




How much data can you store in a single ScyllaDB node?
A reduced node count translates to ease of operations and lower capital expenses. Using ScyllaDB, developers and database operators can store and retrieve at least twice the amount of data in nodes compared to Apache Cassandra-based systems.
In our recent benchmarks, ScyllaDB handled twice the amount of ingested data, while Apache Cassandra-based systems failed to sustain the workload or stay afloat with the amount of data ingested.
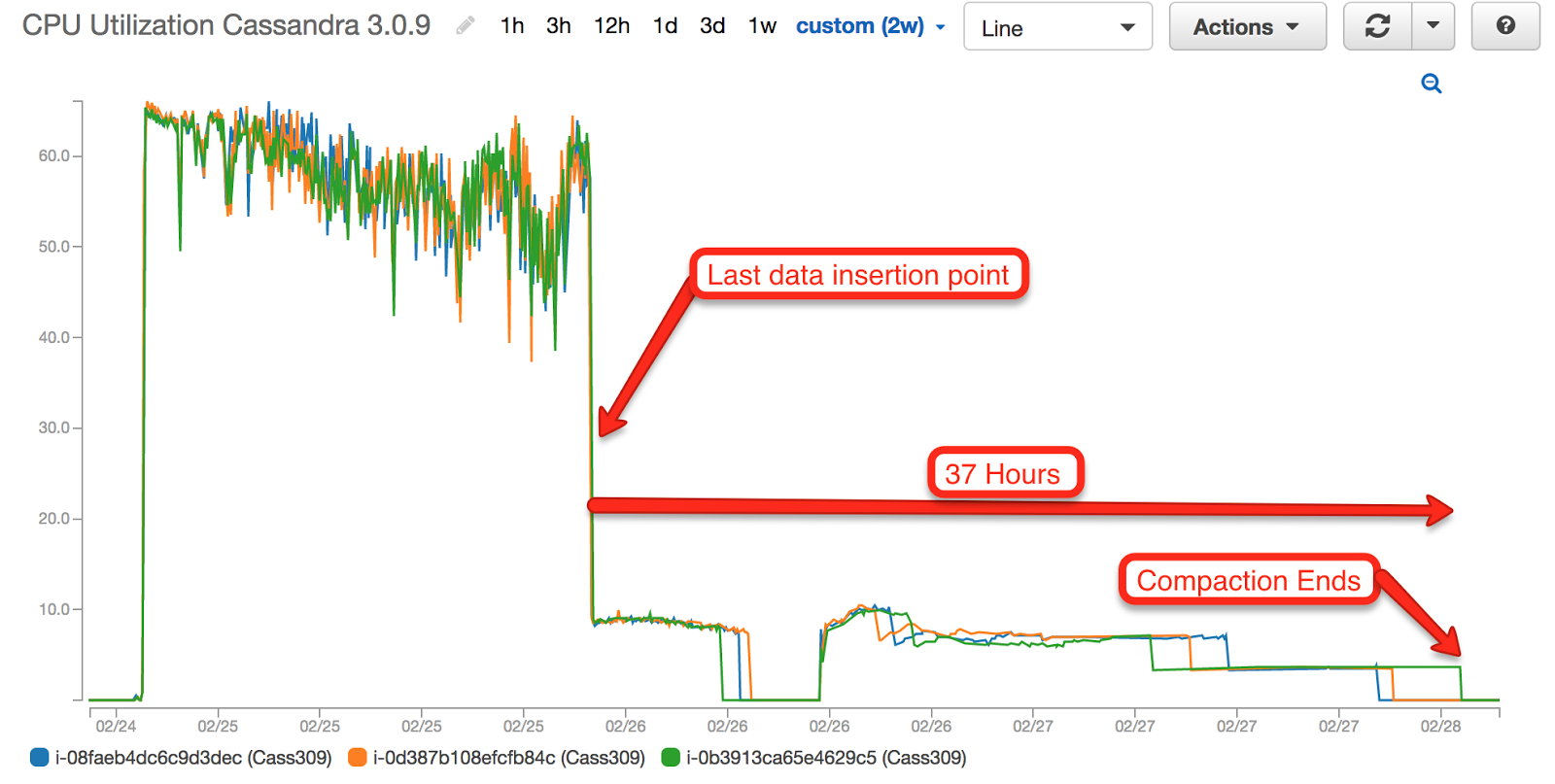
Furthermore, a look into the workload shows that while ScyllaDB ingested 1.3TB of data in less than 12 hours including compaction, Apache Cassandra 3.0.9 took over 28 hours to ingest the data, plus an additional 37 hours to complete the compaction process. ScyllaDB was five times faster than Apache Cassandra.
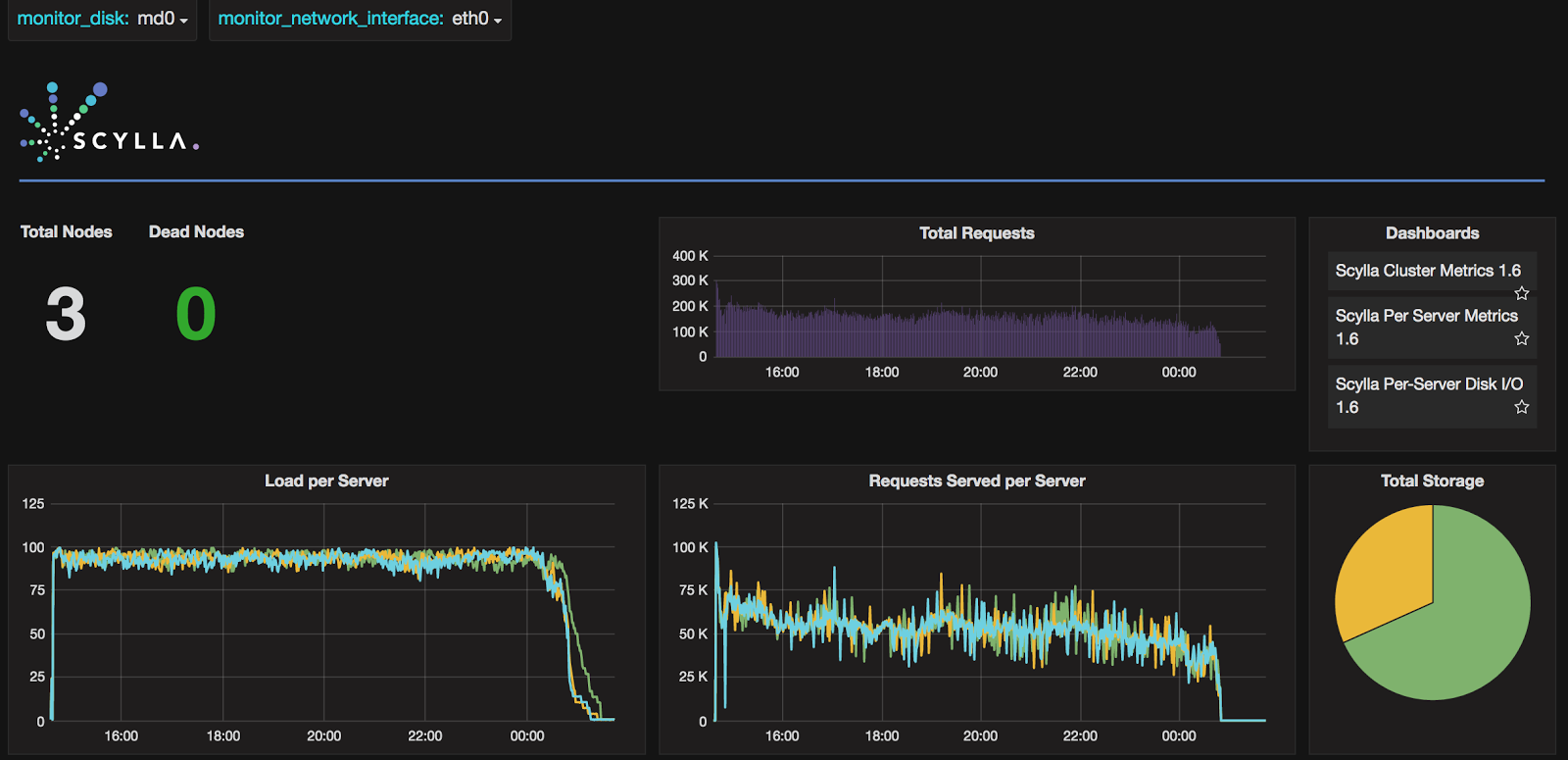
The benchmarks above used Amazon Web Services (AWS) Elastic Compute Cloud (EC2) instances. The instance type used is i2.8xlarge: 32 vCPU, 244GB DRAM and 8x800GB SSDs. Using larger instances of ScyllaDB helps operators condense their clusters’ footprint and lowers the management burden without compromising performance or high availability. (Note: Performance and pricing are even better with i3 – watch this space for a new blog post soon!)
You can read much more about the benchmark here.
Apache®, Apache Cassandra®, are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.


