I’m pleased to announce that we’ve closed another round of funding for ScyllaDB. This latest round, which brings us to a total of $35M in funding, was preemptive. That is, we had an opportunity to secure it well in advance of actually needing it. We’re glad for the opportunity this has given us to work with new investor TLV Partners, to double down on Sales and Marketing, and to accelerate our answer to the growing demand for ScyllaDB as a service.
I’d like to take this opportunity to also share some of our recent successes and a glimpse of where we’re headed.
After four years in development, our ScyllaDB database is now mature enough in terms of product stability and feature set, and distinct enough in the market to bring us a rapidly growing roster of users. From Fortune 50s to start-ups and across any number of industries, companies are increasingly choosing ScyllaDB and benefiting from their decision.
I’ve long been asked where we would focus our efforts as a company. My answer has always been the same: processing Big Data in real time. All industries now require processing more and more data, so growth is orthogonal to a vertical or use case. We continue to receive validation for our chosen focus with each new user. Customers like IBM, who delivers its DBaaS and Graph database as a service with ScyllaDB as a backend. Or Samsung, who uses ScyllaDB for IoT in its factories. Or our growing roster of AdTech companies such as AppNexus, AdGear, RocketFuel, GroundTruth, DAC consortium and more. We’re the choice of research institutes such as Los Alamos National Labs and CERN. We have web-scale users such as Discord, Musical.ly, Zen.ly, and Yotpo; and financial services companies such as Investing.com and Orwell Group. With all the advancements in autonomous car technology, we are happy to have our first automotive customer in nAuto. (And to all those customers we are not allowed to name here and those soon-to-be users currently in POC, we thank you as well.)
As you might expect, the majority of our customers migrated to ScyllaDB off of Apache Cassandra or the Datastax fork, but a healthy 30% came to us from other databases they had outgrown–including Redis, Hbase, Mongo and DynamoDB. Turns out it’s hard to resist a database that combines the best performance, the best high availability and ease of use. As you can see, we’re not afraid to speak highly of ourselves. 🙂 Maybe that’s why we sometimes hear from new users that they were initially skeptical of our performance claims, only to quickly become true believers who move more and more of their applications to ScyllaDB.
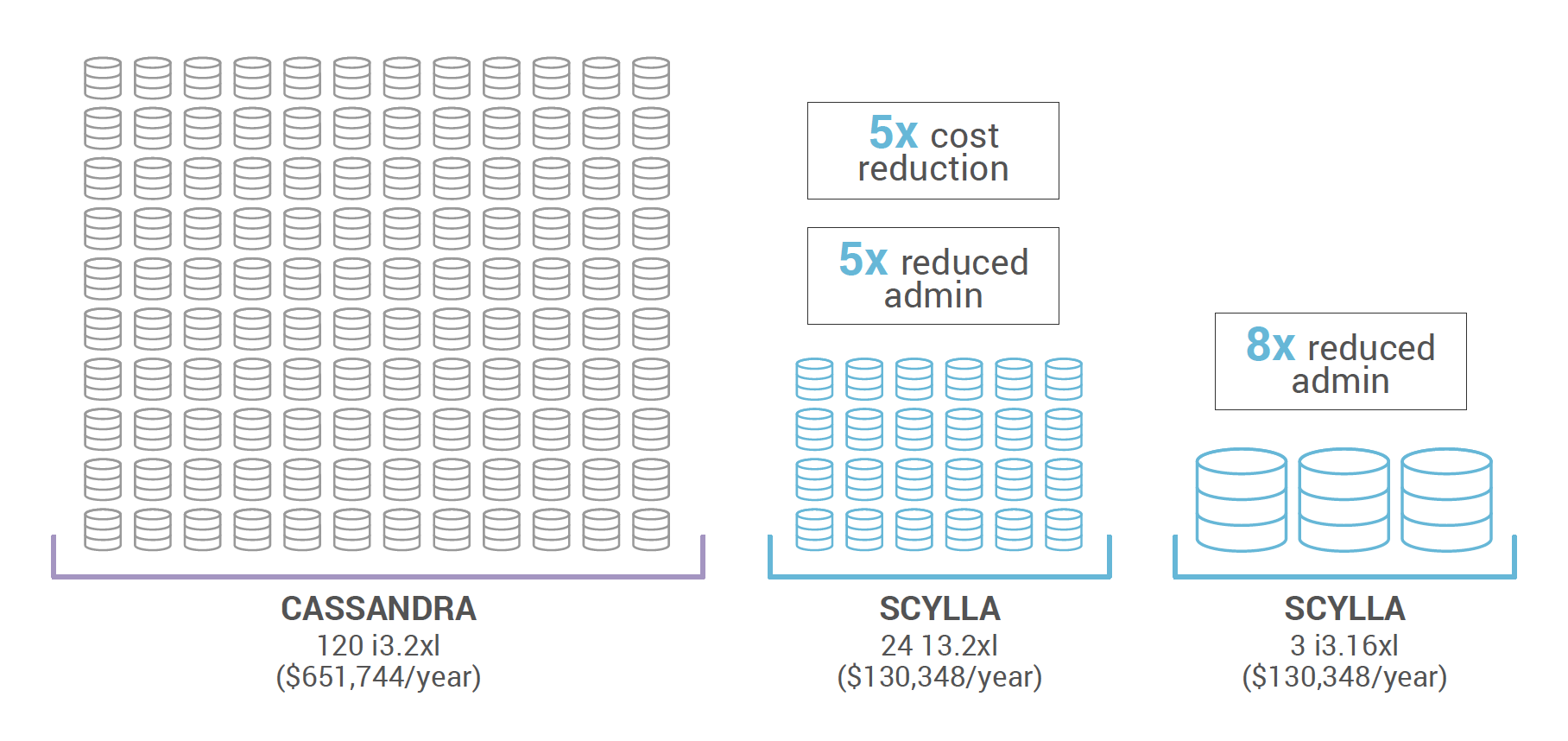
A recent customer example illustrates why we’re gaining such favor. A user went from a cluster of 120 i3.2xl Cassandra nodes to only 24 i3.2xl ScyllaDB nodes, cutting their server costs by a factor of five. But that’s not the end of the story. Since ScyllaDB scales up so well, they were subsequently able to switch to larger nodes, with more CPUs and disks. They needed only 3 ScyllaDB nodes of i3.16xl to sustain the workload of the original 120 small Cassandra nodes. That’s 1/40th the maintenance time! Just think of how much time it takes to conduct a rolling upgrade for a 120-node cluster compared to a 3-node cluster. For a closer look at how we do this, we encourage you to watch our recent webinar on scaling up versus scaling out.
DBaaS on Our Horizon
It’s no secret we’re working on an as-a-service offering in response to the high demand we’ve received. In fact, there are already several companies that provide ScyllaDB as a service. We’re making our best effort to release our DBaaS offering as soon as possible–look for it in the second half of this year. Customers around the world will have the best NoSQL platform available as a service, on demand, at any scale. This will mean significant advantages compared to a service like DynamoDB:
- 5X Cost Reduction: ScyllaDB is engineered much more efficiently with our close-to-the-hardware design. With many of our algorithms derived from Cassandra, which originated from the Dynamo paper, you can think of Dynamo as our forefather. While Dynamo encourages you to add a cache in front, we do the opposite–thereby eliminating cost and complexity.
- No Vendor Lock-in: ScyllaDB is fully open source. We allow multi-cloud deployments that not only reduce lock-in, but also improve the overall reliability of the system, with different datacenters running on different cloud vendors. We also support a hybrid mode with a mix of on-premise and cloud that can further reduces costs.
- Better Performance: ScyllaDB’s latency is as much as 4X better.
- Better Observability: Our comprehensive monitoring allows you to track any metric and to detect slow queries, bottlenecks and hot partitions.
- Better Flexibility: Wide partitions, up to 10’s of GBs each, full support of time-series use cases, larger blobs and better behavior during hot partitions or failures.
We’ve Been Busy
I’d also like to cover some of our accomplishments since our ScyllaDB Summit last November:
- We added the CPU scheduler, which is about to be available in our 2.2 release.
- Wide partition row caching: Release 2.2 includes row-level caching and eviction.
- We released Hinted Handoff in experimental mode–it’s being GA’ed as we speak.
- We introduced our ScyllaDB Manager, which initially offers fully automated repair with RESTful API and management of multiple clusters.
- We’ve completed experimental versions of Materialized Views (which are nearing GA) and Secondary Indexes.
- We will ship our new Enterprise release with audit support. ScyllaDB Enterprise 2018.1 is based on our Open Source release 2.1.
- We finalized all of Cassandra’s compaction strategies, from size-tiered to timed-window, and we’re about to release a hybrid strategy that combines the benefits of size-tiered and level compaction.
Going Forward
Each year we go through an exercise of choosing the main themes for our upcoming developments. We group improvements into coherent themes in order to magnify the end-user benefits. Our themes for 2017 were stability, performance and Cassandra compatibility.
We’re actively working on the last two important Cassandra features on our list. Our master branch can read SSTable version 3.x code and it won’t be long until we’ll release full C* 3.0. And our best team is now starting on the long-anticipated Lightweight Transactions. (We know some of our customers will be delighted to hear this.) Our goal is always perfection, and sometimes that means completing fewer features with better quality. As an example, even though our Materialized Views support is more mature than Apache Cassandra’s we still define it as experimental mode, where it will remain until we completely smooth out the last of the rough edges.
While there are a few small items that we need to borrow from Cassandra (JSON support was just committed), we see 2018 as the year in which we’ve assumed a true leadership role in the industry–not only in our product advantages or our rapid growth, but also in the way other vendors have started to follow our lead. One example is Instagram, who were struggling with Garbage Collection until they replaced Cassandra’s Java-based storage with the RocksDB library in C++. It was no surprise to us that they got better latencies as a result. Another recent example is Datastax, who finally adopted a thread-per-core approach and switched to asynchronous direct memory access I/O. If one needed validation that the existing solutions in the market aren’t adequate and users need better performance and cost reduction, these examples are perfect illustrations of it.
Performance isn’t something you bolt on. A highly performant database needs to be designed that way from the ground up. The tiniest interruption and there goes your 99% latency! It’s on these principles that we’ve been building ScyllaDB for the past 4 years. Our user space schedulers, memory and compaction controllers and our shared-nothing memory allocators allow us to provide full Service Level Agreement support for the database operation, and we are about to utilize them to provide differentiation for analytics vs real-time workloads on the same cluster and more.
While looking ahead at another 4 years, 8 years and 12 years of development, we respect legacy APIs and unlike other projects we retain Thrift support. Users should not have to be forced to rewrite their old applications, and there should be a balance between innovation and maintenance–especially by database vendors.
With all of that said, here are our 2018 development themes:
- Performance is, of course, an everlasting theme. We’ve already made a couple of big performance enhancements — xxhash, GCC o3 and row granularity eviction for wide partitions. There is an ongoing paging and range scan improvement planned to land in our 2.3 release, a big revoke of our in-memory representation, improving the RAM:disk ratio, latency improvements, compaction controllers and more.
- Last bits of Cassandra compatibility. We’re committed to forward support of Cassandra.
- Manageability and automation—everything from Stable RESTful APIs, ScyllaDB Manager with automatic repairs to fully provision clusters and Kubernetes support
- Client drivers—we’ve finally outgrown the existing feature set and we’re ready to innovate in the client/server protocol. There are lots of performance improvements we can achieve and we wish to grow our experience towards the entire database boundaries, and even beyond
- Storage—while ScyllaDB improved performance and simplicity, we haven’t reduced the storage volume. We are going to invest a lot in this direction.
- Per-user SLAs for real-time operations vs analytics. We’ll harness our schedulers to provide different SLAs for real-time workloads while providing best effort for analytics workloads. Today, our schedulers prioritize foreground operations over background operations such as repairs, streaming, and compaction. Once tagged appropriately, we will allow different SLAs per user. Imagine that your full table scan workloads run without interfering the real-time operations. The best practice for heavy analytic workloads today is to separate it to a different, additional, virtual DC. This is a huge price to pay, a full 1x to 3x DC clone. What if this clone will be eliminated entirely?
So much for celebrating our new funding! We’ve got a lot of work to do, so I’ll stop tipping our competitors and get back to the tasks at hand. Before I do, however, I want to encourage you to have a look at our careers page. If you’re a rock star who wants to be part of the technology that is changing how companies do real-time Big Data, we should talk!