It is time to start processing data gathered from applications more efficiently. Applications typically gather large amounts of data over time from different sources and data types such as from IoT devices and microservices applications. Traditional data warehouses use ETL (Extract, Transform, Load) strategies which are batch-driven at specific time intervals and each component talked to every other component through messaging queues. This creates a management nightmare because custom scripts move data from their sources to destinations as one-offs along with many single points of failure and there is not a way to analyze the data in real-time. A more efficient way to address these problems is to have a streaming platform for applications to consume and produce data. One way to do this is with tools like Apache Kafka along with KSQL.
Apache Kafka is a high-throughput distributed streaming platform adopted by hundreds of companies to manage their real-time data. KSQL is an open source streaming SQL engine by Confluent.io that implements continuous, interactive queries against Apache Kafka™. KSQL makes it easy to read, write and process streaming data in real-time, at scale, using SQL-like semantics.
Let’s look at how easy it is to write a KSQL query. In this scenario, we have a stream of data that tracks logging attempts. If the count of the logging attempts is more than three, we will consider it fraudulent. If you are familiar with SQL syntax, the example below should look very familiar to what you already work with.

With Kafka Connect, users will be able to access and store their data with solutions such as ScyllaDB. ScyllaDB is a perfect compliment to Kafka because it leverages the best from Apache Cassandra in high availability, fault tolerance, and its rich ecosystem. ScyllaDB provides a dramatically higher-performing and resource effective NoSQL database to power modern and demanding applications with low latencies and none of the Java garbage collection woes found in other NoSQL databases.
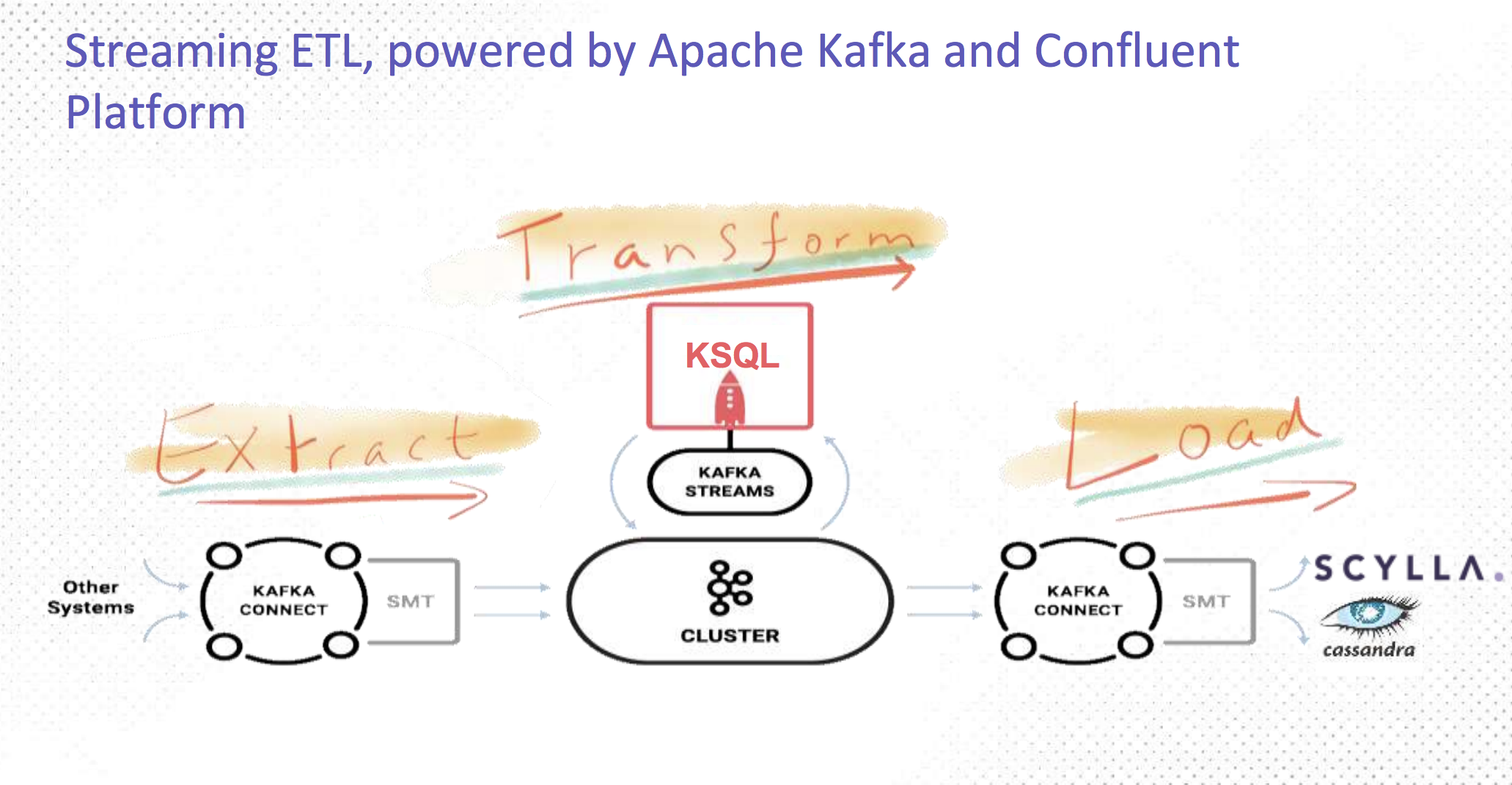
To learn more about KSQL, watch the video at the beginning of this post which includes a live demo, or view the slides below to learn more:
Want to learn more about ScyllaDB? Check out our download page to run ScyllaDB on AWS, install it locally in a Virtual Machine, or run it in Docker.