




For a long time, permanent storage has been the bottleneck in most computer systems. ScyllaDB operates under that assumption and includes a fully-featured userspace disk I/O Scheduler that is used to guarantee that different tasks in the database get their fair share of the disk.
The I/O Scheduler is the central component at the heart of ScyllaDB’s workload conditioning promise: to automatically adjust the database’s distribution of requests to adapt to the incoming workload. It is capable of providing Quality-of-Service (QoS) among the various tasks in the database and isolating them from each other.
Since database systems tend to be I/O-bound, the I/O Scheduler also helps with limiting the use of other resources like the CPU. That happens because the internal database tasks have limited parallelism and will only generate more work once the currently pending work completes. As the I/O Scheduler reorders and prioritizes some I/O requests, the tasks with deferred I/O naturally slow down and decrease their CPU usage.
One example of the above is compactions. As ScyllaDB’s I/O Scheduler steers resources away from compactions, the current compaction tasks have to sit down and wait for the current reads and writes to complete and will not use the CPU either. ScyllaDB enforced the desired rate of CPU usage as a natural consequence of controlling the rate of I/O.
Enter the NVMe
Disks keep getting faster day by day. Modern NVMe devices are incredibly faster than their predecessors. As they are bundled together in RAID arrays, we are presented with extremely fast storage systems. Amazon’s recently released i3 family of machines are advertised as capable of performing up to 3.3 million IOPS and up to 16 GB/s. The speed of modern storage arrays is often enough to shift the bottlenecks somewhere else. And if I/O requests won’t block, what can we expect of the system?
Writing and compacting data
Let’s look at a very simple example of a 1-node ScyllaDB cluster with 1 CPU using a NVMe device receiving a write-only workload limited to 20k writes/second for 5 minutes. The disk/CPU speed ratio, in this case, is even more in favor of the disk as compared to the Amazon i3 instances because the single CPU now has the entirety of the 1.5GB/s that this NVMe device can serve all for itself.
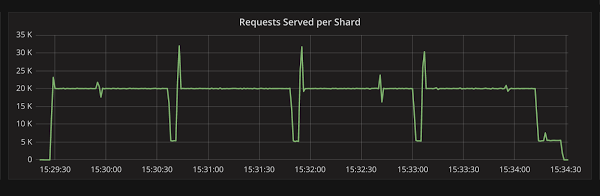
Figure 1: Dips in the throughput graph are memtable flushes. Memtable flushes are fast, but without the disk offering a bottleneck, they can become too fast.
Figure 1 shows the results of running this workload. It is mostly constant at 20k writes/second, until a memtable flush comes, generating a pulse-like event. Throughput gets lowered for the duration of the flush, and then grows later as the loader tries to keep the requested average of 20k writes/second.
Flushing one memtable is extremely fast. But as the disk doesn’t pose any limit to its execution, those tasks dominate the execution for some time, which reduces throughput temporarily and affects the higher percentile latencies.
Users that seek overall throughput may be pleased to see their background tasks finishing so quickly, but users seeking latency will be displeased to see periods in which their requests are much slower.
Compactions are no different. ScyllaDB allows compactions to take the disks to 100 % utilization trusting that the I/O Scheduler will provide QoS between compactions and the rest of the system which allows for our very fast compaction times but without the disks providing the I/O Scheduler with the chance to do request prioritization, compactions may end up dominating the CPU.
Enter Workload Conditioning Part 2: CPU Utilization
As we officially debut support for the Amazon i3 family in ScyllaDB 2.0, this is a good time to have this problem solved. We applied a simple and primitive CPU scheduler to memtable flushes and compaction tasks. A more capable and feature-rich CPU scheduler design is already merged to the Seastar project and will land in ScyllaDB 2.1, but for now, this will do.
ScyllaDB 2.0 users will be able to control the maximum quota of CPU used by background tasks like compactions and memtable flushes when the system is saturated. It is important to stress the word saturated here. If no other tasks are using the CPU, background tasks will still happily use the remainder. But when competing with foreground tasks, their impact in the system is capped. In particular, with an idle system, background tasks running alone can still achieve 100% utilization.
That still leaves us with the problem of figuring out what is the best maximum quota of CPU used by the background tasks. Statically setting quotas is tricky and error-prone. If set too low, work accumulates. If set too high, it affects foreground tasks too much. Ideally, we would like this quota to be determined automatically in response to varying workloads.
In future versions of ScyllaDB, our goal is to automatically adjust this quota to provide the best response to varying workloads. And while compactions will have to be handled with a static quota for the moment, ScyllaDB 2.0 users can already take advantage of our algorithm to automatically determine the optimal quota for memtable flushes.
The determination of the optimal memtable flush quota is done by implementing an Integral Controller that boosts the quota of CPU utilization for memtable flushes when they fall behind while reducing it when we notice that they become too fast. More specifically, the Integral Controller is able to spread the work needed by flush operations so that it finishes about the same time as the next flush is ready to start, but not later. All of that automatically, and robust relative to changing conditions.
As an experimental feature, in ScyllaDB 2.0, we will enable it by default in our official 2.0 AMIs when running on i3 hardware. Future versions will enable the feature everywhere. Users that want to experiment with this and take advantage of this feature can enable it in their systems.
Results
Let’s now run again the same workload we ran in Figure 1 except that this time we will enable this feature.
The results can be seen in Figure 2. Our initial version of the CPU scheduler can properly isolate memtable flushes, and the memtable controller can set them to the right speed, making them as fast as they can be but not so fast that the foreground load is disrupted. For compactions, we still can’t determine the rate automatically. But by guaranteeing that upon contention we’ll cap the CPU usage of compaction tasks, ScyllaDB is able to reduce the higher percentile latencies without sacrificing compaction speed too much.

Figure 2: The CPU controller is now able to make sure that memtable flushes and compactions don’t disrupt the foreground load, which is now a lot more stable.
The same can be seen in the following outputs for the benchmarks:
Before:
op rate : 18810 [WRITE:18810] latency mean : 0.6 [WRITE:0.6] latency median : 0.5 [WRITE:0.5] latency 95th percentile : 0.8 [WRITE:0.8] latency 99th percentile : 3.6 [WRITE:3.6] latency 99.9th percentile : 4.5 [WRITE:4.5] latency max : 39.5 [WRITE:39.5]
After:
op rate : 20019 [WRITE:20019] latency mean : 0.4 [WRITE:0.4] latency median : 0.4 [WRITE:0.4] latency 95th percentile : 0.6 [WRITE:0.6] latency 99th percentile : 0.8 [WRITE:0.8] latency 99.9th percentile : 1.9 [WRITE:1.9] latency max : 30.4 [WRITE:30.4]
Conclusion
Since its early days, ScyllaDB shipped with a disk I/O Scheduler that makes sure that background requests don’t interfere with foreground requests. As disks become faster, some systems may cease to be disk-bound and will become CPU-bound.
A fully fledged CPU controller is in the works, which will isolate all kinds of requests and workloads from each other. In ScyllaDB 2.0, we presented a preview of this work that is capable of isolating compactions and memtable flushes from the foreground load.
We have demonstrated that enabling those experimental options can greatly improve high percentile latencies and provide results that are a lot more consistent.


