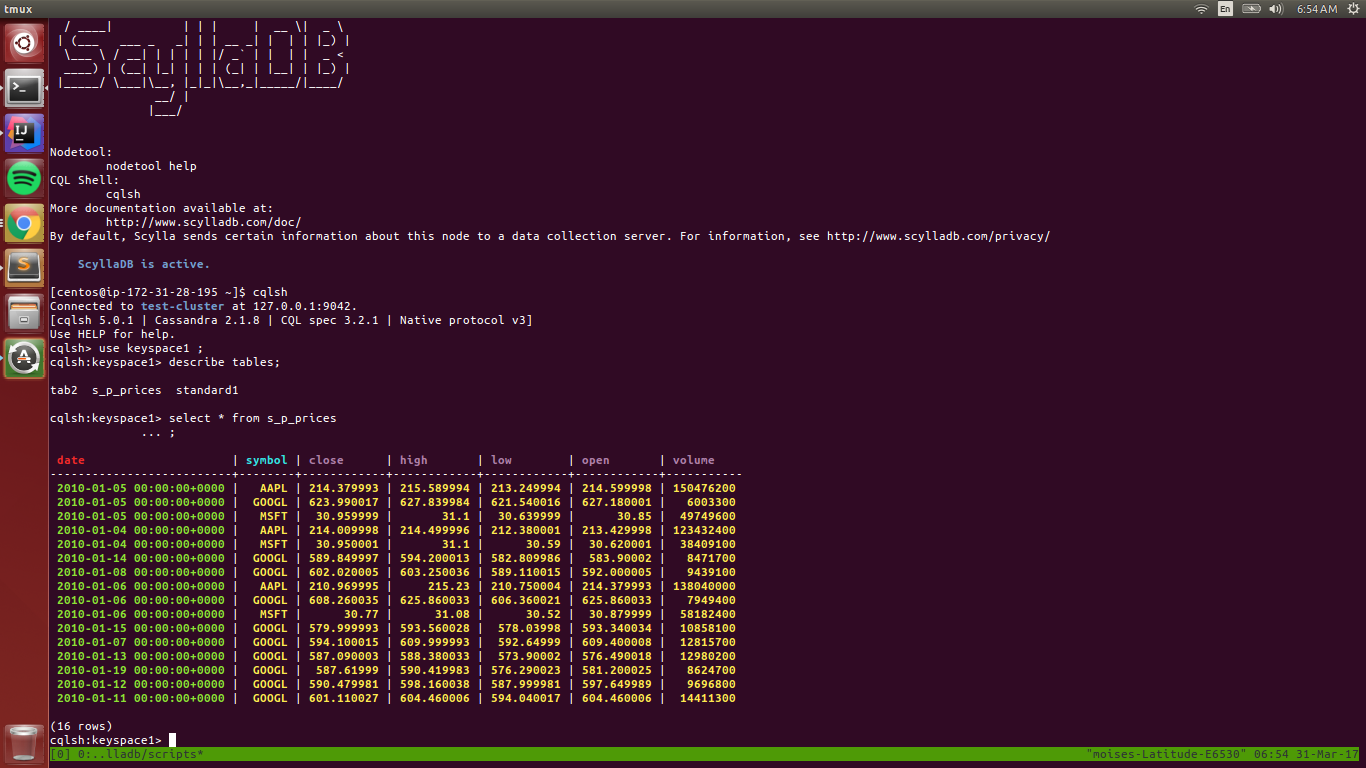
Final Notes
We have completed our data pipeline. Every consumer has now a ScyllaDB instance storing data of interest, which can later be pulled from the datastore and analyzed and integrated with other technologies such as Spark. Speed, reliability, and scalability are a must when working with financial data. The performance and scalability of both ScyllaDB and Kafka give every consumer (every topic follower) access to a powerful pipeline.



