




Some very strange error reporting performance issues we uncovered while working on per-partition query rate limiting — and how we addressed it through C++ exception handling
In Retaining Goodput with Query Rate Limiting, I introduced why and how ScyllaDB implemented per-partition rate limiting to maintain stable performance under stress by rejecting excess requests to maintain stable goodput. The implementation works by estimating request rates for each partition and making decisions based on those estimates. And benchmarks confirmed how rate limiting restored goodput, even under stressful conditions, by rejecting problematic requests.
However, there was actually an interesting behind-the-scenes twist in that story. After we first coded the solution, we discovered that the performance wasn’t as good as expected. In fact, we were achieving the opposite effect of what we expected. Rejected operations consumed more CPU than the successful ones. This was very strange because tracking per-partition hit counts shouldn’t have been compute-intensive. It turned out that the problem was related to how ScyllaDB reports failures: namely, via C++ exceptions.
In this article, I will share more details about the error reporting performance issues that we uncovered while working on per-partition query rate limiting and explain how we addressed them.
On C++ (and Seastar) Exceptions
Exceptions are notorious in the C++ community. There are many problems with their design, of course. But the most important and relevant one here is the unpredictable and potentially degraded performance that occurs when an exception is actually thrown. Some C++ projects disable exceptions altogether for those reasons. However, it’s hard to avoid exceptions because they’re thrown by the standard library and because they interact with other language features.
Seastar, an open-source C++ framework for I/O intensive asynchronous computing, embraces exceptions and provides facilities for handling them correctly. Since ScyllaDB is built on Seastar, the ScyllaDB engineering team is rather accustomed to reporting failures via exceptions. They work fine, provided that errors aren’t very frequent.
Under overload, it’s a different story though. We noticed that throwing exceptions in large volumes can introduce a performance bottleneck. This problem affects both existing errors such as timeouts and the new “rate limit exception” that we tried to introduce.
This wasn’t the first time that we encountered performance issues with exceptions. In libstdc++, the standard library for GCC, throwing an exception involves acquiring a global mutex. That mutex protects some information important to the runtime that can be modified when a dynamic library is being loaded or unloaded. ScyllaDB doesn’t use dynamic libraries, so we were able to disable the mutex with some clever workarounds. As an unfortunate side effect, we disabled some caching functionality that speeds up further exception throws. However, avoiding scalability bottlenecks was more important to us.
Exceptions are usually propagated up the call stack until a try..catch block is encountered. However, in programs with non-standard control flow, it sometimes makes sense to capture the exception and rethrow it elsewhere. For this purpose, std::exception_ptr can be used. Our Seastar framework is a good example of code that uses it. Seastar allows running concurrent, asynchronous tasks that can wait for the results of each other via objects called futures. If a task results in an exception, it is stored in a future as std::exception_ptr and can be later inspected by a different task.
future<> do_thing() {
return really_do_thing().finally([] {
std::cout << "Did the thing\n";
});
}
future<> really_do_thing() {
if (fail_flag) {
return make_exception_future<>(
std::runtime_error("oh no!"));
} else {
return make_ready_future<>();
}
}Seastar nicely reduces the time spent in the exception handling runtime. In most cases, Seastar is not interested in the exception itself; it only cares about whether a given future contains an exception. Because of that, the common control flow primitives such as then, finally etc. do not have to rethrow and inspect the exception. They only check whether an exception is present. Additionally, it’s possible to construct an “exceptional future” directly, without throwing the exception.
Unfortunately, the standard library doesn’t make it possible to inspect an std::exception_ptr without rethrowing it. Because each exception must be inspected and handled appropriately at some point (sometimes more than once), it’s impossible for us to eliminate throws if we want to use exceptions and have portable code. We had to provide a cheaper way to return timeouts and “rate limit exceptions.” We tried two approaches.
Approach 1: Avoid The Exceptions
The first approach we explored was quite heavy-handed. It involved plowing through the code and changing all the important functions to return a boost::result. That’s a type from the boost library that holds either a successful result or an error. We also introduced a custom container for holding exceptions that allows inspecting the exception inside it without having to throw it.
future<result<>> do_thing() {
return really_do_thing().then(
[] (result<> res) -> result<> {
if (res) {
// handle success
} else {
// handle failure
}
}
);
}This approach worked, but had numerous drawbacks. First, it required a lot of work to adapt the existing code: return types had to be changed, and the boost::result returned by the functions had to be explicitly checked to see whether they held an exception or not. Moreover, those checks introduced a slight overhead on the happy path.
We applied this approach to the coordinator logic.
Approach 2: Implement the Missing Parts
Another approach: create our own implementation for inspecting the value of std::exception_ptr. We encountered a proposal to extend the std::exception_ptr’s interface that included adding the possibility to inspect its value without rethrowing it. The proposal includes an experimental implementation that uses standard-library specific and ABI-specific constructs to implement it for some of the major compilers. Inspired by it, we implemented a small utility function that allows us to match on the exception’s type and inspect its value, and replaced a bunch of try..catch blocks with it.
std::exception_ptr ep = get_exception();
if (auto* ex
= try_catch(ep)) {
// ...
} else if (auto* ex
= try_catch(ep)) {
// ...
} else {
// ...
}This is how we eliminated throws in the most important parts of the replica logic. It was much less work than the previous approach since we only had to get rid of try-catch blocks and make sure that exceptions were propagated using the existing, non-throwing primitives. While the solution is not portable, it works for us since we use and support only a single toolchain at a time to build ScyllaDB. However, it can be easy to accidentally reintroduce performance problems if you’re not careful and forget to use the non-throwing primitives, including the new try_catch. In contrast, the first approach does not have this problem.
Results: Better Exception Handling, Better Throughput (and Goodput)
To measure the results of these optimizations on the exception handling path, we ran a benchmark. We set up a cluster of 3 i3.4xlarge AWS nodes with ScyllaDB 5.1.0-rc1. We pre-populated it with a small data set that fits in memory. Then, we ran a write workload to a single partition. The data included in each request is very small, so the workload was CPU bound, not I/O bound. Each request had a small server-side timeout of 10ms.
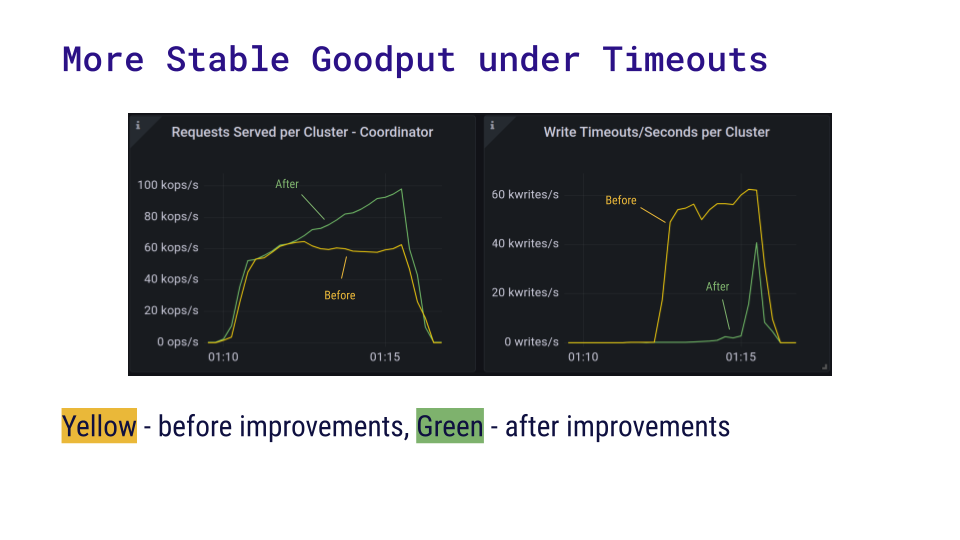
The benchmarking application gradually increases its write rate from 50k writes per second to 100k. The chart shows what happens when ScyllaDB is no longer able to handle the throughput. There are two runs of the same benchmark, superimposed on the same charts – a yellow line for ScyllaDB 5.0.3 which handles timeouts in the old, slow way, and a green line for ScyllaDB 5.1.0-rc1 which has exception handling improvements.
The older version of ScyllaDB became overwhelmed somewhere around the 60k writes per second mark. We were pushing the shard to its limit, and some requests inevitably failed because we set a short timeout. Since processing timed out requests is more costly than processing a regular request, the shard very quickly entered a state where all requests that it processed resulted in timeouts.
The new version, which has better exception handling performance, was able to sustain a larger throughput. Some timeouts occurred, but they did not overwhelm the shard completely. Timeouts don’t start to be more prominent until the 100k requests per second mark.
Summary
We discovered unexpected performance issues while implementing a special case of ScyllaDB’s per-partition query rate limiting. Despite Seastar’s support for handling exceptions efficiently, throwing exceptions in large volumes during overload situations became a bottleneck, affecting both existing errors like timeouts and new exceptions introduced for rate limiting. We solved the issue by using two different approaches in different parts of the code:
- Change the code to pass information about timeouts by returning boost::result instead of throwing exceptions.
- Implement a utility function that allows catching exceptions cheaply without throwing them.
Benchmarks with ScyllaDB versions 5.0.3 and 5.1.0-rc1 demonstrated significant improvements in handling throughput with better exception handling. While the older version struggled and became overwhelmed around 60k writes per second, the newer version sustained larger throughput levels with fewer timeouts, even at 100k requests per second. Ultimately, these optimizations not only improved exception handling performance but also contributed to better throughput and “goodput” under high load scenarios.


