



Cassandra Column Family FAQs
What is a Column Family in Cassandra?
In the Cassandra data model, data is stored in clusters. Cassandra clusters are the outermost container of the distributed Cassandra database which operates across multiple machines. Each machine has its own replica in case of failure, acting as a node. These nodes are arranged in a ring format as a cluster.
The Cassandra Keyspace is a data container in the Cassandra data model, and has these basic attributes:
- Replication factor. The replication factor signifies how many copies of a data will be present in a cluster on nodes.
- Replica placement strategy. The replica placement strategy replicates Cassandra cluster data. It uses either a simple strategy for one data center or for multiple data centers, network topology strategy.
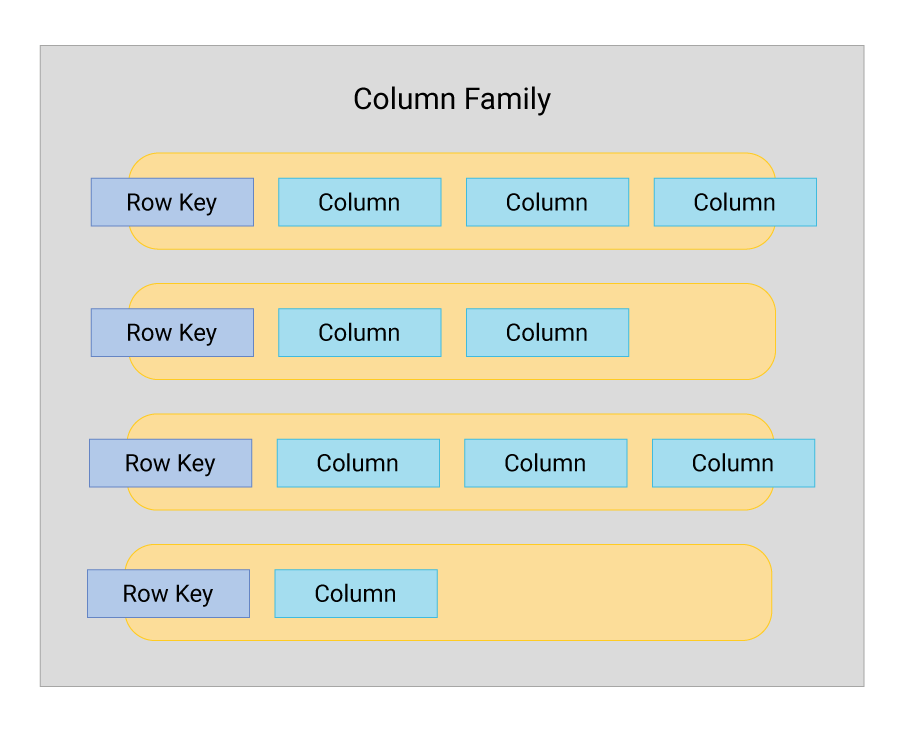
- Cassandra column families. Cassandra column families represent sorted data maps where column keys are mapped with their associated values. The partition key acts as the lookup value and is responsible for distributing data among nodes. When the primary key consists of a single column, a partition key and the primary key are the same.
A Cassandra column family consists of a collection of ordered columns in rows which represent a structured version of the stored data. The keyspace holds these Cassandra column families and each keyspace has at least one column family.
Columns are the basic data structure unit in Cassandra and they store three values: column or key name, timestamp, and value. The columns in rows can be removed or added at will, unlike the predefined Cassandra column families which cannot be changed.
Cassandra column family properties include:
- The SSTable sets forth a number of locations to keep column keys cached
- Some number of rows will have their content cached in memory
- The preload row cache allows the row cache to be pre-populated
- Row key uniquely identifies a column family row
- Row stores pairs of column values and column keys; column values store a single value or a collection of them, while column keys uniquely identify a column value in a row

Learn Cassandra data modeling stratgies from Discord’s Bo Ingram in this free on-demand masterclass
Cassandra Column Family Types
A column is the basic Cassandra data structure or the smallest increment of data in Cassandra. Each column in a Cassandra column family database has three main values: key or column name, value, and an uneditable time stamp that reflects when the column was updated.
Expiring columns are those given an expiration date in advance.
Super columns create another level of nesting more granular than the standard column family structure, grouping columns together logically based on business needs. A super column family structure stores a map of related sub-columns to optimize performance for columns likely to be queried together.
A static column family defines names and Cassandra column family data types. It is used to store values that are shared by all rows in the same partition. It is called a static column because the number of columns available is known.
In contrast, a dynamic column family does not define column names in advance, leaving Cassandra’s capability for storing data with arbitrary application and column names available.
Cassandra Column Family vs Table
There is no difference between column families and tables in Cassandra. In the older Thrift API, the name “column family” is used, while the newer CQL API uses the name “table.” However, this is only true for a Cassandra table vs column family because there are differences between a column family and a relational database table.
A Cassandra column family is not exactly equivalent to relational database tables for several reasons.
A Cassandra column family is schema-free, and since it doesn’t follow any schema, depending on your needs, you can add any column to any column family freely at any time. A Cassandra column family also has a comparator, whose value indicates how to order and sort columns when they are returned in a query.
Unlike RDBMS tables, it’s important to define and keep related columns together in the same family because Cassandra column families are each stored in separate files on disk. And finally, a Cassandra column family can be defined as a super column family or hold columns itself, while the user supplies the values for a relational table which defines only columns.
What Are the Goals of Cassandra Column Family Design?
Cassandra column family design is a key component of Cassandra data modeling.
Two primary goals for modeling the data structure are:
- Even data distribution: Data should be evenly spread across the cluster so that every node holds roughly the same amount of data. Cassandra determines which node should store the data based on hashing the partition key. Therefore, choosing a suitable partition key is crucial. More on this later on.
- To minimize the number of partitions accessed in a read query: To make reads faster, we’d ideally have all the data required in a read query stored in a single table. Although it’s fine to duplicate data across tables, in terms of performance, it’s better if the data needed for a read query is in one table.
Three top resources for learning more about how to design Cassandra column families include:
Wide Column Store NoSQL vs SQL Data Modeling video: NoSQL schemas are designed with very different goals in mind than SQL schemas. Where SQL normalizes data, NoSQL denormalizes. Where SQL joins ad-hoc, NoSQL pre-joins. And where SQL tries to push performance to the runtime, NoSQL bakes performance into the schema. Join us for an exploration of the core concepts of NoSQL schema design.
Data Modeling and Application Development training course: This is an intermediate level course that explains basic and advanced data modeling techniques including information on workflow application, query analysis, denormalization and other NoSQL data modeling topics. After completing this course, you will be able to perform workflow application and query analysis, explain commonly used data types, understand collections and UDTs, and understand denormalization.
Data Modeling Best Practices: Migrating SQL Schemas for Wide Column NoSQL: To maximize the benefits of wide column databases like Cassandra or ScyllaDB, you must adapt the structure of your data. Data modeling for wide column databases should be query-driven based on your access patterns– a very different approach than normalization for SQL tables. In this video, you will learn how tools can help you migrate your existing SQL structures to accelerate your digital transformation and application modernization.
How to Create a Column Family in Cassandra
In Cassandra, create a column family by using the CREATE TABLE command. Create table schema using cqlsh. Define the primary key. Name the table and specify the keyspace that contains its name. Refer to Apache Cassandra Documentation for more information.
Can You Create Cassandra Column Family in ScyllaDB?
ScyllaDB is a modern high-performance NoSQL wide column store database that is API-compatible with Apache Cassandra.
Cassandra was revolutionary when it first debuted in 2008, leading to its broad adoption. However, more than a decade later, many companies have recognized its underlying limitations and have now moved on. Leading companies such as Discord, Comcast, Fanatics, Expedia, Samsung, and Rakuten have replaced Cassandra with ScyllaDB. ScyllaDB delivers on the original vision of NoSQL — without the architectural downsides associated with Apache Cassandra (or the costs at volume of databases like Amazon DynamoDB). ScyllaDB is built with deep knowledge of the underlying Linux operating system and architectural advancements that enable consistently high performance at extreme scale.
Access white papers, benchmarks, and engineer perspectives on ScyllaDB vs Apache Cassandra.