




By focusing solely on unrepaired data, we made ScyllaDB’s incremental repair 10X faster
Maintaining data consistency in large-scale distributed databases often comes at a high performance cost. As clusters grow and data volume expands rapidly, traditional repair methods often become a bottleneck.
At ScyllaDB, we needed a way to make consistency checks faster and more efficient. In response, we implemented Incremental Repair for ScyllaDB’s tablets data distribution. It’s an optimization designed to minimize repair overhead by focusing solely on unrepaired data.
This blog explains what it is, how we implemented it, and the performance gains it delivered.
What is Incremental Repair?
Before we talk about the incremental part, let’s look at what repair actually involves in a distributed system context. In a system like ScyllaDB, repair is an essential maintenance operation. Even with the best hardware, replicas can drift due to network hiccups, disk failures, or load. Repair detects mismatches between replicas and fixes them to ensure every node has the latest, correct version of the data. It’s a safety net that guarantees data consistency across the cluster.
Incremental repair is a new feature in ScyllaDB (currently available for tablets-based tables). The idea behind it is simple: why worry about data that we have already repaired? Traditional repair scans everything. Incremental repair targets only unrepaired data. Technically, this is achieved by splitting SSTables into two distinct sets: repaired and unrepaired. The repaired set is consistent and synchronized, while the unrepaired set is potentially inconsistent and requires validation.
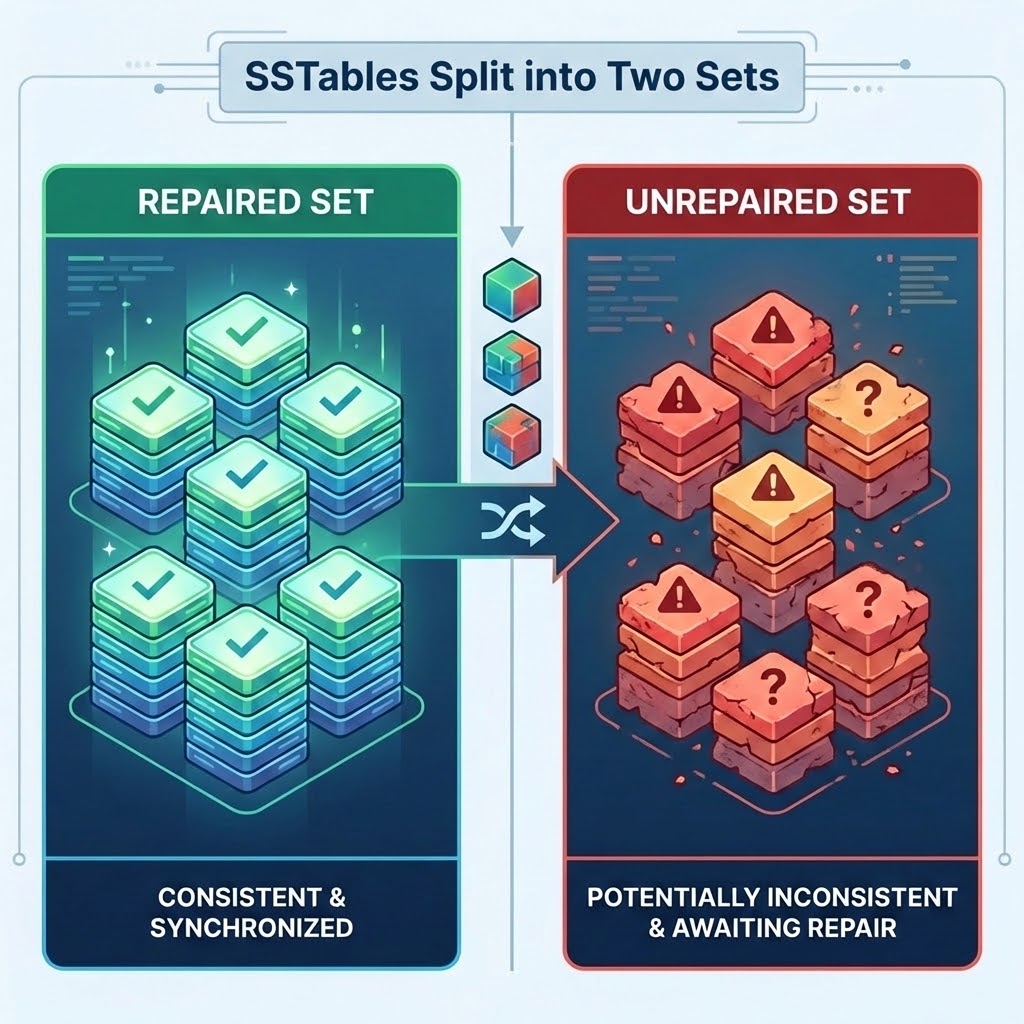
We created two modes of incremental repair: incremental and full. In incremental mode, only SSTables in the unrepaired set are selected for the repair process. Once the repair completes, those SSTables are marked as repaired and promoted into the repaired set. This should be your default mode because it significantly minimizes the IO and CPU required for repair.
In full mode, the incremental logic is still active, but the selection criteria change. Instead of skipping the repaired set, it selects all data (both repaired and unrepaired). Once the process is finished, all participating SSTables are marked as repaired. Think of this as a “trust but verify” mode. Use this when you want to revalidate the entire data set from scratch while still using the incremental infrastructure.
Finally, there’s disabled mode, where the incremental repair logic is turned off. In this case, the repair behavior is exactly the same as in previous versions of ScyllaDB – before the incremental repair feature was introduced. It selects both repaired and unrepaired SSTables for the repair process. After repair completes, the system does not mark SSTables as repaired. This is useful for scenarios where you want to run a repair without affecting the metadata that tracks the repair state.
Incremental repair is integrated directly into the existing workflow, with three options:
- nodetool lets you use the standard nodetool cluster repair command with incremental flags.
- ScyllaDB Manager also supports the same flags for automated scheduling.
- A REST API makes incremental repair available to teams building custom tools.
Making incremental repair work (internals)
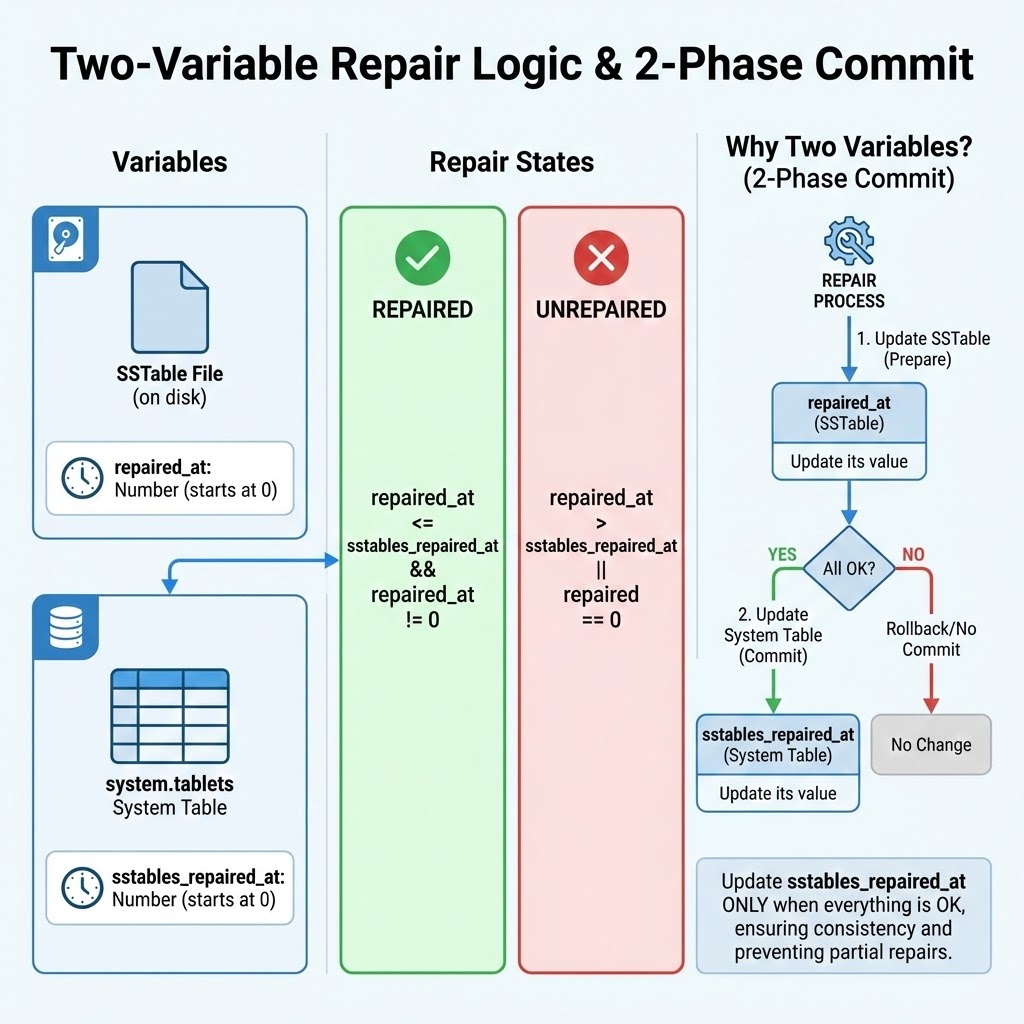
To make incremental repair work, we had to solve a classic distributed systems problem: state consistency. We need to know exactly which data is repaired, and that state must survive crashes. So, we track this using two decoupled markers.
- repaired_at, number stored directly in the SSTable metadata on disk.
- sstables_repaired_at, a value stored in our system tables.
The logic follows a two-phase commit model.
Phase one: prepare. First, we run the row-level repair. Once that is finished, we update the repaired_at value in the SSTables. At this point, the system still treats them as unrepaired because they haven’t been activated yet.
Phase two: commit. After every node confirms the row-level repair and the updated repaired_at value, we update the sstables_repaired_at value in the system table. We define an SSTable as repaired if and only if it is not zero and it is less than or equal to the system’s repaired_at value. If a node crashes between phases, the mismatch between the file and the system table ensures that we don’t accidentally skip data that wasn’t 100% verified.
Under normal operations, you don’t need to run full repairs regularly. Still, it’s needed occasionally. If you experience significant loss of SSTables (perhaps due to a disk failure), then a full repair is required to reconstruct missing data across the cluster. In practice, we suggest one full repair after a long series of incremental runs. This gives you an extra layer of security, even if it is not strictly required.
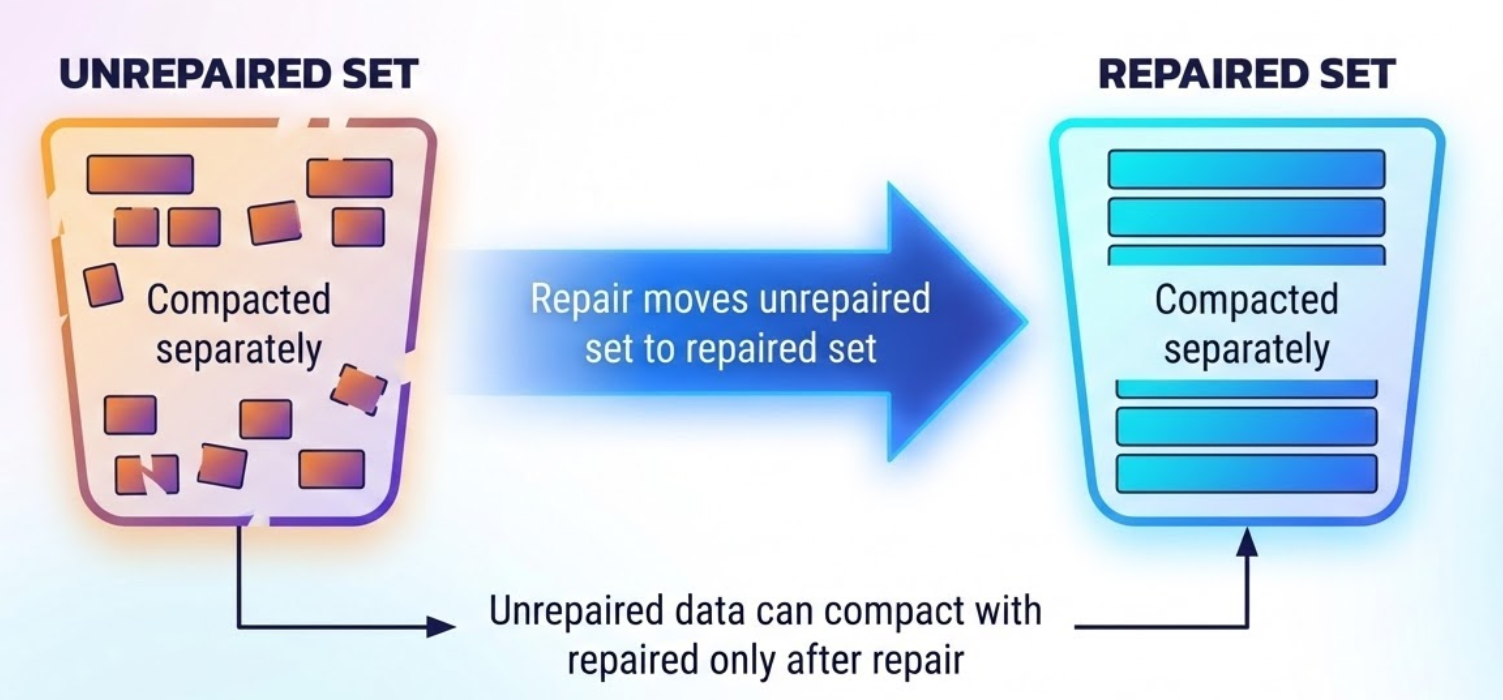
This brings us to a critical challenge: compaction. If we let compaction mix repaired and unrepaired data, the repaired status would be lost, and we’d need to re-repair everything. To solve this, we introduce compaction barriers. We effectively split the tablets into two independent worlds.
- The unrepaired set, where all new writes and memtable flushes go. Compaction only merges unrepaired SSTables with other unrepaired ones.
- The repaired set, where SSTables are compacted together to maintain and optimize the read path.
The rule is that a compaction strategy can never merge an unrepaired SSTable into the repaired set. The only bridge between these sets is repair. This prevents potentially inconsistent data from polluting the repaired set.
With this new design, compaction now has a dependency on repair. As we run repairs, the repaired sets grow. But because incremental repair is so much lighter than traditional methods, we encourage you to run it much more frequently. We are currently working on an automatic repair feature that will trigger those runs at the very moment the unrepaired set grows too large. That should keep your unrepaired window as small as possible.
The efficiency of incremental repair depends on your workload:
- Update heavy: If you have lots of overwrites or deletes, new data will invalidate older repaired SSTables. In extreme cases, there could be so much data to repair that it looks a lot like full repair.
- Append heavy: This is a perfect use case, like IoT or logging. Since new data doesn’t invalidate old data, the repaired set stays consistent and untouched. This should provide nice performance gains.
Even in update-heavy cases, don’t lose anything by choosing incremental repair. In the worst case, it performs the same amount of work as a full repair would. In almost all real-world scenarios, you could gain significant improvements without any trade-off with respect to consistency.
Performance Improvements
To understand how this approach translates to performance improvements, let’s model the improvement ratio. Say that n is the size of your new unrepaired data and E is the size of your existing repaired data. A full repair works on E plus n. Incremental repair works only on n. So, the improvement ratio equals n divided by E plus n.
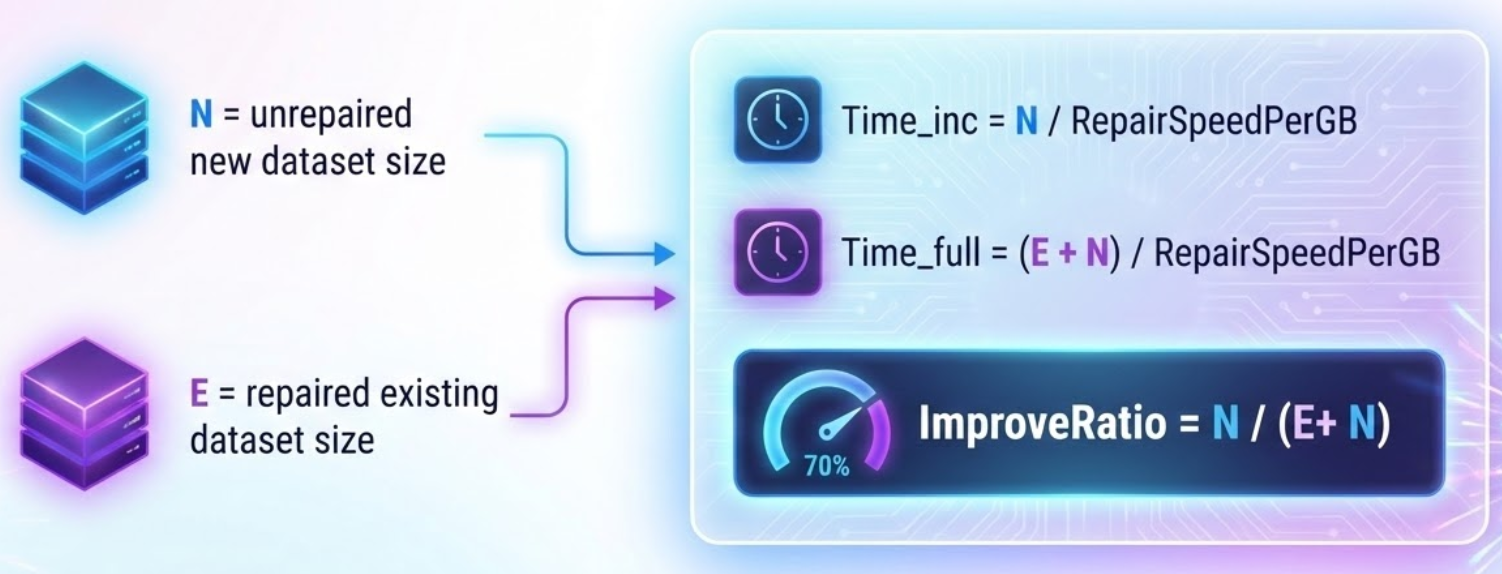
If you ingest 100 gigabytes a day on a 10-terabyte node, you are repairing only 1% of the data instead of 100%. This is an order-of-magnitude shift in overhead.
Our testing confirms that theory. We ran multiple insert and repair cycles.
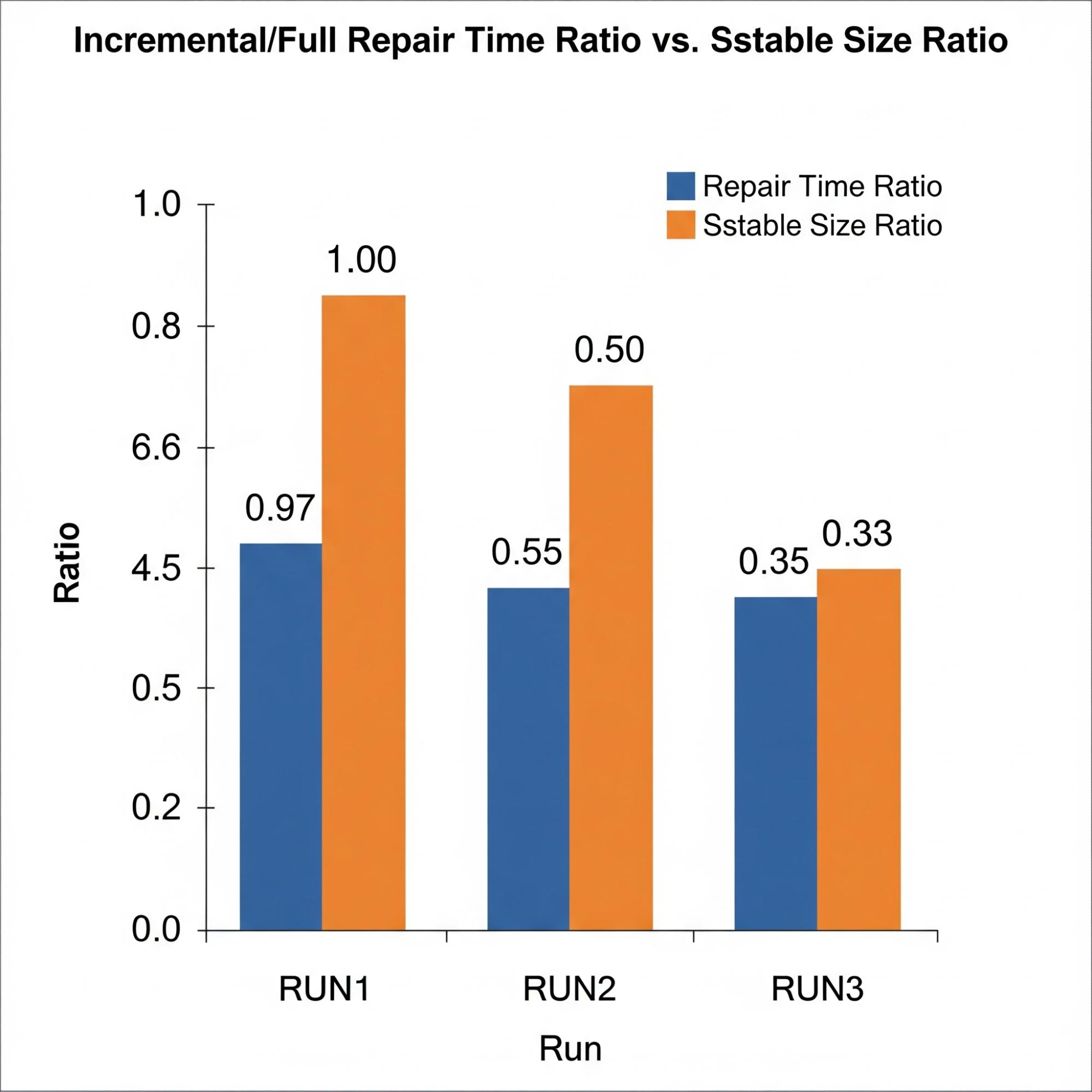
In the first round, nearly all the data was new, so the repair time was almost the same as with full repair. In the second round, with a 50/50 split, the time dropped by half. In the third round, as the repaired set became dominant, incremental repair took only 35% of the time that a full repair would have taken.
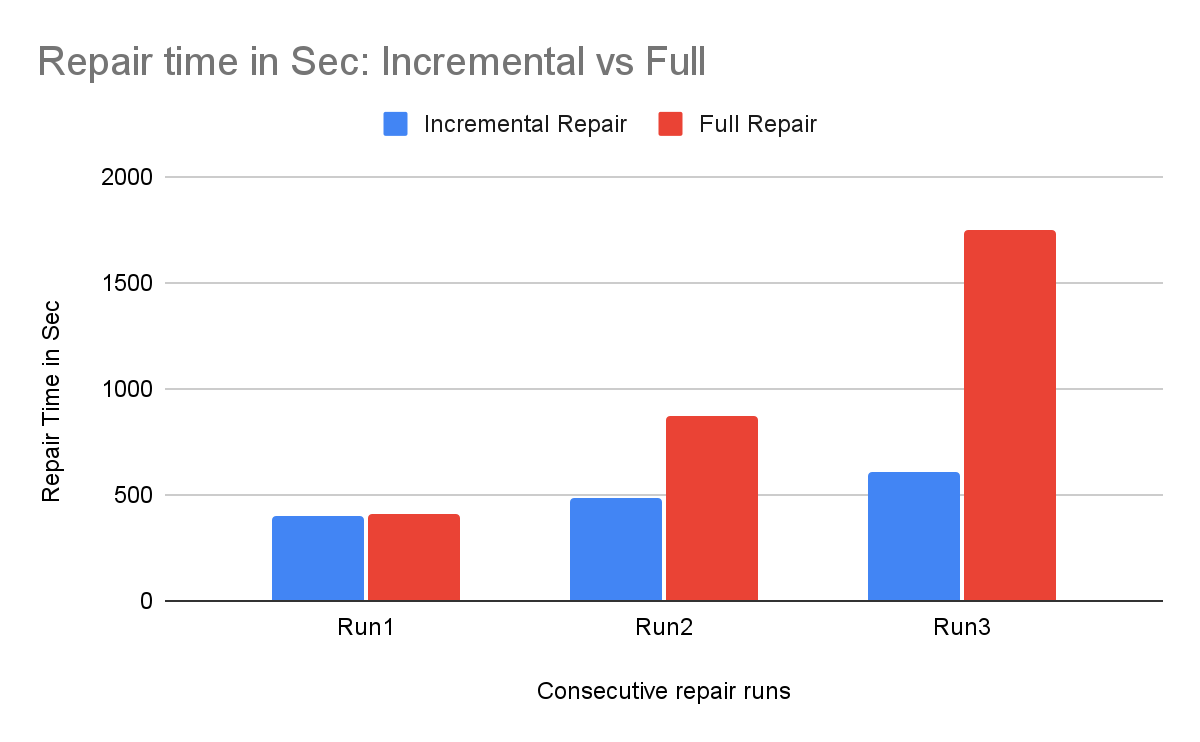
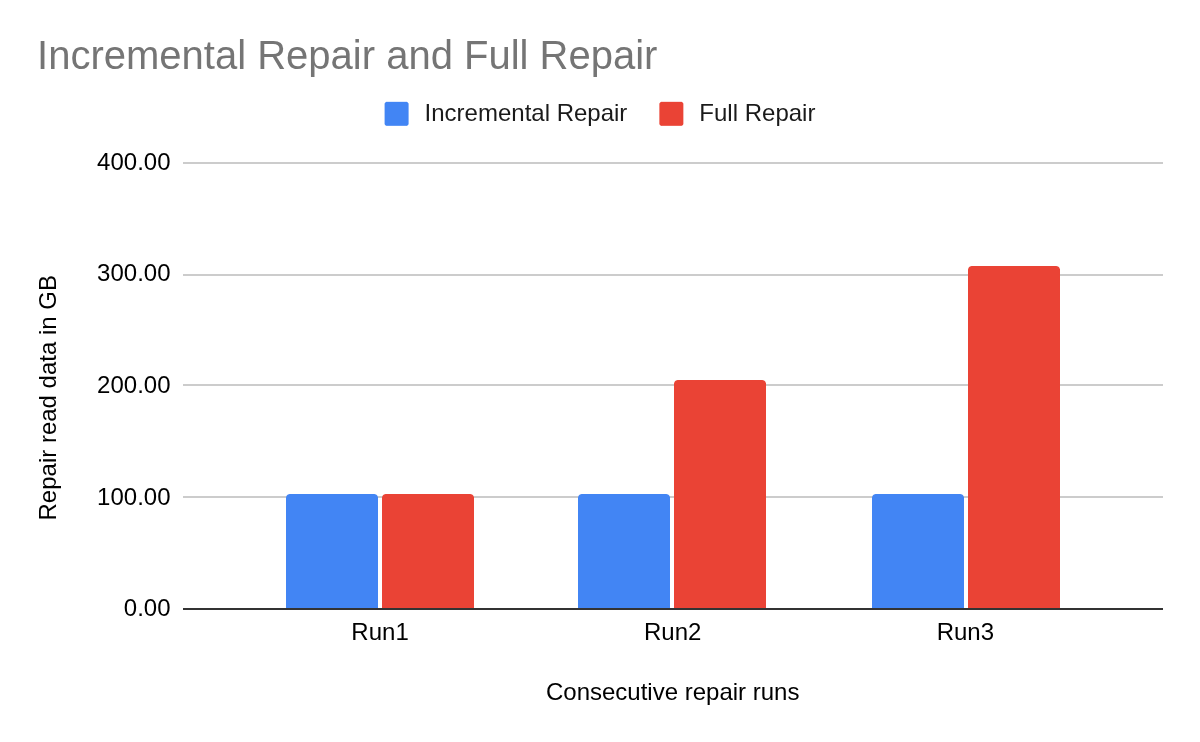 To wrap up, incremental repair for tablets is faster, lighter, and more efficient. It is a foundational step toward our goal of a fully autonomous database that handles its own maintenance. By adopting this feature, you reduce operational burden and ensure your cluster remains consistent without repair storms.
To wrap up, incremental repair for tablets is faster, lighter, and more efficient. It is a foundational step toward our goal of a fully autonomous database that handles its own maintenance. By adopting this feature, you reduce operational burden and ensure your cluster remains consistent without repair storms.



