




How ScyllaDB is using Raft for all topology and schema metadata – and the impacts on elasticity, operability, and performance
ScyllaDB recently completed the transition to strong consistency for all cluster metadata. This transition involved moving schema and topology metadata to Raft, implementing a centralized topology coordinator for driving topology changes, and several other changes related to our commit logs, schema versioning, authentication, and other aspects of database internals.
With all topology and schema metadata now under Raft, ScyllaDB officially supports safe, concurrent, and fast bootstrapping with versions 6.0 and higher. We can have dozens of nodes start concurrently. Rapidly assembling a fresh cluster, performing concurrent topology and schema changes, and quickly restarting a node with a different IP address or configuration – all of this is now possible.
This article shares why and how we moved to a new algorithm providing centralized (yet fault-tolerant) topology change coordination for metadata, as well as its implications for elasticity, operability, and performance.
A Quick Consistency Catchup
Since ScyllaDB was born as a Cassandra-compatible database, we started as an eventually consistent system. That made perfect business sense for storing user data. In a large cluster, we want our writes to be available even if a link to the other data center is down.

[For more on the differences between eventually consistent and strongly consistent systems, see the blog ScyllaDB’s Path to Strong Consistency: A New Milestone.]
But beyond storing user data, the database maintains additional information, called metadata, that describes:
- Topology (nodes, data distribution…)
- Schema (table format, column names, indexes…)
There’s minimal business value in using the eventually consistent model for metadata. Metadata changes are infrequent, so we do not need to demand extreme availability or performance for them. Yet, we want to reliably change the metadata in an automatic manner to bring elasticity. That’s difficult to achieve with an eventually consistent model.

Having metadata consistently replicated to every node in the cluster allows us to bridge the gap to elasticity, enabling us to fully automate node operations and cluster scaling.
So, back in 2021, we embarked on a journey to bring in Raft: an algorithm and a library that we implemented to replicate any kind of information across multiple nodes. Since then, we’ve been rolling out the implementation incrementally.
Our Move to Schema and Topology Changes on Raft
In ScyllaDB 5.2, we put the schema into a Raft-replicated state. That involved replicating keyspace, table, and column information through Raft. Raft provides a replicated log across all the nodes in the cluster. Everything that’s updated through Raft first gets applied to that log, then gets applied to the nodes (in exactly the same order to all nodes).
Now, in ScyllaDB 6.0, we greatly expanded the amount of information we store in this Raft-based replicated state machine. We also include new schema tables for authentication and service levels. And more interestingly, we moved topology over to Raft and implemented a new centralized topology coordinator that’s instrumental for our new tablets architecture (more on that at the end of this article). We also maintain backward compatibility tables so that old drivers and old clients can still get information about the cluster in the same way.
Driving Topology Changes from a Centralized Topology Coordinator
Let’s take a closer look at that centralized topology coordinator. Previously, the node joining the cluster would drive the topology change forward. If a node was being removed, another node would drive its removal. If something happened to the node driving these operations, the database operator had to intervene and restart the operation from scratch.
Now, there’s a centralized process (which we call the topology change coordinator) that runs alongside the Raft cluster leader node and drives all topology changes. If the leader coordinator node is down, a new node is automatically elected a leader. Since the coordinator state is stored in the deterministic state machine (which is replicated across the entire cluster), the new coordinator can continue to drive the topology work from the state where the previous coordinator left off. No human intervention is required.
Every topology operation registers itself in a work queue, and the coordinator works off that queue. Multiple operations can be queued at the same time, providing an illusion of concurrency while preserving operation safety. It’s possible to build a deterministic schedule, optimizing execution of multiple operations. For example, it lets us migrate multiple tablets at once, call cleanups for multiple nodetool operations, and so on.
Since information about the cluster members is now propagated through Raft instead of Gossip, it’s quickly replicated to all nodes and is strongly consistent. A snapshot of this data is always available locally. That allows a starting node to quickly obtain the topology information without reaching out to the majority of the cluster.
Practical Applications of this Design
Next, let’s go over some practical applications of this design, beginning with the improvements in schema changes that we introduced in ScyllaDB 6.0.
Dedicated Metadata Commit Log on shard 0
The ScyllaDB schema commit log, introduced in ScyllaDB 5.0 and now mandatory in ScyllaDB 6.0, is a dedicated write-ahead log for schema tables. With ScyllaDB 6.0, we started using the same log for schema and topology changes. That brings both linearizability and durability.

This commit log runs on shard 0 and has different properties than the data commit log. It’s always durable, always synced immediately after write to disk. There’s no need to sync the system tables to disk when performing schema changes, which leads to faster schema changes. And this commit log has a different segment size, allowing larger chunks of data (e.g., very large table definitions) to fit into a single segment.
This log is not impacted by the tuning you might do for the data commit log, such as max size on disk or flush settings. It also has its own priority, so that data writes don’t’ stall metadata changes, and there is no priority inversion.
Linearizable schema version
Another important update is the change to how we build schema versions. A schema version is a table identifier that we use internally in intra-cluster RPC to understand that every node has the same version of the metadata. Whenever a table definition changes, the identifier must be rebuilt.
Before, with eventual consistency allowing concurrent schema modifications, we used to rehash all the system tables to create a new version on each schema change. Now, since schema changes are linearized, only one schema change occurs at a time – making a monotonic timestamp just as effective. It turns out that schema hash calculation is a major performance hog when creating, propagating, or applying schema changes. Moving away from this enables a nice speed boost.

With this change, we were able to dramatically improve schema operation (e.g., create table, drop table) performance from one schema change per 10-20 seconds (in large clusters) to one schema change per second or less. We also removed the quadratic dependency of the cost of this algorithm on the size of the schema. It used to be that the more tables you had, the longer it took to add a new table. That’s no longer the case.
We plan to continue improving schema change performance until we can achieve at least several changes per second and increase the practical ceiling for the number of tables a ScyllaDB installation can hold.
Authentication and service levels on Raft
We moved the internal tables for authentication and service levels to Raft as well. Now, they are globally replicated (i.e., present on every node in the cluster). This means users no longer need to adjust the replication factor for authentication after adding or removing nodes.
Previously, authentication information was partitioned across the entire cluster. If a part of the cluster was down and the role definition was on one of the unavailable nodes, there was a risk that this role couldn’t connect to the cluster at all. This posed a serious denial of service problem. Now that we’re replicating this information to all nodes using Raft, there’s higher reliability since the data is present at all nodes. Additionally, there’s improved performance since the data is available locally (and also no denial of service risk for the same reason).
For service levels, we moved from a polling model to a triggering model. Now, service level information is rebuilt automatically whenever it’s updated, and it’s also replicated onto every node via Raft.
Additional Metadata Consistency in ScyllaDB 6.0
Now, let’s shift focus to other parts of the metadata that we converted to strong consistency in ScyllaDB 6.0. With all this metadata under Raft, ScyllaDB now officially supports safe, concurrent, and fast bootstrap. We can have dozens of nodes start concurrently.
Feature Negotiation on Raft
To give you an idea of some of the low-level challenges involved in moving to Raft, consider how we moved little-known ScyllaDB feature called “feature negotiation.” Essentially, this is a feature with details about other features. To ensure smooth upgrades, ScyllaDB runs a negotiation protocol between cluster nodes. A new functionality is only enabled when all of the nodes in the cluster can support it.

But how does a cluster know that all of the nodes support the feature? Prior to Raft, this was accomplished with Gossip. The nodes were gossiping about their supported features, and eventually deciding that it was safe to enable them (after every node sees that every other node sees the feature).
However, remember that our goal was to make ScyllaDB bootstraps safe, concurrent, and fast. We couldn’t afford to continue waiting for Gossip to learn that the features are supported by the cluster. We decided to propagate features through Raft. But we needed a way to quickly determine if the cluster supported the feature of feature propagation through Raft. It’s a classic “chicken or the egg” problem.
The solution: in 6.0, when joining a node, we offload its feature verification to an existing cluster member. The joining node sends its supported feature set to the cluster member, which then verifies whether the node is compatible with the current cluster. Beyond the features that this node supports, this also includes such things as the snitch used and the cluster name. All that node information is then persisted in Raft. Then, the topology coordinator decides whether to accept the node or to reject it (because it doesn’t support some of the features).
The most important thing to note here is that the enablement of any cluster features is now serialized with the addition of the nodes. There is no race. It’s impossible to concurrently add a feature and add a node that doesn’t support that feature.
CDC Stream Details on Raft
We also moved information about CDC stream generation to Raft. Moving this CDC metadata was required in order for us to stop relying on Gossip and sleeps during boot. We use this metadata to tell drivers that the current distribution of CDC has changed because the cluster topology changed – and it needs to be refreshed.
Again, Gossip was previously used to safely propagate this metadata through the cluster, and the nodes had to wait for Gossip to settle. That’s no longer the case for CDC metadata. Moving this data over to Raft on group0, with its dedicated commit log, also improved data availability & durability.
Additional Updates
Moreover, we implemented a number of additional updates as part of this shift:
- Automated SSTable Cleanup : In ScyllaDB 6.0, we also automated the SSTable cleanup that needs to run between (some) topology changes to avoid data resurrection. Sometimes even a failed topology change may require cleanup. Previously, users had to remember to run this cleanup. Now, each node tracks its own cleanup status (whether the cleanup is needed or not) and performs the cleanup. The topology coordinator automatically coordinates the next topology change with the cluster cleanup status.
- Raft-Based UUID host identification: Internally, we switched most ScyllaDB subsystems to Raft-based UUID host identification. These are the same identifiers that Raft uses for cluster membership. Host id is now part of every node’s handshake, and this allows us to ensure that a node removed from the cluster cannot corrupt cluster data with its write RPCs. We also provide a safety net for the database operators: if they mistakenly try to remove a live node from the cluster, they get an error. Live nodes can be decommissioned, but not removed.
- Improved Manageability of the Raft Subsystem: We improved the manageability of the Raft subsystem in ScyllaDB 6.0 with the following:
- A new system table for Raft state inspection allows users to see the current Raft identifiers, the relation of the node to the Raft cluster, and so on. It’s useful for checking whether a node is in a good state – and troubleshooting if it is not.
- New Rest APIs allow users to manually trigger Raft internal operations. This is mainly useful for troubleshooting clusters.
- A new maintenance mode lets you start a node even if it’s completely isolated from the rest of the cluster. It also lets you manipulate the data on that local node (for example, to fix it or allow it to join a different cluster). Again, this is useful for troubleshooting.
We plan to continue this work going forward.
Raft is Enabled – and It Enables Extreme Elasticity with Our New Tablets Architecture
To sum up, the state of the topology, such as tokens, was previously propagated through gossip and eventually consistent. Now, the state is propagated through Raft, replicated to all nodes and is strongly consistent. A snapshot of this data is always available locally, so that starting nodes can quickly obtain the topology information without reaching out to the leader of the Raft group.
Even if nodes start concurrently, token metadata changes are now linearized. Also, the view of token metadata at each node is not dependent on the availability of the owner of the tokens. Node C is fully aware of node B tokens (even if node B is down) when it bootstraps.
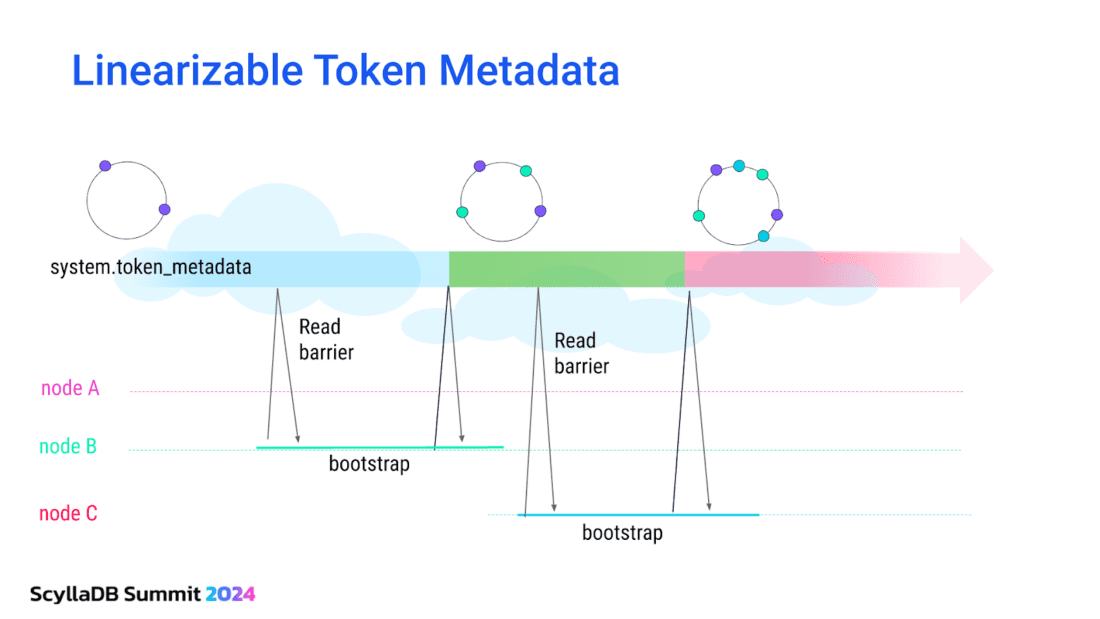
Raft is enabled by default, for both schema and topology, in ScyllaDB 6.0 and higher. And it now serves as the foundation for our tablets replication implementation: the tablet load balancer could not exist without it.
Learn more about our tablets initiative overall, as well as its load balancer implementation, in the following blogs:
- Smooth Scaling: Why ScyllaDB Moved to “Tablets” Data Distribution
- How We Implemented ScyllaDB’s “Tablets” Data Distribution



