The ScyllaDB team is pleased to announce the release of ScyllaDB Enterprise 2020.1.0, a production-ready ScyllaDB Enterprise major release. After 5,568 commits originating from five open source releases, we’re excited to now move forward with ScyllaDB Enterprise 2020. This release marks a significant departure for us, while we’ve said for years we are a drop-in replacement for Apache Cassandra we are now also a drop-in replacement for Amazon DynamoDB.
The ScyllaDB Enterprise 2020.1 release is based on ScyllaDB Open Source 4.0, promoting open source features to Enterprise level support, including DynamoDB-compatible API (Alternator) and Lightweight Transactions (LWT).
Alternator, Our DynamoDB-Compatible API
DynamoDB users can now switch to ScyllaDB without changing a single line of application code. ScyllaDB significantly reduces the total cost of ownership, delivers lower and more consistent latencies and expands the limitations DynamoDB places on object size, partition size, etc. Developers don’t want to be locked into a single platform, especially one that’s so expensive.
ScyllaDB can also run as a complement to DynamoDB, extending an existing DynamoDB implementation to additional deployment options. You can run clusters on-premises, on your preferred cloud platforms or on ScyllaDB’s fully managed database as a service, ScyllaDB Cloud. You are free to access their data as you like, without pay-per-operation fees, and with more deployment options, including open source solutions like Docker and Kubernetes.
Improvements over Cassandra
Meanwhile we continue to extend our lead over Apache Cassandra and other Cassandra-compatible offerings. For example, ScyllaDB’s implementation of the Paxos consensus algorithm for Lightweight Transactions (LWT) is more efficient and consistent by default, allowing you better performance for compare-and-set conditional update operations.
We’ve also introduced unique enhancements for the Cassandra Query Language (CQL), to provide more granular and efficient results, from adding new clauses such as BYPASS CACHE, to enhancements in ALLOW FILTERING (such as multi-column and CONTAINS restrictions), to a LIKE operator to enable searching for patterns in user data.
Also in the ScyllaDB Enterprise 2020 release roadmap is Change Data Capture (CDC), a stream of database updates implemented as standard CQL tables. This means your change data will be distributed across your cluster normally, and you can use standard CQL queries to see changes, pre-images and post-images of affected records. You will not need specialized applications to deduplicate and consume updates.
Unique Capabilities
Since we made our last major release in May 2019 we introduced ScyllaDB-exclusive innovations, such as a new default compaction strategy Incremental Compaction Strategy (ICS), which can save users over a third of their total storage requirements, and Workload Prioritization, which enables balancing different classes of transactional or analytical processing on the same cluster.
These unique capabilities allow ScyllaDB Enterprise users to get far more efficient utility out of their existing infrastructure — advances no other NoSQL database vendor can match, and are even above and beyond our highly performant open source offering.
Staying at the Forefront
We’ve also seen many advances in cloud computing, such as the 60 terabyte-scale I3en series “meganodes” from AWS, which enable much higher storage-to-memory densities, and which ScyllaDB Enterprise 2020.1 now supports. ScyllaDB Enterprise also keeps us in unison with industry advances in Linux, supporting Red Hat Enterprise Linux 8, CentOS 8, and Debian 10. We’ve also put in a great deal of work to ensure our code is portable, including relocatable packages.
ScyllaDB Enterprise 2020.1 includes all of 2019.1.x bug fixes and features plus additional features and fixes brought in from ScyllaDB Open Source 4.x.
Additional functionality enhancements since 2019.1.0 includes:
- Local secondary indexes (next to our global indexes)
- IPv6 support
- Various query improvements including CQL per partition limit and GROUP BY
Security enhancements
- Encryption at Rest
Usability enhancements include:
- Large Cell / Collection Detector
- Nodetool TopPartitions
Performance enhancements include:
- MC SSTable format
- Row-level repair
- Improved CQL server admission control
Related Links
- Read more about ScyllaDB Enterprise here.
- Get ScyllaDB 2020.1 (customers only, or 30-day evaluation)
- Upgrade from 2019.1.x to 2020.1.y
- Upgrade from ScyllaDB Open Source 4.0 to ScyllaDB 2020.1
ScyllaDB Enterprise customers are encouraged to upgrade to ScyllaDB Enterprise 2020.1, and are welcome to contact our Support Team with questions.
Deployment
- ScyllaDB Enterprise packages are newly available for:
- Debian 10
- Red Hat Enterprise Linux 8
- CentOS 8
- ScyllaDB EC2 AMI user data format has changed. The new format is JSON based, and while it supports all the options it is not backward compatible.
- Completing the new AMI format, we are releasing a Cloud Formation template, for easy launch of a ScyllaDB cluster in one region.
- ScyllaDB Docker:
node_exporteris now part of the ScyllaDB Docker, making it easier to consume OS-level metrics when working with Docker and ScyllaDB Monitoring - ScyllaDB Enterprise 2020.1 is also optimized to work with the new AWS EC2 I3en server family.
- ScyllaDB Enterprise 2020.1 is *not* available on Ubuntu 14.04 or Debian 8. If you are using ScyllaDB with either of these OS/versions please upgrade to Ubuntu 16.04 or 18.04 or Debian 9 accordingly.
New Features in 2020.1
Lightweight Transactions (LWT)
Also known as Compare and Set (CAS), add support for conditional INSERT and UPDATE CQL commands. ScyllaDB supports both equality and non-equality conditions for lightweight transactions (i.e., you can use <, <=, >, >=, !=,= and IN operators in an IF clause).
You can learn more on LWT in ScyllaDB and LWT optimizations from the latest LWT Webinar (registration required) and LWT documentation.
ScyllaDB Alternator: The Open Source DynamoDB-compatible API
Project Alternator is an open-source implementation for an Amazon DynamoDB™-compatible API. The goal of this project is to deliver an open source alternative to Amazon’s DynamoDB that can be run anywhere, whether on-premises or on your own favorite cloud provider, or in ScyllaDB Cloud.
ScyllaDB Alternator was introduced as an experimental feature in ScyllaDB 3.2, and it is now, in ScyllaDB 2020.1.0, it is promoted to the Enterprise version.
Read more here: Open Source DynamoDB-compatible API Documentation.
- Support IPv6 for client-to-node and node-to-node communication #2027
ScyllaDB now supports IPv6 Global Scope Addresses for all IPs: seeds, listen_address, broadcast_address etc. Note that ScyllaDB Monitoring stack 3.0 and above supports IPv6 addresses as well, and IPv6 support for ScyllaDB Manager is coming soon (ScyllaDB Manager 2.0.1). Make sure to enableenable_ipv6_dns_lookupin scylla.yaml (see below)
Example from scylla.yaml
Enable_ipv6_dns_lookup: true
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "fcff:69:46::7b"
listen_address: fcff:69:46::7b
broadcast_rpc_address: fcff:69:46::7b
rpc_address: fcff:69:46::7b
…
Documentation for IPv6
CQL Enhancements
- CQL: support for GROUP BY to Select statement #2206
Example:
SELECT partitionKey, max(value) FROM myTable GROUP BY partitionKey;
SELECT partitionKey, clustering0, clustering1, max(value) FROM myTable GROUP BY partitionKey, clustering0, clustering1;
Documentation for GROUP BY
- CQL: LIKE Operation #4477
The new CQL LIKE keyword allows matching any column to a search pattern, using % as a wildcard. Note that LIKE only works with ALLOW FILTERING.
LIKE Syntax support:
'_' matches any single character
'%' matches any substring (including an empty string)
'\' escapes the next pattern character, so it matches verbatim
any other pattern character matches itself
an empty pattern matches empty text fields
For example:
> INSERT INTO t (id, name) VALUES (17, ‘Mircevski’)
> SELECT * FROM t where name LIKE 'Mirc%' allow filtering
Documentation for the new LIKE operator
- CQL: Support open range deletions in CQL #432
Allow range deletion based on the clustering key, similar to range query with SELECT
Example:
CREATE TABLE events ( id text, created_at date, content text, PRIMARY KEY (id, created_at) );
DELETE FROM events WHERE id='concert' AND created_at <= '2019-10-31';
Documentation for open range deletions
- CQL: Auto-expand replication_factor for NetworkTopologyStrategy #4210
Allowing users to set Replication Factor (RF) for all existing Data Centers (DCs).
Example:
CREATE KEYSPACE test WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor': 3}
Note than when adding new data centers, you need to set the RF again to include the added DCs. You can again use the auto-expansion option:
ALTER KEYSPACE test WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor': 3}
Or you can set RF for the new DC manually (if you want a different RF, for example), but remember to keep the old DCs’ replication factors:
ALTER KEYSPACE test WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor': 3, 'new-dc' : 5}
Documentation for the new Auto-expand replication_factor
- CQL: Support non-frozen UDTs #2201
Non-frozen User Defined Types (UDTs), similarly to non-frozen collections, allow updating single fields of a UDT value without knowing the entire value. For example:
CREATE TYPE ut (
a int,
b int
);
CREATE TABLE tbl (
pk int PRIMARY KEY,
val ut
);
INSERT INTO tbl (pk, val) VALUES (0, {a:0, b:0});
UPDATE tbl SET val.b = 1 WHERE pk = 0;
Documentation for the new non-frozen UDTs
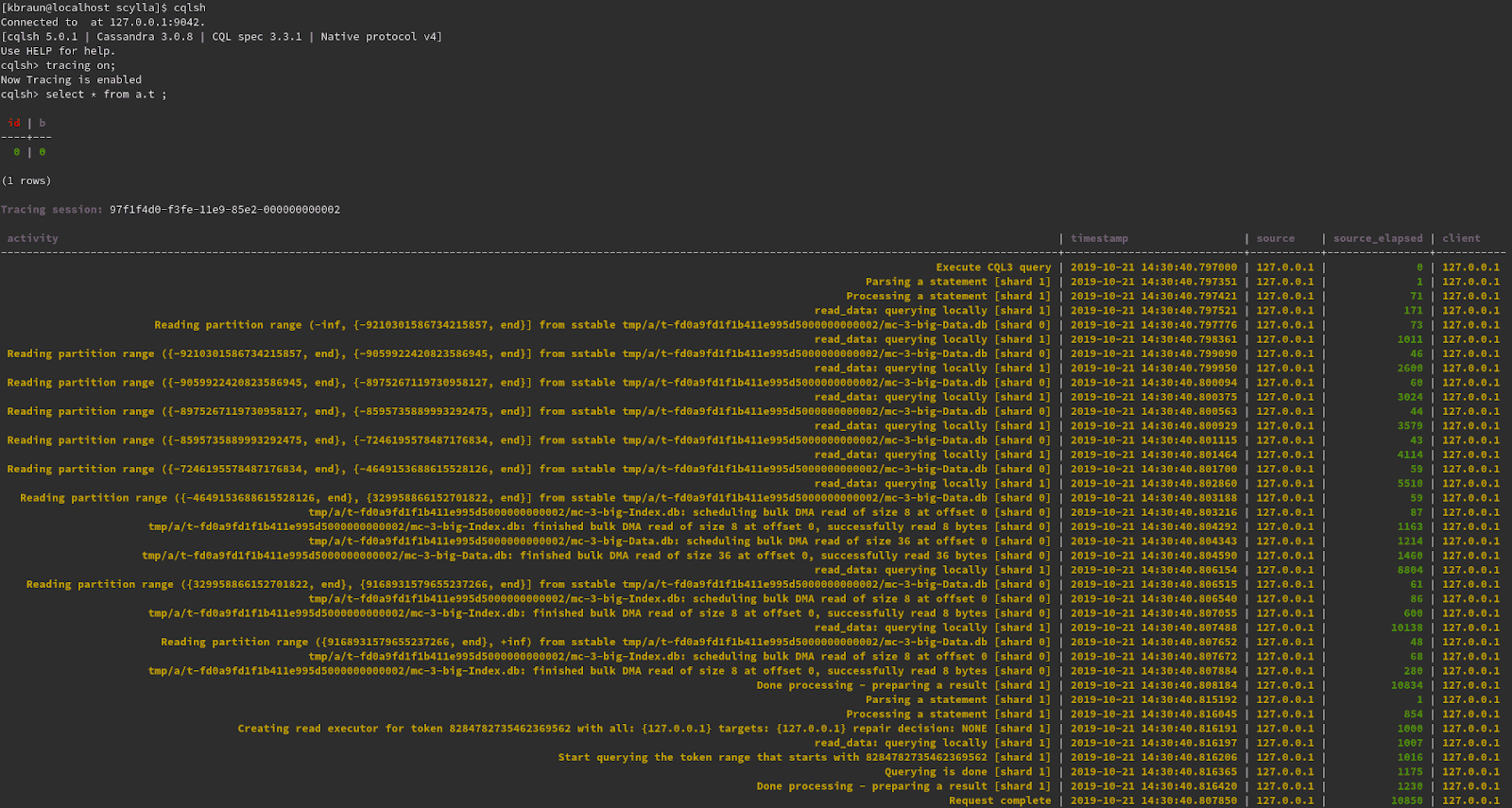
- CQL: CQL Tracing now include reports on SSTable access #4908
Disk I/O has a strong effect on query latency, but until now, it was not reported in CQL tracing.
This change introduces relevant entries to the CQL trace whenever SSTables are read from disk.
Example:
- Add CQL PER PARTITION LIMIT
For exampleSELECT * FROM users PARTITION LIMIT 2;See here for using LIMIT for SELECTs
- BYPASS CACHE clause #3770
The newBYPASS CACHEclause onSELECTstatements informs the database that the data being read is unlikely to be read again in the near future, and also was unlikely to have been read in the near past; therefore no attempt should be made to read it from the cache or to populate the cache with the data. This is mostly useful for range scans which typically process large amounts of data with no temporal locality and do not benefit from the cache.
For example:
SELECT * from heartrate BYPASS CACHE;
If you are using ScyllaDB Monitoring Stack, you can use the Cache section of the ScyllaDB Per Server dashboard, to see the effect of the BYPASS CACHE command on the cache hit and miss ratio.
-
- More on
BYPASS CACHEhere
- More on
- ALLOW FILTERING enhancements
- Support multi-column restrictions in ALLOW FILTERING #3574
SELECT * FROM t WHERE (c, d) IN ((1, 2), (1,3), (1,4)) ALLOW FILTERING;
SELECT * FROM t WHERE (c, d) < (1, 3) ALLOW FILTERING;
SELECT * FROM t WHERE (c, d) < (1, 3) AND (c, d) > (1, 1) ALLOW FILTERING; - Support restricted column, not in select clause #3803
CREATE TABLE t (id int primary key, id_dup int);— the restriction is applied to a column, which is not in the select clause. In prior versions this command returned incorrect results, but now it works as intended
SELECT id FROM t WHERE id_dup = 3 ALLOW FILTERING; - Support CONTAINS restrictions #3573
CREATE TABLE t (p frozen<map<text, text>>, c1 frozen<list>, c2 frozen<set>, v map<text, text>, id int, PRIMARY KEY(p, c1, c2));SELECT id FROM t WHERE p CONTAINS KEY 'a' ALLOW FILTERING;
SELECT id FROM t WHERE c1 CONTAINS 3 ALLOW FILTERING;
SELECT id FROM t WHERE c2 CONTAINS 0.1 ALLOW FILTERING;
SELECT id FROM t WHERE v CONTAINS KEY 'y1' ALLOW FILTERING;
SELECT id FROM t WHERE v CONTAINS KEY 'y1' AND c2 CONTAINS 3 ALLOW FILTERING;
- Support multi-column restrictions in ALLOW FILTERING #3574
- CQL: Group functions count now works with bytes type #3824
CREATE TABLE t (p INT, c INT, v BOOLEAN, PRIMARY KEY (p, c));
SELECT COUNT(v) FROM t WHERE p = 1 AND c = 1; - Local Secondary Index #4185
Local Secondary Indexes are an alternative to Global Secondary Indexes, allowing ScyllaDB to optimize workloads where the partition key of the base table and the index are the same key.- More on Local Secondary Index
Reduce Storage Space
- Incremental Compaction Strategy (ICS) – introduced in 2019.1.4, ICS is the default compaction strategy in 2020.1
The new ICS compaction strategy is an improvement on the default Size Tiered Compaction Strategy (STCS). While it shares the same read and writes amplification factors as STCS, it fixes its doubling of temporary disk usage issues by breaking huge SSTables into smaller chunks, all of which are named an SSTable run.
While STCS forces you to keep 50% of your storage reserved for temporary compaction allocation, ICS reduces most of this overhead, allowing you to use more of the disk for regular usage. This can translate to using fewer nodes, or storing more data on the existing cluster. For example, a typical node with 4 TB and 16 shards will have less than 20% temporary space amplification with ICS, allowing the user to run at up to 80% capacity. In a follow-up blog post we will provide a deep dive into ICS disk usage saving.
ICS is only available in ScyllaDB Enterprise
More on ICS:
- SSTable “mc” format is enabled by default. Apache Cassandra 3.x SSTable format (mc) has been available in ScyllaDB Open Source since release 3.0, and were also available in ScyllaDB Enterprise 2019.1, but were not enabled by default. In ScyllaDB Enterprise 2020.1, mc formatted tables are now enabled by default. This format can save users significant amounts of disk storage; as much as 50%. Note that you can continue to use the old file format by setting
enable_sstables_mc_format: falsein scylla.yaml.- More on the mc format here
Performance
- Performance: Segregate data by timestamp for Time Window Compaction Strategy (TWCS) #2687
Isolate TWCS from read repair or compaction with an imported SSTable, which may ruin the TWCS file per time range property. - Performance: add ZSTD compression #2613
Adds support for the option to compress SSTables using the Zstandard algorithm from Facebook.
To use, pass'sstable_compression': 'org.apache.cassandra.io.compress.ZstdCompressor'
to the compression argument when creating a table.
You can also specify acompression_level(default is 3). See Zstd documentation for the available compression levels.
Also read our two part blog series on Compression in ScyllaDB: Part One and Part Two.
Example:
create table a.a (a text primary key, b int) with compression = {'sstable_compression': 'org.apache.cassandra.io.compress.ZstdCompressor', 'compression_level': 1, 'chunk_length_in_kb': '64'};
- Performance: Repair improvements in ScyllaDB 3.2:
- Improved data transfer efficiency between nodes. Repair is now switched to use the Seastar RPC stream interface which is more efficient to transfer large amounts of repair data. #4581
- Read our blog on RPC streaming improvements.
- Increased the internal row buffer size to provide better performance on cross DC clusters with high latency links. #4581
- Repair can now adjust ranges to repair in parallel according to memory size #4696
- Improved data transfer efficiency between nodes. Repair is now switched to use the Seastar RPC stream interface which is more efficient to transfer large amounts of repair data. #4581
- Row Level Repair #3033
In partition-level repair (the algorithm used in ScyllaDB Open Source 3.0 and earlier), the repair master node splits the ranges to sub-ranges containing 100 partitions, and computes the checksum of those 100 partitions and asks the related peers to do the same.- If the checksum matches, the data in this subrange is synced, and no further action is required.
- If the checksum mismatches, the repair master fetches the data from all the peers and sends back the merged data to peers.
This approach has two major problems:
-
- A mismatch of only a single row in any of the 100 partitions causes 100 partitions to be transferred. A single partition can be very large, even hundreds of MBs. 100 partitions can be way over one gigabyte of data.
- Checksum (find the mismatch) and streaming (fix the mismatch) will read the same data twice
To fix the two issues above we introduce the new Row-Level Repair. Row-level repair works on a small range which contains only a few rows (a few megabytes of data at most), reads these rows to memory, finds the mismatches and sends them to the peers. By that, it only reads the data once, and significantly reduces the data volume stream for each row mismatch.
In a benchmark done on a three ScyllaDB nodes cluster, on AWS using i3.xlarge instance, each with 1 billion
Rows (241 GiB of data), we tested three use cases:
| Use case | Description | Time to repair | Improvement | |
| ScyllaDB Open Source 3.0 | ScyllaDB Open Source 3.1 | |||
| 0% synced | One of the nodes has zero data. The other two nodes have 1 billion identical rows. | 49.0 min | 37.07 min | x1.32 faster |
| 100% synced | All of the 3 nodes have 1 billion identical rows. | 47.6 min | 9.8 min | x4.85 faster |
| 99.9% synced | Each node has 1 billion identical rows and 1 billion * 0.1% distinct rows. | 96.4 min | 14.2 min | x6.78 faster |
The new row-level repair shines where a small percent of the data is out of sync – the most likely use case in case of short network issues or a node restart.
For the last use case, the bytes sent over the wire:
| ScyllaDB 3.0 | ScyllaDB 3.1 | Transfer Data Ratio | |
| TX | 120.52 GiB | 4.28 GiB | 3.6% |
| RX | 60.09 GiB | 2.14 GiB | 3.6% |
As expected, where the actual difference between nodes is small, sending just relevant rows, not 100 partitions at a time, makes a huge difference.
More on row level repair implementation and results here
- IOCB_CMD_POLL support
On Linux 4.19 or higher, ScyllaDB will use a new method of waiting for network events, IOCB_CMD_POLL. More about the new interface in this lwn.net article.
The new interface is detected and used automatically. To use the old interface, add the command line option --reactor-backend=epoll.
- Materialized Views improvements
- Move truncation records to separate table (#4083)
- BYPASS CACHE clause – introduced in 2019.1.1
The newBYPASS CACHEclause on SELECT statements informs the database that the data being read is unlikely to be read again in the near future, and also was unlikely to have been read in the near past; therefore no attempt should be made to read it from the cache or to populate the cache with the data. This is mostly useful for range scans which typically process large amounts of data with no temporal locality and do not benefit from the cache.
For example:
SELECT * from heartrate BYPASS CACHE;
If you are using ScyllaDB Monitoring Stack, you can use the Cache section of the ScyllaDB Per Server dashboard, to see the effect of the BYPASS CACHE command on the cache hit and miss ratio.
-
- More on
BYPASS CACHEhere
- More on
Security
Encryption at rest – introduced in 2019.1.1, 2019.1.3
You can now encrypt on-disk ScyllaDB data, including:
- SSTables
- Commit logs
- Batch and hints logs
Encryption at rest support three key Providers:
- Local, which allows you to keep keys in the file system for each node.
- Table provider, allows you to store table keys in ScyllaDB Tables and eliminates the need to copy the table key to each server.
- KMIP provider. KMIP is a standard protocol for exchanging keys in a secure way. With this key provider, you can use any KMIP compatible server to secure ScyllaDB Encryption keys.
- More on Encryption at rest here
Known Issues in Encryption at rest:
- DESCRIBE TABLE with encryption at rest parameters does not have the exact same format as CQL CREATE format. The results, schema backup and restore of tables with encryption at rest will require
Tooling
- Snapshot enhancement: a table schema, schema.cql, is now part of each ScyllaDB snapshot created with “nodetool snapshot”. Schema is required as part of the ScyllaDB backup restore procedure. #4192
- Connection virtual table #4820
The new table system.clients table provides information about CQL clients currently connected to ScyllaDB.
Client Information includes: address, port, type, shard, protocol_version and username - Export system uptime via REST endpoint /system/uptime_ms
- Large cell / collection detector
ScyllaDB is not optimized for very large rows or large cells. They require allocation of large, contiguous memory areas and therefore may increase latency. Rows may also grow over time. For example, many insert operations may add elements to the same collection, or a large blob can be inserted in a single operation.
Similar to the large partitions table, the large rows and large cells tables are updated when SSTables are written or deleted, for example, on memtable flush or during compaction.
Examples for using the new Large Rows and Large Cells tables:
SELECT * FROM system.from system.large_rows;
SELECT * FROM system.from system.large_cells;
- Stability:
nodetool scrub --skip-corrupted. As the name suggests, the new option allows scrub to purge corrupt data from the output, by skipping over it.- More on finding Large Rows and Cells
- nodetool toppartitions #2811. Samples cluster writes and reads and reports the most active partitions in a specified table and time frame. For example:
> nodetool toppartitions nba team_roster 5000
WRITES Sampler:
Cardinality: ~5 (256 capacity)
Top 10 partitions:
Partition Count +/-
Russell Westbrook 100 0
Jermi Grant 25 0
Victor Oladipo 17 0
Andre Roberson 1 0
Steven Adams 1 0
READS Sampler:
Cardinality: ~5 (256 capacity)
Top 10 partitions:
Partition Count +/-
Russell Westbrook 100 0
Victor Oladipo 17 0
Jermi Grant 12 0
Andre Roberson 5 0
Steven Adams 1 0
-
- More on nodetool toppartitions here
- Nodetool upgradesstables #4245
Rewrites SSTables for keyspace/table to the latest ScyllaDB version. Note that this is *not* required when enabling mc format, or upgrading to a newer ScyllaDB version. In these cases, ScyllaDB will write new SSTable, either in memtable flush or compaction, while keeping the old tables in the old format.
nodetool upgradesstables ( -a | --include-all-sstables ) --
By default, the command only rewrites SSTables which are *not* of the latest release, -a | –include-all-sstables option can by use to rewrite *all* the sstables.
-
- More on Nodetool upgradesstables here
- The default node_exporter installed from scylla_setup is now 0.17 (updated from 0.14)
Monitoring
ScyllaDB Enterprise 2020.1.0 Dashboard are available with ScyllaDB Monitoring Stack 3.4.1 or later
- For new metrics compare to ScyllaDB Enterprise 2019.1 see here
Stability and bug fixes (from 2019.1.0)
- Date Tiered Compaction Strategy (DTCS) is deprecated and eventually be removed. If you are still using it, please switch to Time Window Compaction Strategy (TWCS).
- API: add error injection to REST API (used for testing only)
- A new API allows enable/disable error injections to different places in the code #3295
- ScyllaDB will now ignore a keyspace that is removed while being repaired, or without tables, rather than failing the repair operation. #5942 #6022
- Local secondary indexes, as well as materialized views that have the same partition key as their base table, are now updated synchronously. This improves consistency and simplifies concurrency control. #4365. Alternator was updated to take advantage of this.
- a new REST API for deleting a table from a snapshot #5805
- CQL: Fix missing aggregate functions for counters
- The long-deprecated RandomPartitioner and ByteOrderedPartitioner partitioners were removed #5636
- Stability: improve CQL server admission control #4768
Current admission control takes a permit when CQL requests start and releases it when a reply is sent, but some requests may leave background work behind after that point. In ScyllaDB 3.2, admission control takes into account these background tasks, and improves the way ScyllaDB handles overload conditions. - Stability: Large collections are now more resistant to memory fragmentation
- Stability: scylla-kernel-conf package which tunes the kernel for ScyllaDB’s needs. It now tunes vm.swappiness, to reduce the probability of the kernel swapping out ScyllaDB memory and introducing stalls.
- “mc” SSTable file format: empty counters were not handled correctly, which could lead to Coredump #4363. Note that mc format is disabled by default in 2019.1. More on mc (Apache Cassandra 3.0 format) here
- Range scan: in a rare condition, a specific combination of data and its alignment in the reader buffer, can lead to missing rows from a range scan #4418. Two things are needed to trigger this defect:
- A range tombstone that has the same start bound as the row just after it in the stream
- This range tombstone is the last fragment in the reader’s buffer, and that the reader is evicted after the buffer is consumed.
- TimeWindowCompactionStrategy: on some very rare cases, a use after free may hurt performance #4465
- Stability: Possible race condition between compaction deleting SSTable and reshuffling of SSTable, for example when migrating data from Apache Cassandra, or ScyllaDB server with a different core number. #4622
- Stability: Catch SSTable unclosed partition format error in the write path, not in the read path. A new command line flag: –abort-on-internal-error makes ScyllaDB exit as soon as such an error occurs, making it easier to catch and debug. #4794, #4786
- Stability: Receiving side of streaming may abort or produce incorrect SSTables when a failure happens on the sender side, generating the following error:
sstables/sstables.cc:1748: void sstables::seal_summary(sstables::summary&, std::experimental::fundamentals_v1::optional&&, std::experimental::fundamentals_v1::optional&&, const sstables::index_sampling_state&): Assertion `first_key' failed.#4789 - Stability: A node restart during repair may cause the node streaming data to it to abort with an error message:
scylla: message/messaging_service.cc:549: seastar::shared_ptr netw::messaging_service::get_rpc_client(netw::messaging_verb, netw::messaging_service::msg_addr): Assertion `!_stopping' failed.#4767
Aborting on shard 1. - Stability: In some cases, when
--abort-on-lsa-bad-allocis enabled, ScyllaDB aborts even though it’s not really out of memory #2924 - Stability: Potential undefined behavior in SSTable cleanup, which may cause a segmentation fault #4718
- Stability: When using MC SSTable format, ScyllaDB might fail to exit gracefully with an out of disk space error: #4614
- Stability: A possible deadlock between connection authentication and the stall detector, in cases where the authentication logic generates a stall #4759
- Stability: Exceptions in index reader are not handled gracefully #4761
- Stability: Fix segmentation faults when replacing expired SSTables #4085
- Stability: ScyllaDB init process: a possible race between role_manager and pasword_authenticator can cause ScyllaDB to exit #4226
- Stability: ScyllaDB exits ungracefully when shutting down while running repair #4589
- CQL: Using tuple in the primary key can fail the large cell detector #4645
- CQL: Using tuples as a clustering key type without using the to_string() implementation, for example, a tuple, will cause the large row detector to exit. #4633
- CQL: Marshalling error when using Date with capital Z for timezone, for example,
'2019-07-02T18:50:10Z'#4641 - Performance: Repair of a single shard range opens RPC connections for streaming on all shards. This is redundant and can exhaust the number of connections on a large machine. Note that ScyllaDB Manager runs repair on a shard by shard basis. Running repairs from nodetool (nodetool repair) will make the issue even worse. #4708
- Performance: improve the efficiency of operations on large collections
- Sec Index: NodeJS driver: For some drivers, for example, NodeJS, paging indexes can end up in an infinite loop of returning pages with 0 results but “has_more_pages” flag set to true #4569
- Sec Index: Filtering may ignore clustering key restrictions if they form a prefix without a partition key #4541
- MV: In rare cases, when a node dies, and *another* node has MV updates to send him, the sending node is notified of other node death just after sending request started. The sending nodes than need to cancel an ongoing request which might cause ScyllaDB to exit #4386
- Sec Index: A partition key index may cause a regular query to fail with “No such index” #4539
- Stability: Fix of handling of schema alterations and evictions in the cache, which may result in a node crash #5127 #5128 #5134 #5135
- Stability: Fix a bug in cache accounting #5123
- Stability: Fix a bug that can cause streaming to a new node to fail with “Cannot assign requested address” error #4943
- Stability: A race condition in node boot can fail the init process #4709
- Stability: Can not replace a node which is failed in the middle of the boot-up process (same root cause as #4709 above) #4723
- Stability: Perftune.py script fails to start with “name ‘logging’ is not defined” error #4958 #4922
- Stability: ScyllaDB may hang or even segfaults when querying system.size_estimates #4689
- Performance: Range scans run in the wrong service level (workload prioritization) (internal #1052)
- Performance: Wrong priority for View streaming slow down user requests #4615
- Hinted handoff:
- Fix races that may lead to use-after-free events and file system level exceptions during shutdown and drain #4685 #4836
- Commit log error “Checksum error in segment chunk at” #4231
- Docker: An issue in command-line options parsing prevents ScyllaDB Docker from starting, reporting “error: too many positional options have been specified on the command line” error #4141
- In-Transit Encryption: Streaming in local DC fails if only inter-DC encryption is enabled #4953
- Stability: non-graceful handling of end-of-disk space state may cause ScyllaDB to exit with a coredump #4877
- Stability: core dump on OOM during cache update after memtable flush, with
!_snapshot->is_locked()failed error message #5327 - Stability: Adding a DC with MV might fail with
assertion _closing_state == state::closed#4948 - Oversized allocation warning in
reconcilable_result, for example, when paging is disabled #4780 - Stability: running manual operations like nodetool compact will crash if the controller is disabled #5016
- Stability: Under heavy read load, the read execution stage queue size can grow without bounds #4749
- Stability: repair: assert failure when a local node fails to produce checksum #5238
- CQL: One second before expiration, TTLed columns return as null values #4263, #5290
- Stability: long-running cluster sees bad gossip generation when a node restarts #5164 (similar to CASSANDRA-10969)
- CQL: wrong key type used when creating non-frozen map virtual column #5165
- CQL: using queries with paging, ALLOW FILTERING and aggregation functions return intermediate aggregated results, not the full one #4540
- Correctness: Hinted handoff (HH) sends counter hints as counter updates when a node targeted by the hint does not exist. This may cause wrong counter value when HH is enabled, Counters are used, and nodes are down. #5833 #4505
- Correctness: wrong encoding of a negative value of type varint. More details in #5656
- Correctness: Materialized Views: virtual columns in a schema may not be propagated correctly #4339
- CQL: error formats field name as a hex string instead of text #4841
- Stability: Running nodetool clearsnapshot can cause a failure, if a new snapshot is created at the exact same time #4554 #4557
- Stability: using an invalid time UUID can cause ScyllaDB to exit. For example
select toDate(max(mintimeuuid(writetime(COLUMN))))#5552 - Stability: out of memory in cartesian product IN queries, where each column filter is multiple by all other filters. For example:
create table tab (
pk1 int, pk2 int, pk3 int, pk4 int, pk5 int, pk6 int, pk7 int, pk8 int, pk9 int,
primary key((pk1, pk2, pk3, pk4, pk5, pk6, pk7, pk8, pk9))
);
select * from tab where pk1 in (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
and pk2 in (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
and pk3 in (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
and pk4 in (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
and pk5 in (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
and pk6 in (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
and pk7 in (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
and pk8 in (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
and pk9 in (1, 2, 3, 4, 5, 6, 7, 8, 9, 10);ServerError: std::bad_alloc
#4752 - Stability: IPv6 – seed nodes do not connect to peers with the scope field #5225
- Stability: a graceful shutdown fais produce an error when Tracing is on
[with Service = tracing::tracing]: Assertion 'local_is_initialized()'#5243 - Stability: running a misformatted ALTER command on a UDT will cause a crash #4837
- Stability: Replace dead node for a seed is allowed but does not work #3889
- Stability: Immediate abort on OS errors EBADF (Bad file number) and ENOTSOCK (Socket operation on non-socket). These errors usually hint on a deeper root cause, and aborting as soon as possible is both safer and makes it easier to analyze.
- Stability: downgrade assert on
row: append(): downgradeto an error. The assertion, introduced in 2019.1.4 proved to be too strict, aborting on cases which are not fatal. - Stability: storage_proxy: limit resources consumed in cross-shard operations
- Performance: New configuration option,
enable_shard_aware_drivers, allows disabling shard aware drivers from the server (ScyllaDB) side - Reduce memory footprint: ScyllaDB keeps SSTable metadata in memory #4915
- Reduce memory footprint: cell locking data structures consume 64KiB of RAM per table #4441
- Install: ScyllaDB installs wrong java version on Ubuntu 18.04 #4548
- Stability:
nodetool scrub --skip-corrupted. As the name suggests, the new option allows scrub to purge corrupt data from the output, by skipping over it. - Stability: write-path validator adds more tests to ScyllaDB write path, identifying potential file format issues as soon as possible.
- Stability: Possible heap-buffer-overflow when stopping the gossip service #5701
- Stability: A rare race condition in range scans might cause the scan to read some data twice, triggering data validation errors which causes ScyllaDB to exit.
- Stability: long-running cluster sees bad gossip generation when a node restarts #5164 (followup to a fix in 2019.1.4)
Active nodes wrongfully marked as DOWN #5800
In some rare cases, scylla node crashing after upgrade to 2019.1.6 when scanning a table containing a partition which has range-tombstones with a prefix start bound right at the end of the partition - Stability: in some rare cases, SSTable metadata in memory is not correctly evicted, causing memory bloat #4951
- CQL: a restricted column that is not in a select clause returns a wrong value #5708
- Stability: Node shutdown may exit when using encryption in transit #5759, Seastar #727
- Performance: scylla doesn’t enforce the use of TSC clocksource #4474
- Stability: wrong hinted handoff logic for detecting a destination node n DN state #4461
- Stability: commit log exception in shutdown #4394
- Stability: potential race condition when creating a table with the same name as a deleted one #4382
- Install: scylla_setup does not present virtio-blk devices correctly on interactive RAID setup #4066
- Stability: malformed replication factor is not blocked in time, causing an error when running
DESCRIBE SCHEMAlater #3801 - Stability: In rare cases, and under heavy load, for example, during repair, ScyllaDB Enterprise might OOM and exit with an error such as “
compaction_manager - compaction failed: std::bad_alloc (std::bad_alloc)”. #3717 - Stability: possible abort when using reverse queries that read too much data #5804
- Stability: writes inserted into memtable may be interpreted using incorrect schema version on schema ALTER of a counter table #5095
- Stability: possible query failure, crash if the number of columns in a clustering key or partition key is more than 16 #5856
- Stability: When speculative read is configured a write may fail even though enough replicas are alive #6123
- Performance: Allow tweaking of slow repairs due to redundant writes for tables with materialized views
- Stability, hinted_handoff: all nodes in the cluster become overloaded (CPU 100% loaded on all shards) after node finishes the “replace node” procedure
- Tooling: nodetool status returns wrong IPv6 addresses #5808
- AWS: Update enhanced networking supported instance list #6540
- CQL: Filtering on a static column in an empty partition is incorrect #5248
- Stability: When a node fails during an ongoing node replace procedure, and then restarted with no data, parts of the token range might end up not assigned to any node #5172
- API: ScyllaDB returns the wrong error code (0000 – server internal error) in response to trying to do authentication/authorization operations that involve a non-existing role. #6363
- Stability: potential use after free in storage service #6465
- Stability: When hinted handoff enabled, commitlog positions are not removed from rps_set for discarded hints #6433 #6422.
- Stability: multishard_writer can deadlock when producer fails, for example when, during a repair, a node fail #6241
- Performance: A few of the local system tables from the `system` namespace, like large_partitions do not use gc grace period to 0, which may result in millions of tombstones being needlessly
kept for these tables, which can cause read timeouts. Local system tables use LocalStrategy replication, so they do not need to be concerned about gc grace period. #6325 - CQL: ALTERing compaction settings for table also sets
default_time_to_liveto 0 #5048 - Stability: ScyllaDB freezes when casting a decimal with a negative scale to a float #6720
- Stability: In a case when using partition or clustering keys which have a representation in memory which is larger than 12.8 KB (10% of LSA segment size), linearization of the large (fragmented) keys may cause undefined behavior #6637
- Correctness: Materialized view updates with future partition tombstones are not correctly generated. When the base table does not have any rows, but it does have a partition tombstone with a given timestamp, inserting a base row with a smaller timestamp will generate an incorrect materialized view update #5793
- Install / Upgrade (RPM): ScyllaDB Enterprise metapackage does not install correct version of scylla-enterprise-conf package #5639
- CQL: Impossible WHERE condition returns a non-empty slice #5799
- Stability: Counter write read-before-write is issued with no timeout, which may lead to unbounded internal concurrency if the enclosing write operation timed out. #5069
- CQL: Using CQL functions Max and Min on data type inet/blob/list/map/set/time/tuple/udt/column returns unexpected result #5139
- CQL Role Based Access Control (RBAC): MODIFY permission is required on all materialized views in order to modify a table. #5205
- CQL: Range deletions for specific columns are not rejected #5728
- Compression: Internode, on the wire, compression is not enabled based on configuration #5963
- Stability: Open RPC stream connection when the reader has no data generate errors:
stream_session - stream_transfer_task: Fail to send to x.x.x.x:0: std::system_error (error system:99, connect: Cannot assign requested address) - Stability: Staging SSTables are incorrectly removed or added to backlog after ALTER TABLE / TRUNCATE #6798
- Stability: Issuing a reverse query with multiple IN restrictions on the clustering key might result in incorrect results or a crash. For example:
CREATE TABLE test (pk int, ck int, v int, PRIMARY KEY (pk, ck));
SELECT * FROM test WHERE pk = ? AND ck IN (?, ?, ?) ORDERED BY ck DESC;
#6171 - Stability: index reader fails to handle failure properly, which may lead to unexpected exit #6924
19 Aug 2020