Get a database engineer’s inside look at how the database interacts with the CPU…in this excerpt from the book, “Database Performance at Scale.”
Note: The following blog is an excerpt from Chapter 3 of the Database Performance at Scale book, which is available for free. This book sheds light on often overlooked factors that impact database performance at scale.
***
A database’s internal architecture makes a tremendous impact on the latency it can achieve and the throughput it can handle. Being an extremely complex piece of software, a database doesn’t exist in a vacuum, but rather interacts with the environment which includes the operating system and the hardware.
While it’s one thing to get massive terabyte-to-petabyte scale systems up and running, it’s a whole other thing to make sure they are operating at peak efficiency. In fact, it’s usually more than just “one other thing.” Performance optimization of large distributed systems is usually a multivariate problem — combining aspects of the underlying hardware, networking, tuning operating systems, or finagling with layers of virtualization and application architectures.
Such a complex problem warrants exploration from multiple perspectives. In this chapter, we’ll begin the discussion of database internals by looking at ways that databases can optimize performance by taking advantage of modern hardware and operating systems. We’ll cover how the database interacts with the operating system plus CPUs, memory, storage, and networking. Then, in the next chapter, we’ll shift focus to algorithmic optimizations.
Note: This blog focuses exclusively on CPUs, but you can access the complete book (free, Open Access).
Working with CPUs
Programming books tell programmers that we have this CPU that can run processes or threads, and what runs means is that there’s some simple sequential instruction execution. Then there’s a footnote explaining that with multiple threads you might need to consider doing some synchronization. In fact, how things actually get executed inside CPU cores is something completely different and much more complicated. It would be very difficult to program these machines if we didn’t have those abstractions from books, but they are a lie to some degree and how you can efficiently take advantage of CPU capabilities is still very important.
Share nothing across cores
Individual CPU cores aren’t getting any faster. Their clock speeds reached a performance plateau long ago. Now, the ongoing increase of CPU performance continues horizontally: by increasing the number of processing units. In turn, the increase in the number of cores means that performance now depends on coordination across multiple cores (versus the throughput of a single core).
On modern hardware, the performance of standard workloads depends more on the locking and coordination across cores than on the performance of an individual core. Software architects face two unattractive alternatives:
- Coarse-grained locking, which will see application threads contend for control of the data and wait instead of producing useful work.
- Fine-grained locking, which, in addition to being hard to program and debug, sees significant overhead even when no contention occurs due to the locking primitives themselves.
Consider an SSD drive. The typical time needed to communicate with an SSD on a modern NVMe device is quite lengthy – it’s about 20 µseconds. That’s enough time for the CPU to execute tens of thousands of instructions. Developers should consider it as a networked device but generally do not program in that way. Instead, they often use an API that is synchronous (we return to this later in the book), which produces a thread that can be blocked.
Looking at the image of the logical layout of an Intel Xeon Processor (Figure 3-1), it’s clear that this is also a networked device.
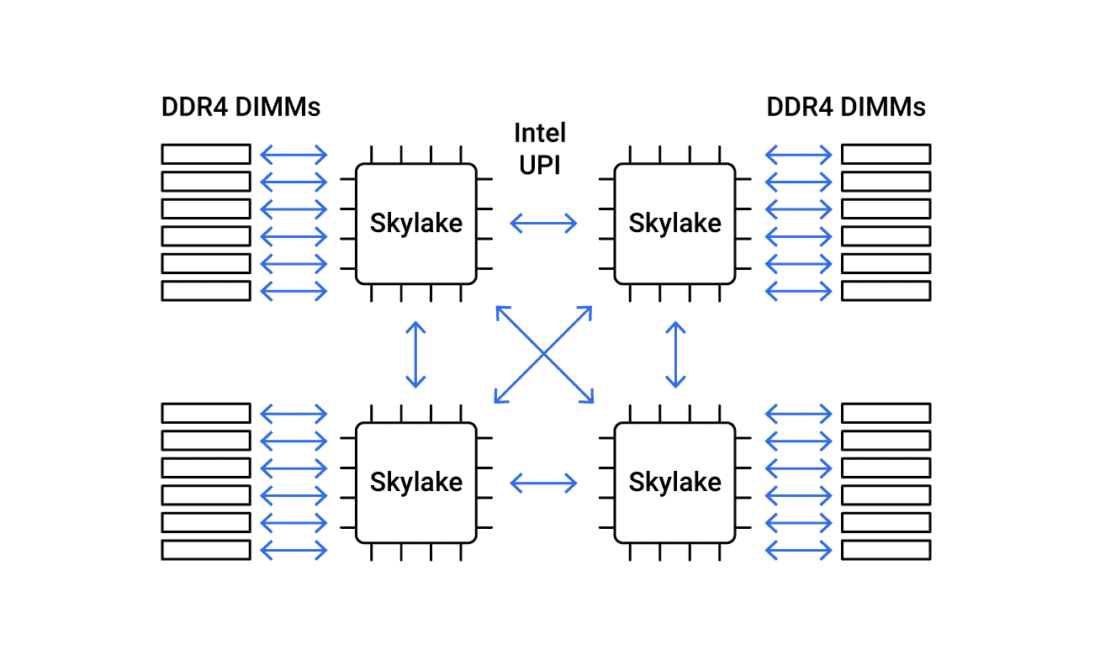
Figure 3-1: The logical layout of an Intel Xeon Processor
The cores are all connected by what is essentially a network — a dual ring interconnect architecture. There are two such rings and they are bidirectional. Why should developers use a synchronous API for that then? Since the sharing of information across cores requires costly locking, a shared-nothing model is perfectly worth considering. In such a model, all requests are sharded onto individual cores, one application thread is run per core, and communication depends on explicit message passing, not shared memory between threads. This design avoids slow, unscalable lock primitives and cache bounces.
Any sharing of resources across cores in modern processors must be handled explicitly. For example, when two requests are part of the same session and two CPUs each get a request that depends on the same session state, one CPU must explicitly forward the request to the other. Either CPU may handle either response. Ideally, your database provides facilities that limit the need for cross-core communication – but when communication is inevitable, it provides high-performance non-blocking communication primitives to ensure performance is not degraded.
Futures-Promises
There are many solutions for coordinating work across multiple cores. Some are highly programmer-friendly and enable the development of software that works exactly as if it were running on a single core. For example, the classic Unix process model is designed to keep each process in total isolation and relies on kernel code to maintain a separate virtual memory space per process. Unfortunately, this increases the overhead at the OS level.
There’s a model known as “futures and promises.” A future is a data structure that represents some yet-undetermined result. A promise is the provider of this result. It can be helpful to think of a promise/future pair as a first-in first-out (FIFO) queue with a maximum length of one item, which may be used only once. The promise is the producing end of the queue, while the future is the consuming end. Like FIFOs, futures and promises are used to decouple the data producer and the data consumer.
However, the optimized implementations of futures and promises need to take several considerations into account. While the standard implementation targets coarse-grained tasks that may block and take a long time to complete, optimized futures and promises are used to manage fine-grained, non-blocking tasks. In order to meet this requirement efficiently, they should:
- Require no locking
- Not allocate memory
- Support continuations
Future-promise design eliminates the costs associated with maintaining individual threads by the OS and allows close to complete utilization of the CPU. On the other hand, it calls for user-space CPU scheduling and very likely limits the developer with voluntary preemption scheduling. The latter, in turn, is prone to generating phantom jams in popular producer-consumer programming templates.
Applying future-promise design to database internals has obvious benefits. First of all, database workloads can be naturally CPU-bound. For example, that’s typically the case with in-memory database engines, and aggregates’ evaluations also involve pretty intensive CPU work. Even for huge on-disk data sets, when the query time is typically dominated by the I/O, CPU should be considered. Parsing a query is a CPU-intensive task regardless of whether the workload is CPU-bound or storage-bound, and collecting, converting, and sending the data back to the user also calls for careful CPU utilization. And last but not least: processing the data always involves a lot of high-level operations and low-level instructions. Maintaining them in an optimal manner requires a good low-level programming paradigm and future-promises is one of the best choices. However, large instruction sets need even more care; this leads us to “execution stages.”
Execution Stages
Let’s dive deeper into CPU microarchitecture because (as discussed previously) database engine CPUs typically need to deal with millions and billions of instructions, and it’s essential to help the poor thing with that. In a very simplified way, the microarchitecture of a modern x86 CPU – from the point of view of Top-Down Analysis – consists of four major components: Front End, Back-End, Branch Speculation, and Retiring.
Front End
The processor’s front end is responsible for fetching and decoding instructions that are going to be executed. It may become a bottleneck when there is either a latency problem or insufficient bandwidth. The former can be caused, for example, by instruction cache misses. The latter happens when the instruction decoders cannot keep up. In the latter case, the solution may be to attempt to make the hot path (or at least significant portions of it) fit in the decoded µop cache (DSB) or be recognizable by the loop detector (LSD).
Branch speculation
Pipeline slots that the Top-Down Analysis classifies as Bad Speculation are not stalled, but wasted. This happens when a branch is mispredicted and the rest of the CPU executes a µop that eventually cannot be committed. The branch predictor is generally considered to be a part of the front end. However, its problems can affect the whole pipeline in ways beyond just causing the back end to be undersupplied by the instruction fetch and decode. (Note: we’ll cover branch mispredictions in more detail a bit later.)
Back End
The back end receives decoded µops and executes them. A stall may happen either because of an execution port being busy or a cache miss. At the lower level, a pipeline slot may be core bound either due to data dependency or an insufficient number of available execution units. Stalls caused by memory can be caused by cache misses at different levels of data cache, external memory latency, or bandwidth.
Retiring
Finally, there are pipeline slots that get classified as Retiring. They are the lucky ones that were able to execute and commit their µop without any problems. When 100% of the pipeline slots are able to retire without a stall, then the program has achieved the maximum number of instructions per cycle for that model of the CPU. Although this is very desirable, it doesn’t mean that there’s no opportunity for improvement. Rather, it means that the CPU is fully utilized and the only way to improve the performance is to reduce the number of instructions.
Implications for Databases
The way CPUs are architectured has direct implications on the database design. It may very well happen that individual requests involve a lot of logic and relatively little data, which is a scenario that stresses the CPU significantly. This kind of workload will be completely dominated by the front end – instruction cache misses in particular. If we think about this for a moment, it shouldn’t really be very surprising though. The pipeline that each request goes through is quite long. For example, write requests may need to go through transport protocol logic, query parsing code, look up in the caching layer, or be applied to the in-memory structure where it will be waiting to be flushed on disk, etc.
The most obvious way to solve this is to attempt to reduce the amount of logic in the hot path. Unfortunately, this approach does not offer a huge potential for significant performance improvement. Reducing the number of instructions needed to perform a certain activity is a popular optimization practice, but a developer cannot make any code shorter infinitely. At some point, the code “freezes” – literally. There’s some minimal amount of instructions needed even to compare two strings and return the result. It’s impossible to perform that with a single instruction.
A higher-level way of dealing with instruction cache problems is called Staged Event-Driven Architecture (SEDA for short). It’s an architecture that splits the request processing pipeline into a graph of stages – thereby decoupling the logic from the event and thread scheduling. This tends to yield greater performance improvements than the previous approach.