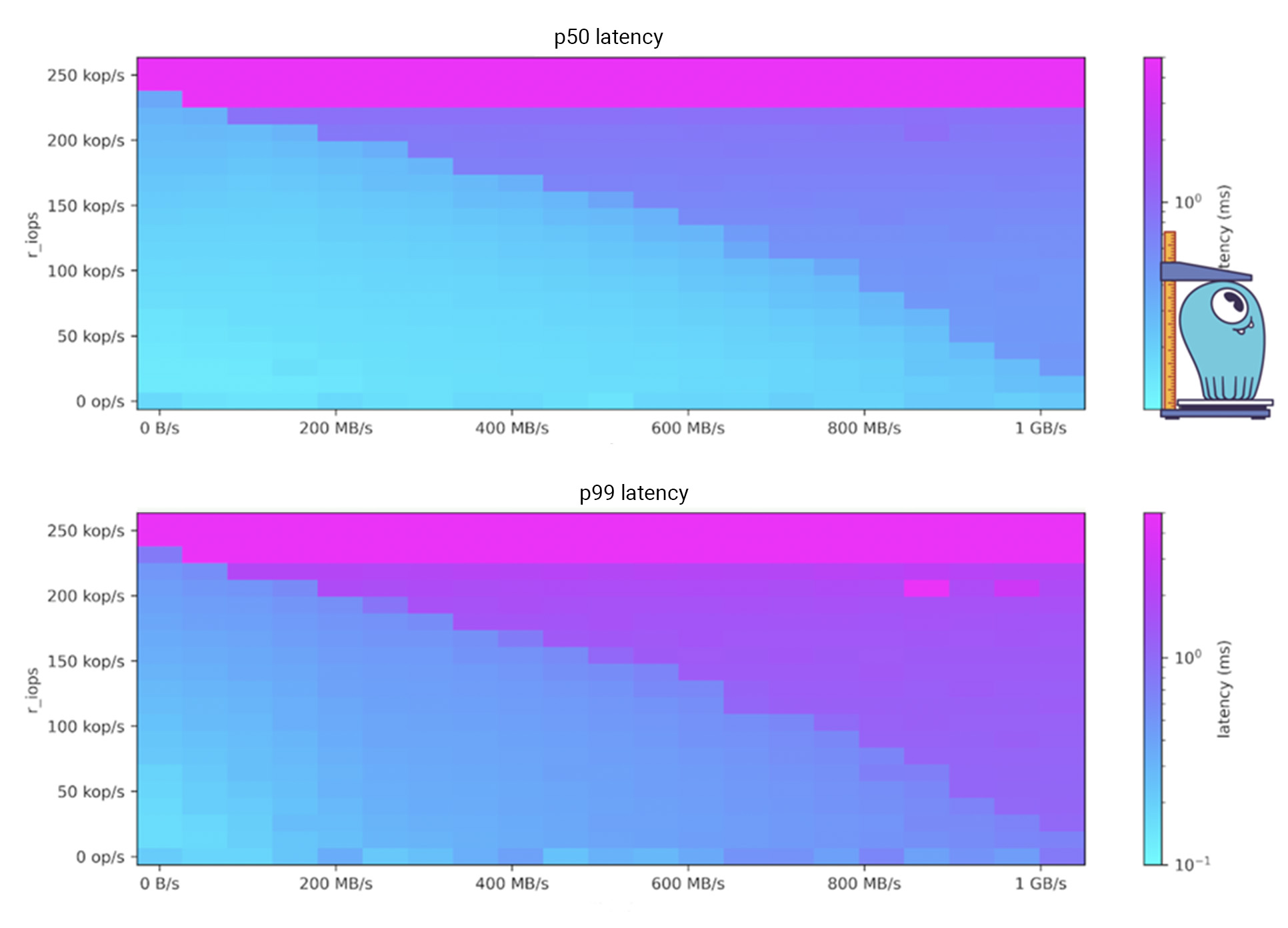
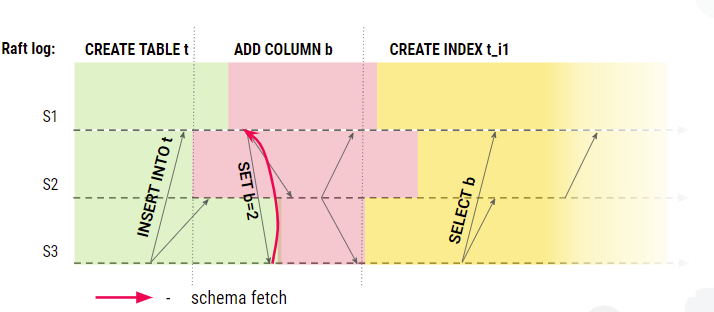
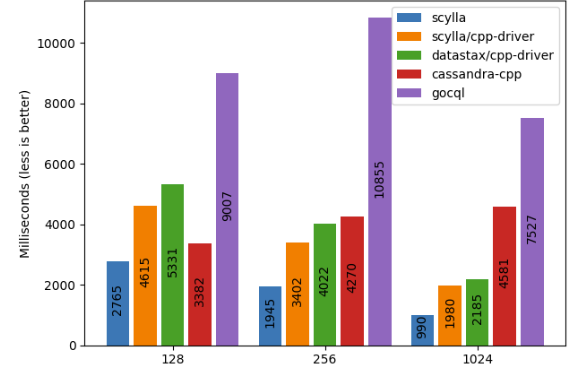
As users increasingly move to ScyllaDB Cloud, they can no longer use admin tools like nodetool or update the scylla.yaml config file directly. Instead, ScyllaDB moved much of the functionality to Virtual Tables, making the information and configuration available via the programmatically friendly CQL data API.