




ScyllaDB Vector Search is now available. Learn about the design decisions, testing, and optimizations involved in achieving our performance goals.
December 18, 2025 Update: ScyllaDB Vector Search is now GA and production-ready
ScyllaDB Vector Search is now available. It brings millisecond-latency vector retrieval to massive scale. This makes ScyllaDB optimal for large-scale semantic search and retrieval-augmented generation workloads.
See the Quick Start Guide and give it try
Contact us with your questions, or for a personalized tour
In this blog post, we share a bit about what was involved in introducing low latency and high throughput Vector Search to ScyllaDB. We’ll cover the architectural design decisions behind our integration of ScyllaDB’s shard-per-core for real-time operations and high-performance ANN processing. Additionally, we’ll look at some unexpected performance challenges we encountered and how we addressed them.
If you’re really just looking for some early performance numbers, here you go: ScyllaDB Vector Search outperforms industry averages in both throughput and latency. Using public VectorDBBench datasets, it sustained up to 65K QPS (P99 < 20ms) on openai_small_50k, and 12K QPS (P99 < 40ms) on laion_large_100m. Across both configurations, tests demonstrate consistently high recall accuracy and predictable latencies, even under extreme concurrency.
Why Vector Search for ScyllaDB?
You might be wondering why we built Vector Search for ScyllaDB. Many vendors offer Vector Search, but we had some unique goals when we started our journey.
ScyllaDB’s architecture is recognized for its performance. Users have been relying on us for real-time ML, predictive analytics, fraud detection and other latency-sensitive AI workloads for years. A growing number of users mentioned they were working with third-party Vector Search databases, but found them overly complex (and costly) to manage at scale. So we committed to building integrated low-latency vector search for ScyllaDB scale.
We started with the question: How do we bring ScyllaDB’s low latencies and high throughput to something as complex as Vector Search? Most built-in vector solutions sacrifice performance for accuracy or scale. We wanted to deliver all three.
Vector Search Design Decisions and Architecture
Note: The topics in the remainder of this blog will be covered in more detail during P99 CONF, a free + virtual conference on all things performance. Join us live to learn more and ask questions.
Rather than embedding HNSW indexing directly into the core database, we decoupled vector indexing and similarity search into a dedicated Rust engine.
ScyllaDB replicas are paired with a local Vector Store node living under the same availability zone as the core ScyllaDB database.
ScyllaDB nodes store tables with vectors and other data. The Vector Store service builds internal indexes based on the data read from these tables. Vector Store retrieves data from ScyllaDB using its native CQL protocol and CDC functionality. The client performs a CQL query on ScyllaDB, then ScyllaDB requests the list of neighbors from the Vector Store index using HTTP.
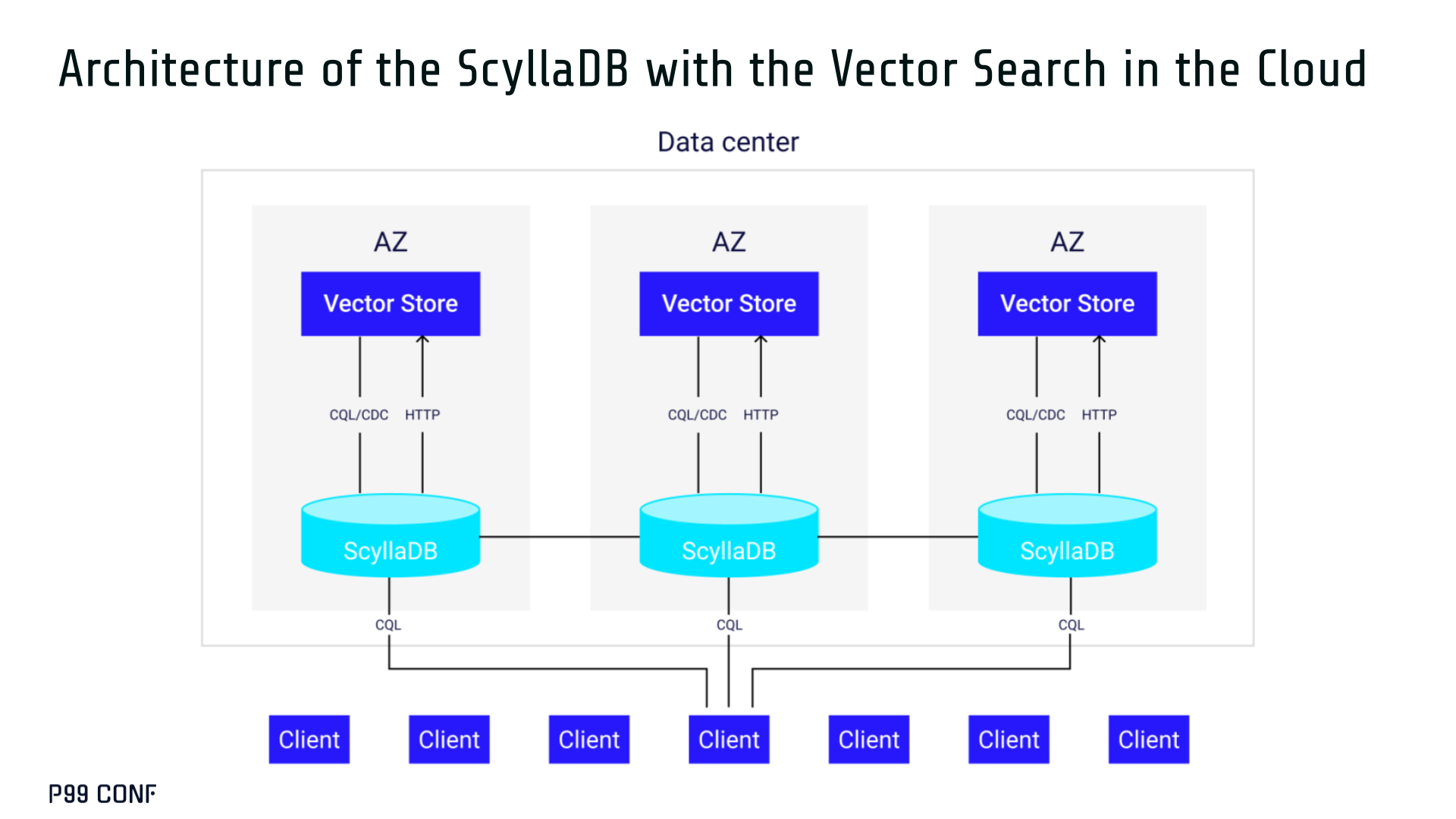
Why did we design it this way?
- It allows the database and Vector Store nodes to scale independently.
- Running each component on its own VM lets you fine-tune hardware types: SSTables live on storage-optimized nodes, while vectors benefit from RAM-optimized ones.
- Traffic remains zone-local, optimizing network transfer costs for intensive workloads.
- It isolates the performance of regular queries in contrast to ANN queries to optimize latency. This allows real-time ingestion to progress while updates get transparently replicated to the Vector Store for inferencing.
From the user’s perspective, clients simply issue ANN queries to ScyllaDB via the CQL API, and ScyllaDB transparently requests the list of neighbors from the Vector Store. The vector type is already supported by ScyllaDB’s Java, Rust, C++, Python, and C# drivers; it’s coming soon for GoCQL.
Vector Store Architecture
The core of our Vector Store is built on top of the USearch engine. We also use a set of Rust services to interface with ScyllaDB, build vector indexes, and provide search capabilities.
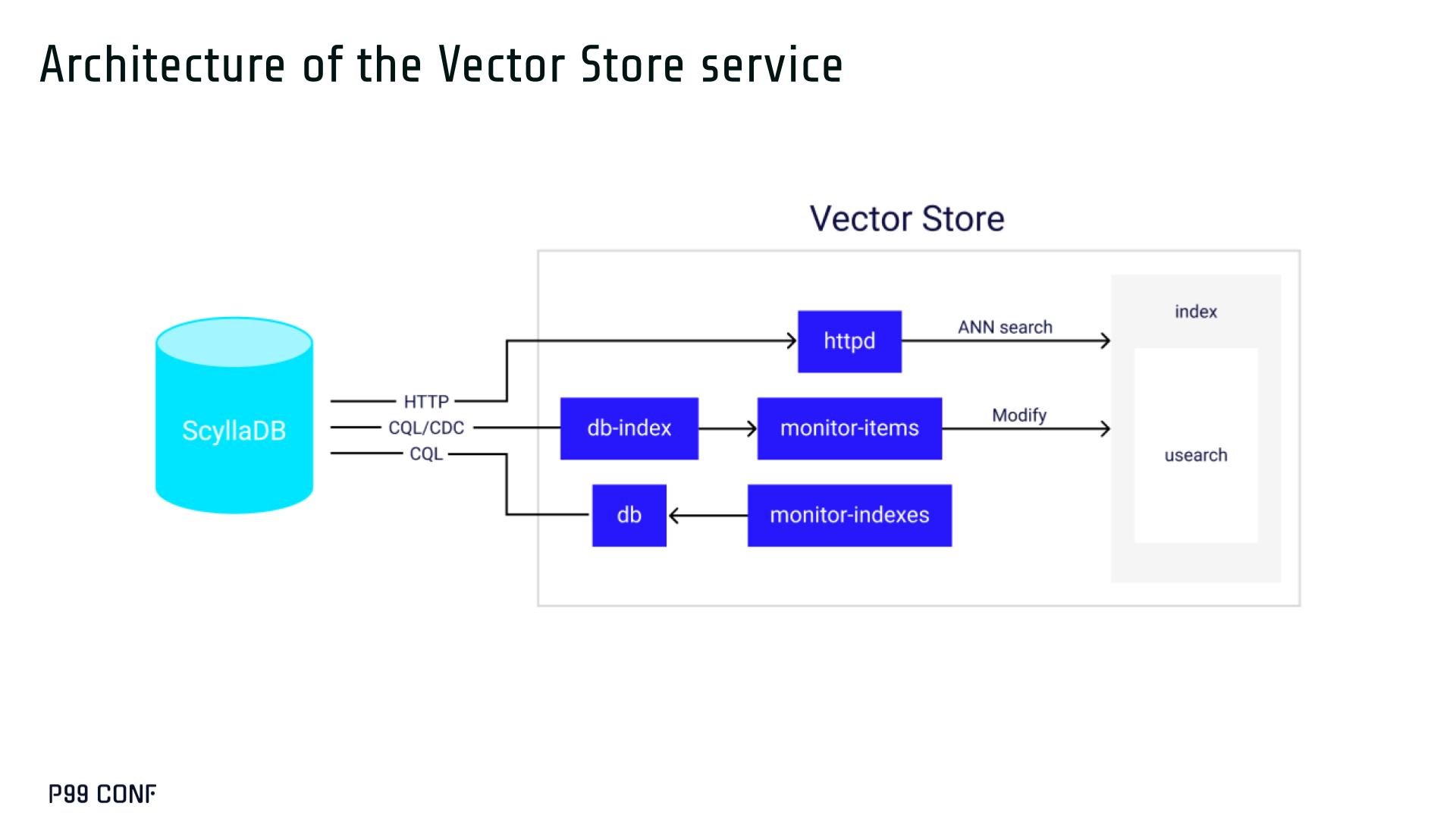
The Vector Store service is built based on the Actor Framework architecture, using Rust, Tokio, Axum, and USearch. Its functionality is divided into several actors:
- “httpd” serves as a REST API endpoint for executing ANN searches.
- “db” and “db-index” are responsible for communicating with ScyllaDB. Specifically, “db-index” is responsible for building an index upfront when created (via a full table scan), as well as consuming CDC streams and forwarding those results to “monitor-items” to update the underlying index.
- “db” retrieves schema information and handles metadata changes (like DROP’ing an index), therefore ensuring that the underlying Vector Store remains consistent with ScyllaDB.
Communication between actors is done using Tokio channels (queues) using async-await Rust features. There’s also a separate actor type for search functionality. It encapsulates all USearch computations and serves as a foundation for the entire service.
One important note about our current implementation: for optimal performance, the Vector Store keeps all indexes in memory. This means that the entire index needs to fit into a single node’s RAM. We’re exploring hybrid approaches for future iterations.
Building an Index
We extended ScyllaDB with a CUSTOM INDEX function, as well as a set of options that the Vector Store service uses to build the index.
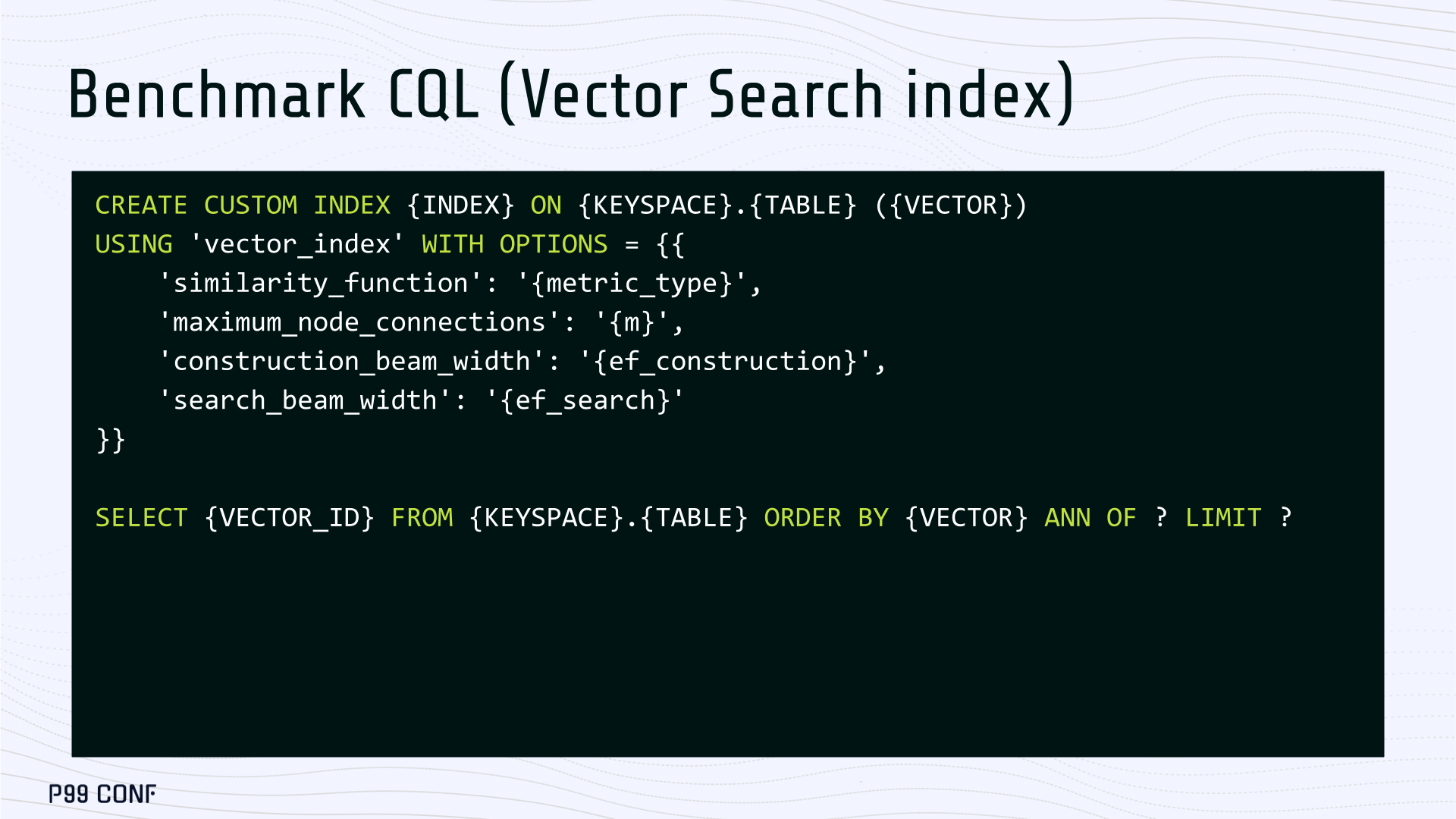
The Vector Store service will first perform a full table scan to build the initial index. After that, the Vector Store index is kept in sync with ScyllaDB via Change Data Capture (CDC). Each write appends an entry to ScyllaDB’s CDC log, which the Vector Store service eventually consumes to keep its corresponding index consistent.
A key design choice is that the Vector Store holds only the primary key and its corresponding vector embedding in memory. This greatly reduces the Vector Store memory requirements. When an ANN query runs (as shown above by the ANN OF syntax with a LIMIT clause), it will return just the list of primary keys back to the ScyllaDB caller. Those keys are then used by ScyllaDB internally to service the ResultSet back to the caller application.
Testing and Optimizing Performance
Update: Read our latest benchmark: 1B vectors with 2ms P99s and 250K QPS throughput
While building low-latency systems is no easy task, building low-latency Vector Stores is an even harder problem. Not surprisingly, we went through quite a few testing + optimization loops before reaching our latency targets for the Early Access program.
Our basic testing environment involved a single shared instance in AWS, where we manually pinned CPUs to each process via cgroups. Next, we loaded a small dataset using VectorDBBench and proceeded with testing performance using the same set of parameters through each run.
Even though we used a single instance, we decided to use a replication factor of 3 to simulate the load of a small Cloud cluster. Next, to define our embeddings, we used the ScyllaDB native vector type during table creation.

We built an index as described above. Then, we microbenchmarked both CQL ANN OF queries through ScyllaDB. We also benchmarked direct requests to the in-memory Vector Store. Once done, we compared QPS and P99 latency under increasing concurrency levels to identify bottlenecks in our integration layer.

Exploring the Latency Penalty of Nagle’s Algorithm
Our initial benchmarks against ScyllaDB produced an unexpected result. Even at very low concurrency, we observed latencies around 50ms.
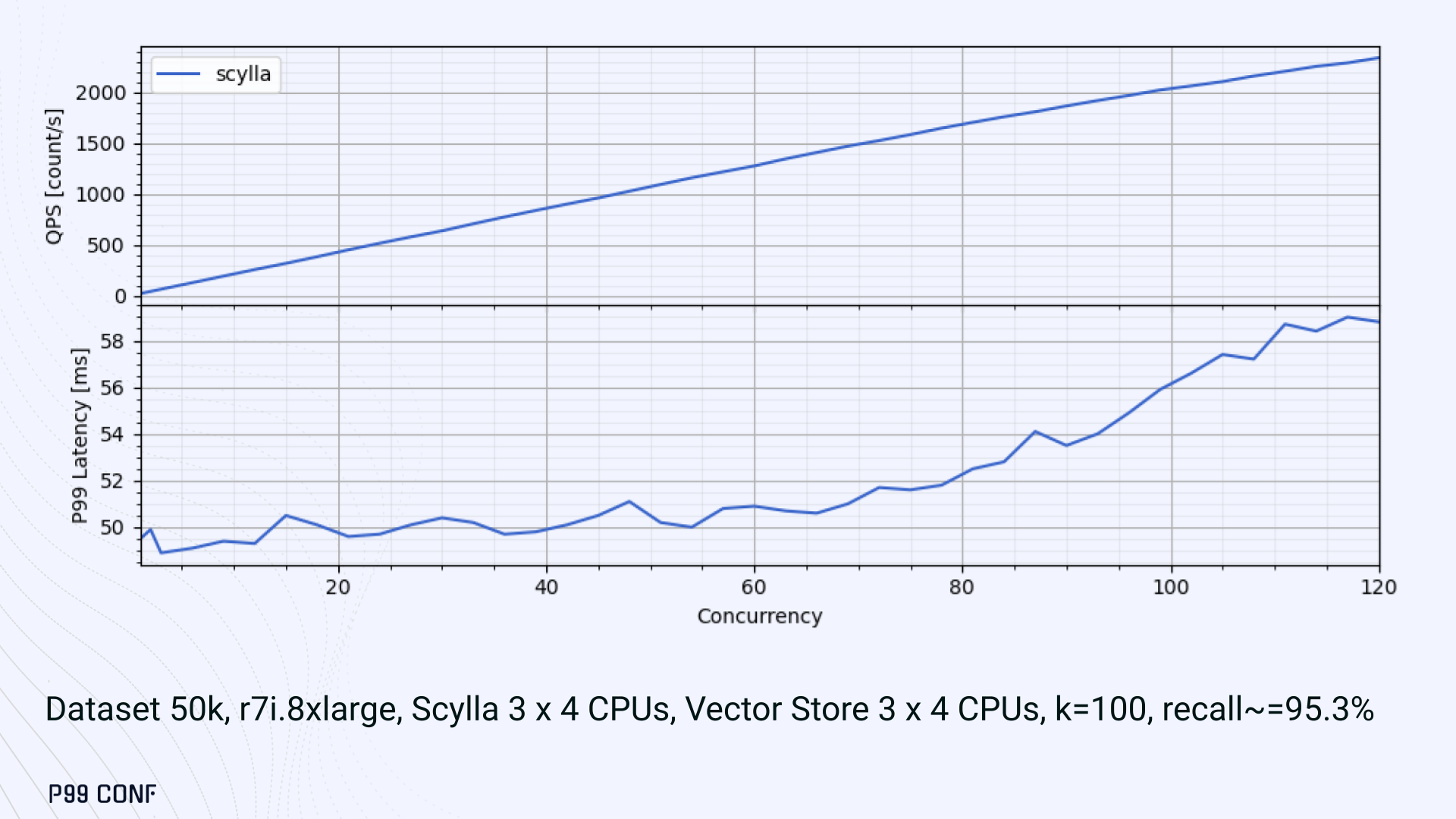
More interestingly, latency remained nearly constant as we increased concurrency, indicating that the system wasn’t struggling to handle additional load. The bottleneck had to be elsewhere.
When we compared ScyllaDB queries with requests sent directly to the Vector Store, the difference became clear. Vector Store queries returned in single-digit milliseconds and scaled smoothly until around 5K QPS. In contrast, ScyllaDB requests showed much higher P99 latency, which directly reduced throughput.
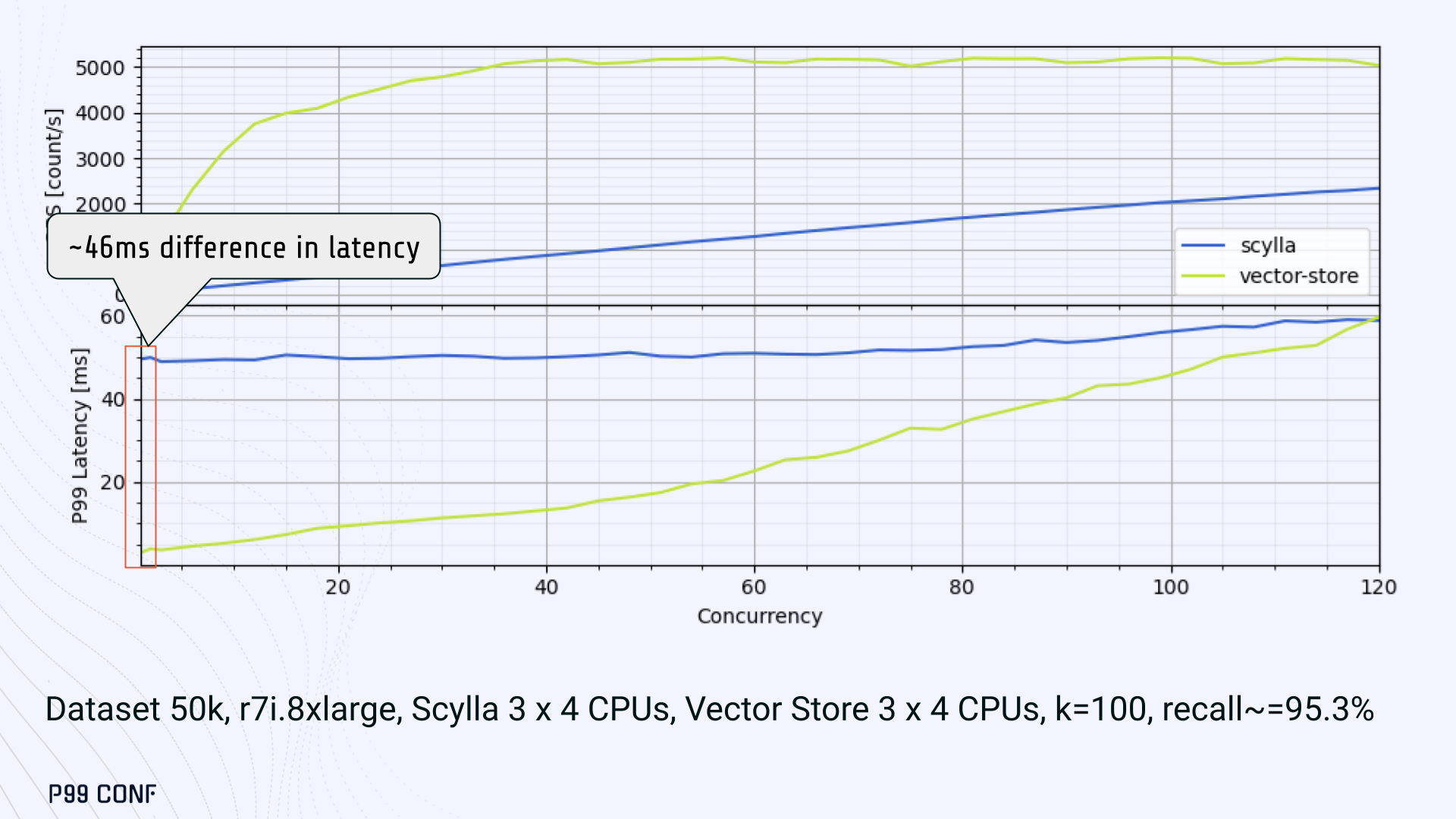
At low concurrency, the gap between the two paths was about 46ms: a clue that pointed to a networking issue. A network capture confirmed it. Linux’s TCP Delayed ACK can wait up to 40ms before sending acknowledgments.
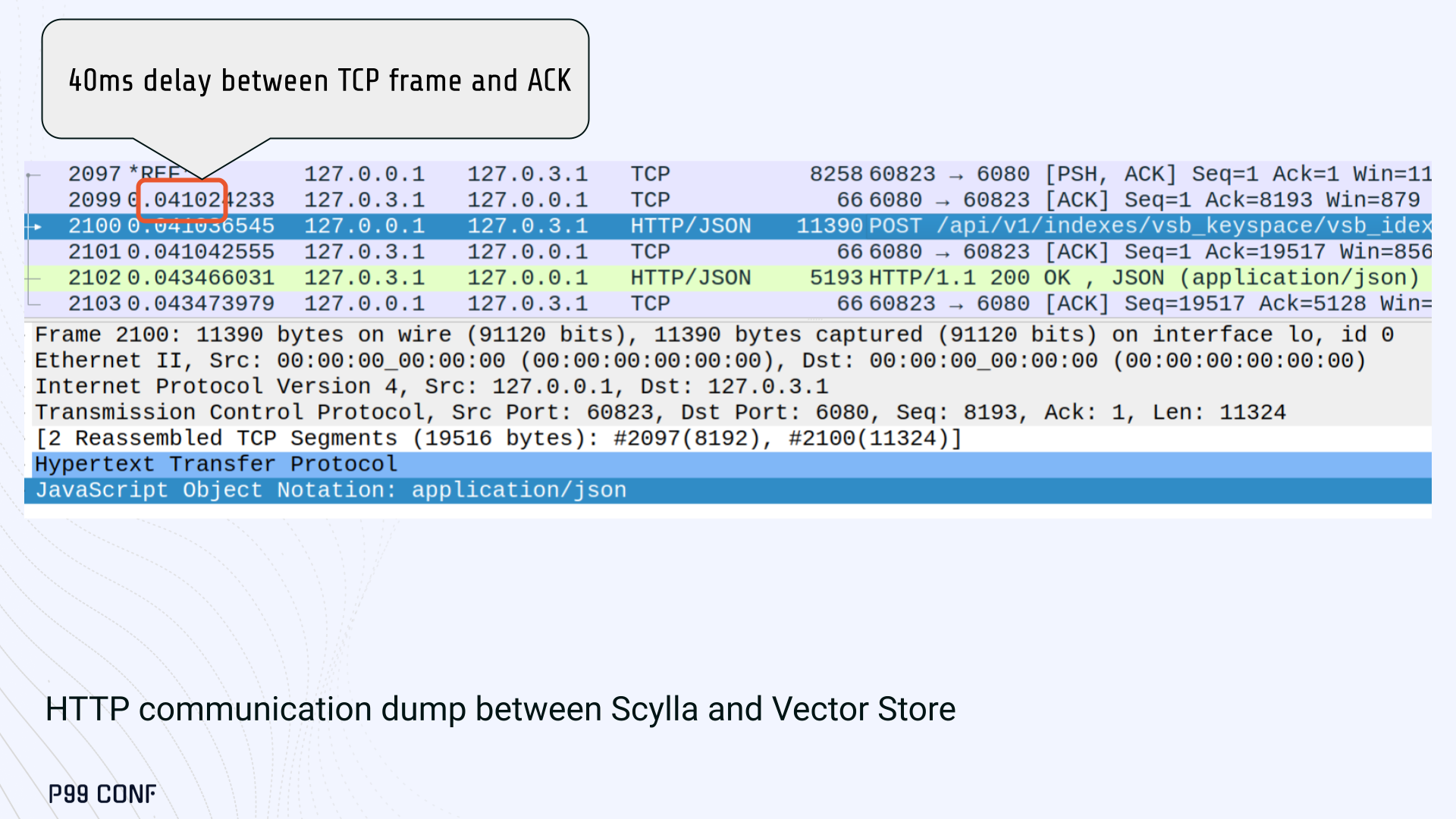
Combined with Nagle’s algorithm, which buffers small packets until an ACK arrives, this created a feedback loop that directly inflated ScyllaDB’s latencies. The fix was straightforward: disable Nagle’s algorithm with the TCP_NODELAY socket option. With Nagle disabled, ScyllaDB latencies dropped to nearly match those of direct Vector Store queries.
That said, throughput was still lower. While the Vector Store sustained ~5K QPS, ScyllaDB saturated around ~3K QPS. And that led to, of course, more testing and more optimization.
Experimenting with Thread Layouts
Our tests measuring performance across different thread layouts for our Vector Store service also yielded some interesting results.
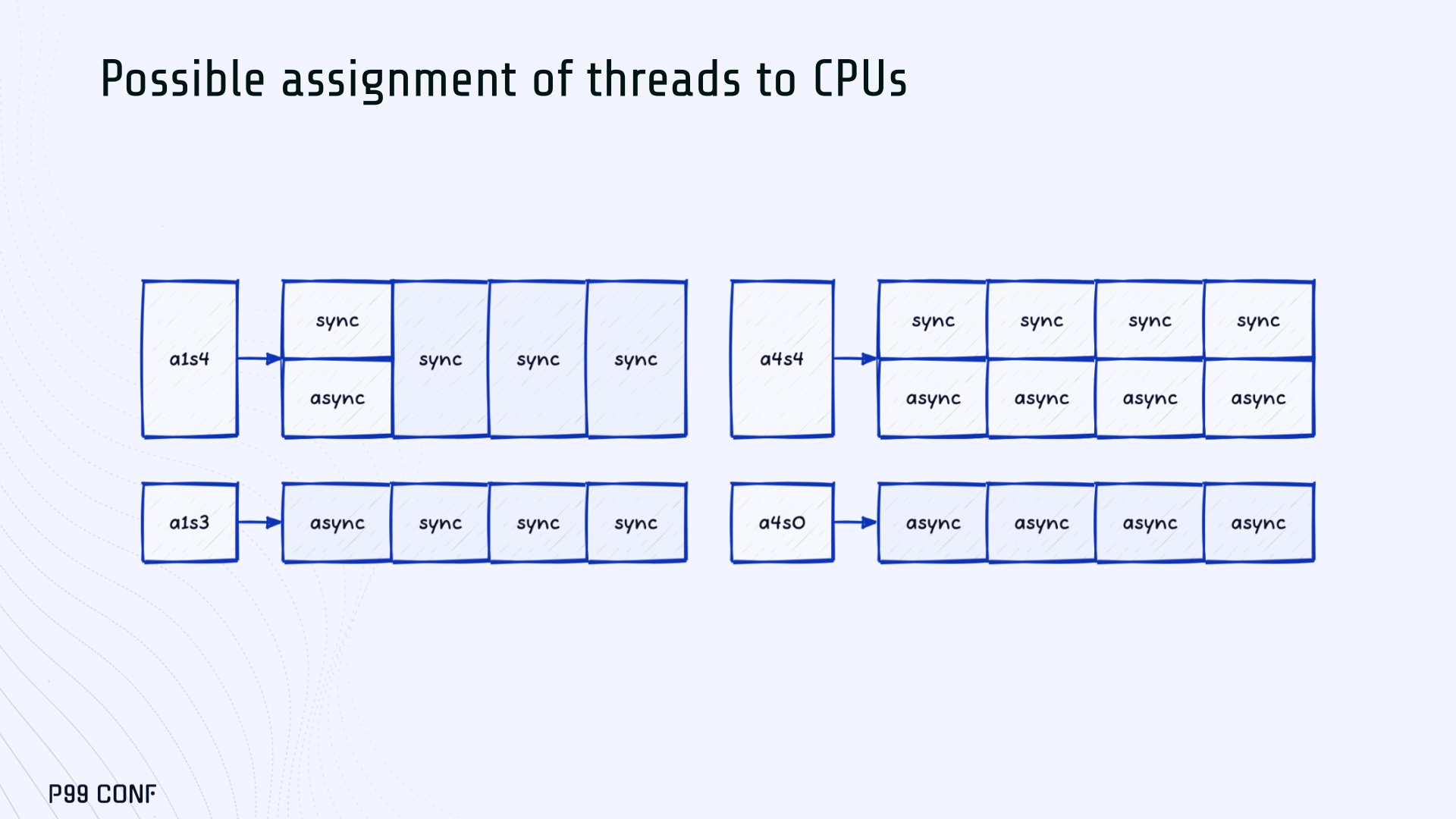
Each layout implements a different set of asynchronous and synchronous threads. Async threads are provided by the Rust Tokio runtime. They’re primarily used for I/O intensive computation, like networking and actor coordination. Synchronous threads used Rayon to execute CPU-intensive USearch tasks.
The image below shows the layouts we implemented. The letter ‘a’ denotes a thread for asynchronous (io-intensive) computation and ‘s’ indicates a thread for synchronous (cpu-intensive) computation. For example, a1s3, stands for one asynchronous thread with three synchronous threads.
The initial results below show that the layout using only asynchronous tasks provided the best QPS, at the expense of higher latency in high concurrency tests. The lowest latency was observed when threads weren’t fighting for CPU resources, with one asynchronous task and three synchronous threads. This layout, however, also provided the lowest QPS compared with all other tests.
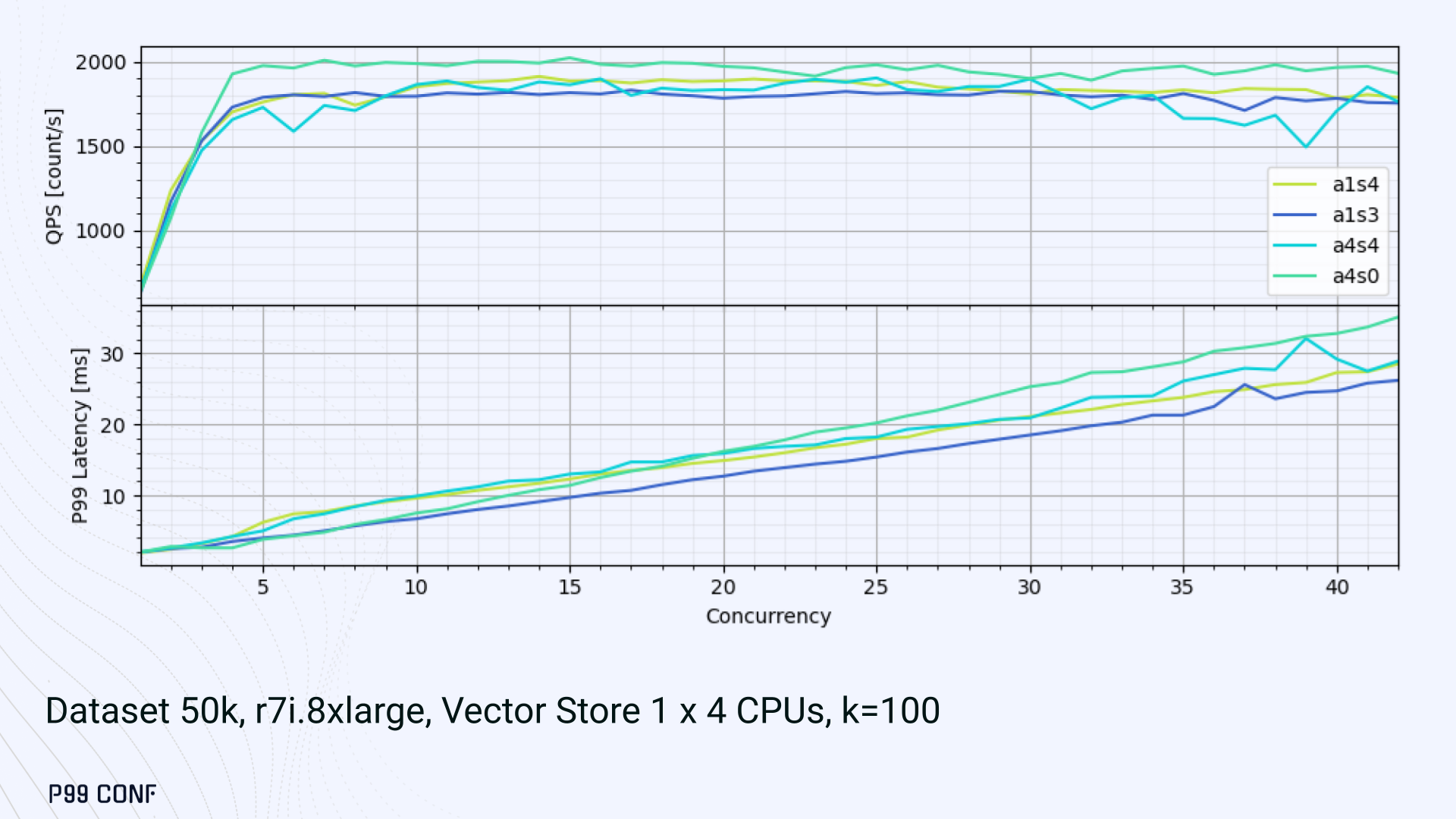
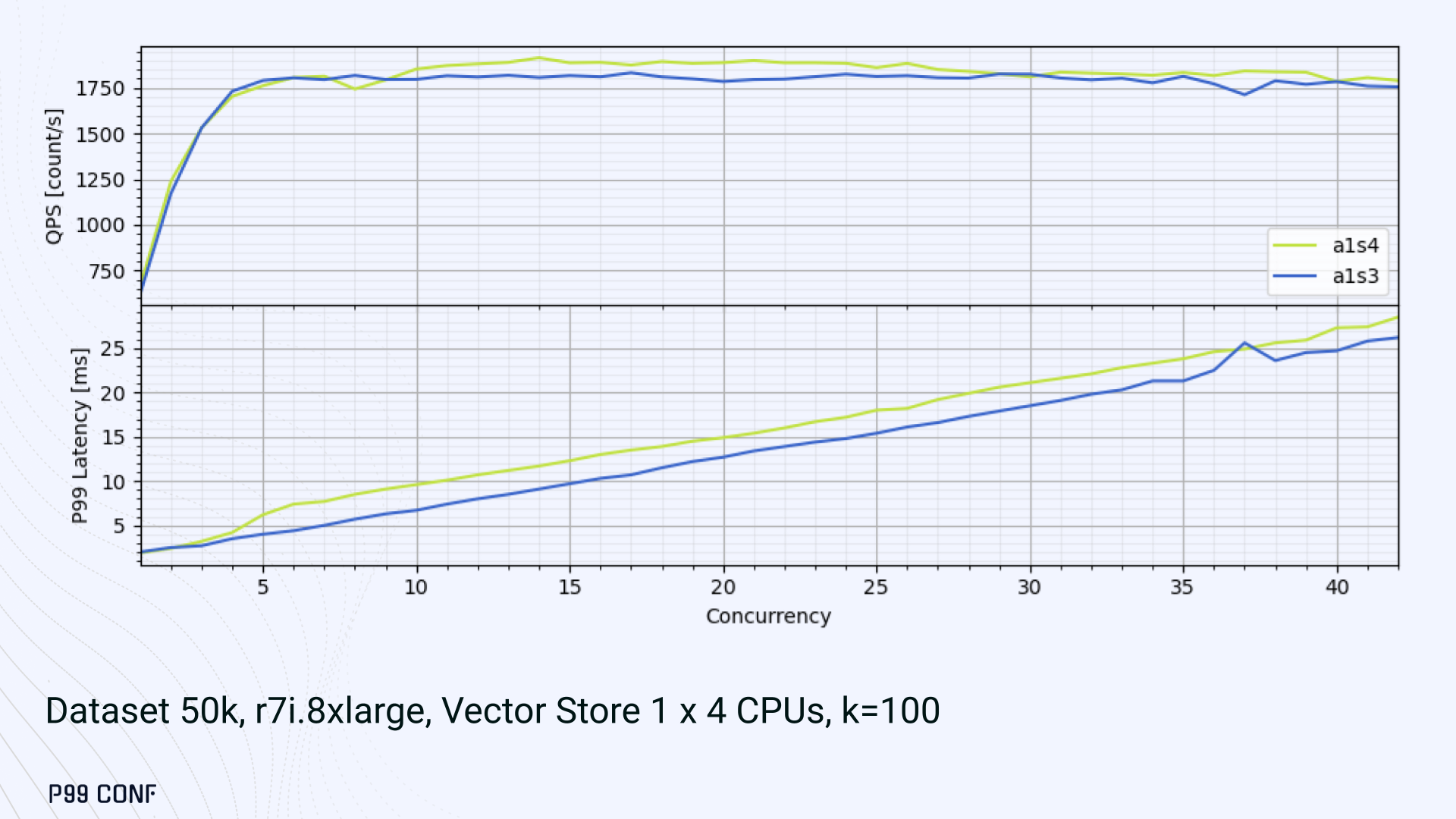
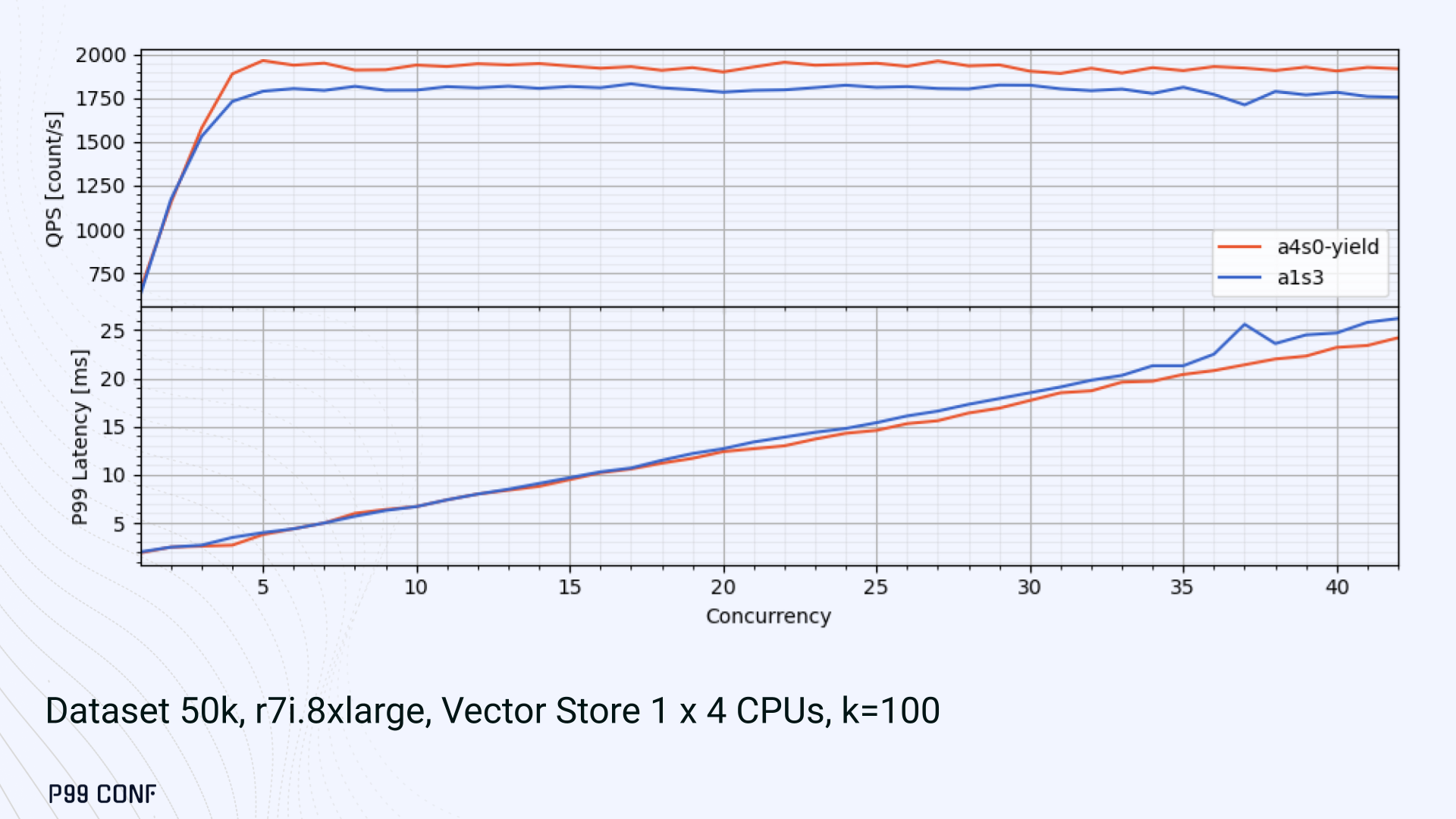
Looking at other variants (below), we can see that while oversubscribing CPUs (a1s4) does improve QPS to some extent, it comes at a significant latency cost. Dedicating one thread per CPU (a1s3) provided lower latency in contrast.
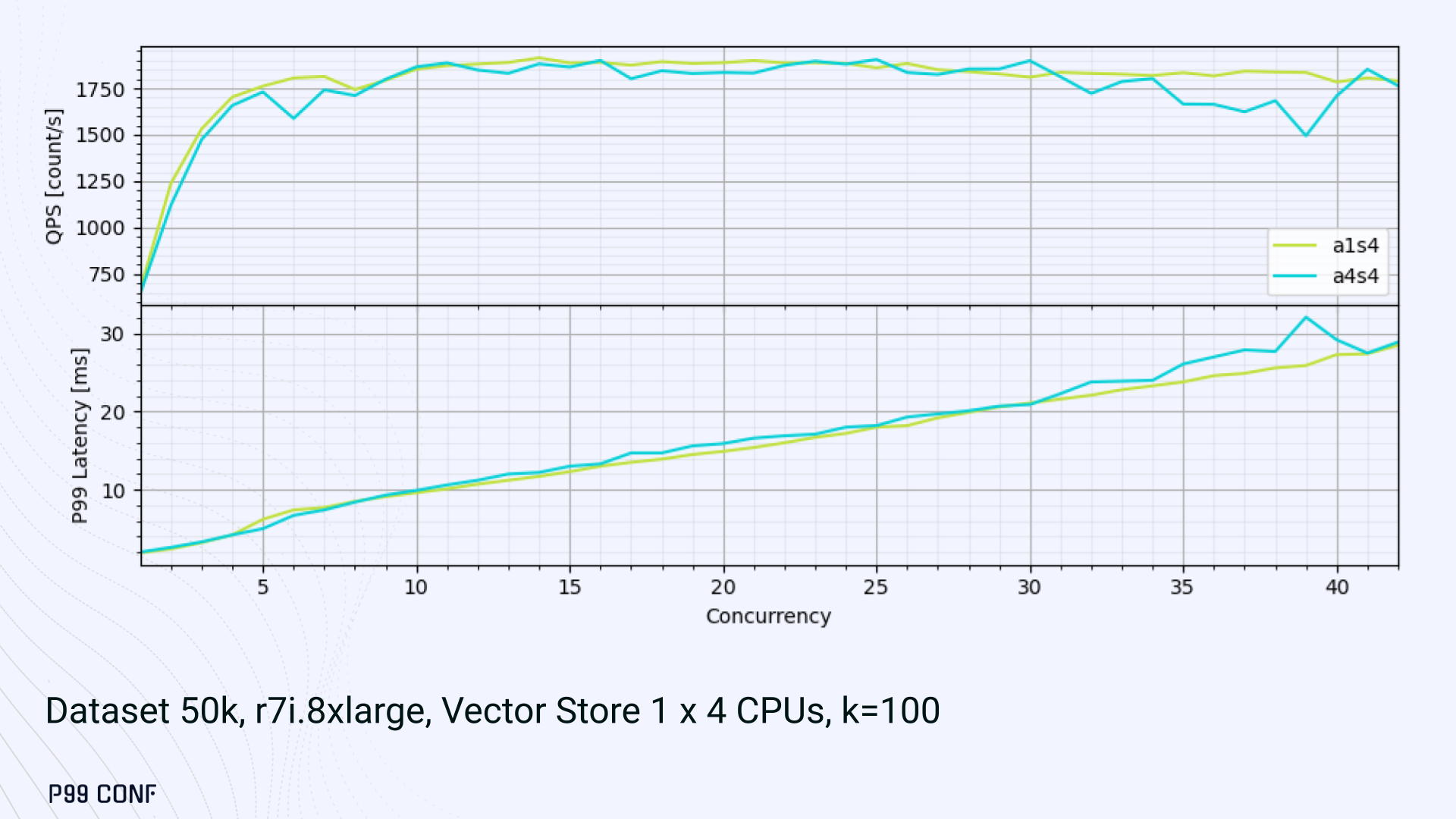
Similarly, oversubscribing a single CPU for asynchronous processing also performed better than oversubscribing all CPU cores for both async and synchronous work. See those results below.
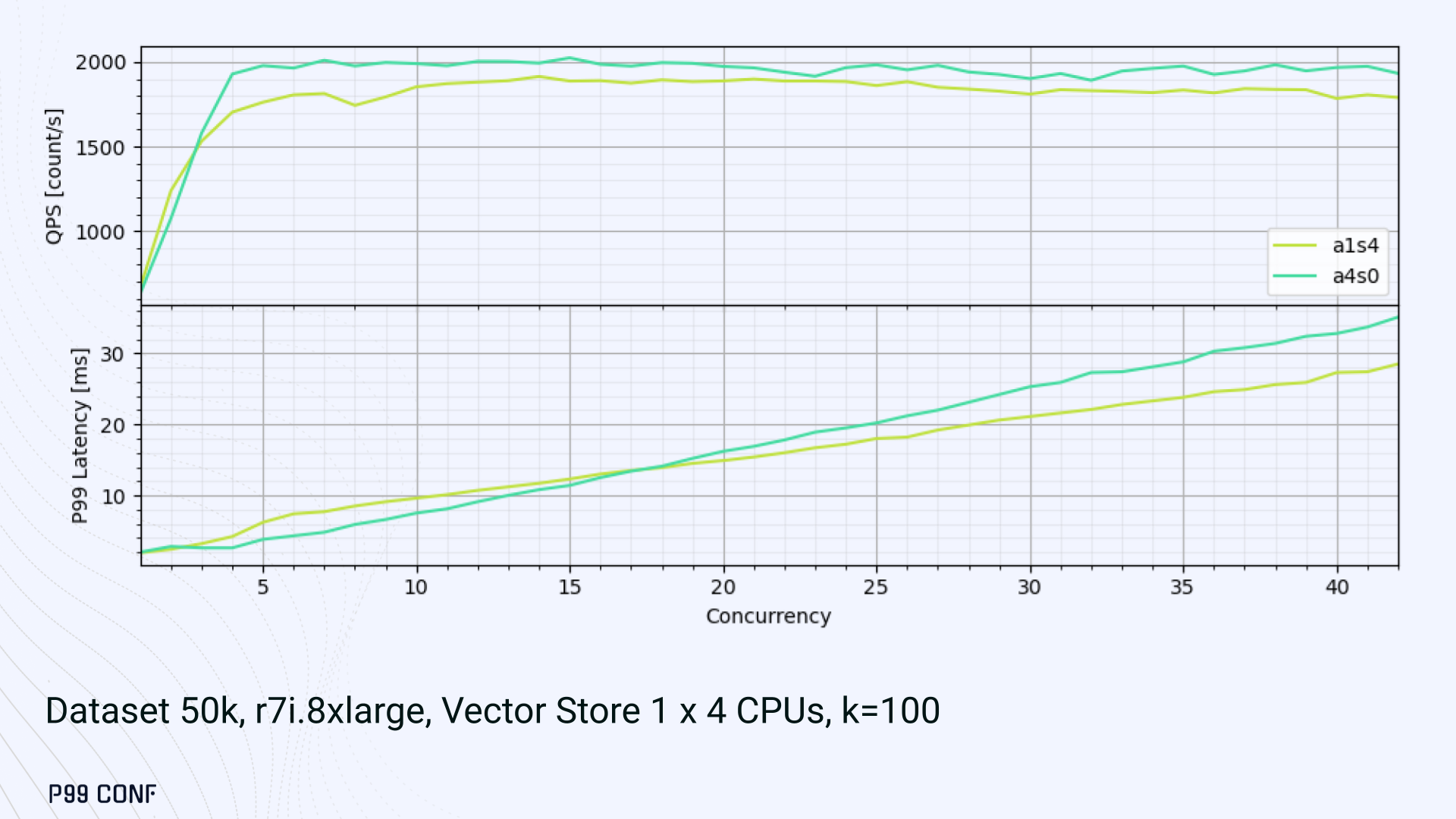
Therefore, the only optimization opportunity we found here was to reduce latency on the asynchronous-only variant. The chart below shows that its latency is lower than the oversubscribed one, but grows at a faster pace under higher concurrency.
So in summary, we found that:
- Async only (a4s0) delivered the best QPS, but latencies rose sharply at higher concurrency.
- Mixed (a1s3) avoided CPU contention, yielding the lowest latencies (but also the lowest QPS).
- Oversubscribed setups (a1s4, a4s4) gained some throughput (but at the cost of latency).
The key takeaway is that adding sync threads improved latency at the cost of throughput, while async-only favored throughput but suffered under load.
More Latency Optimizations
A closer look at CPU traces revealed why. Each ANN request runs a burst of USearch computation.

However, under concurrency, tasks preempt one another. This delays completions and hurts P99 latency.
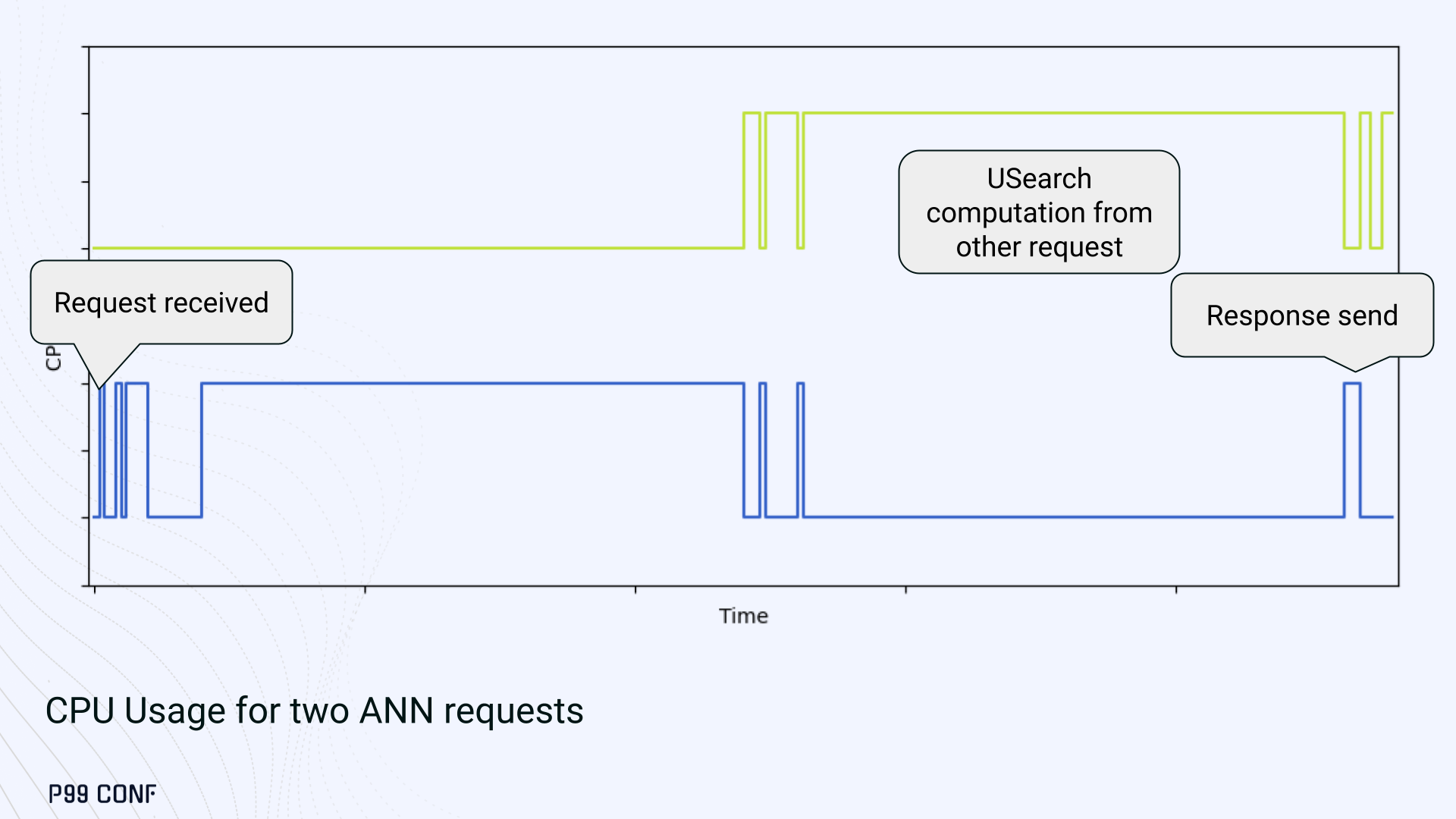
Tokio doesn’t offer task prioritization, but we implemented a neat trick: inserting a yield_now before starting USearch computation. This moved new tasks to the back of the queue, giving in-flight requests a chance to finish first.

Comparing both approaches side by side (below) shows that our one-line code change provides marginally worse throughput, but big latency wins.
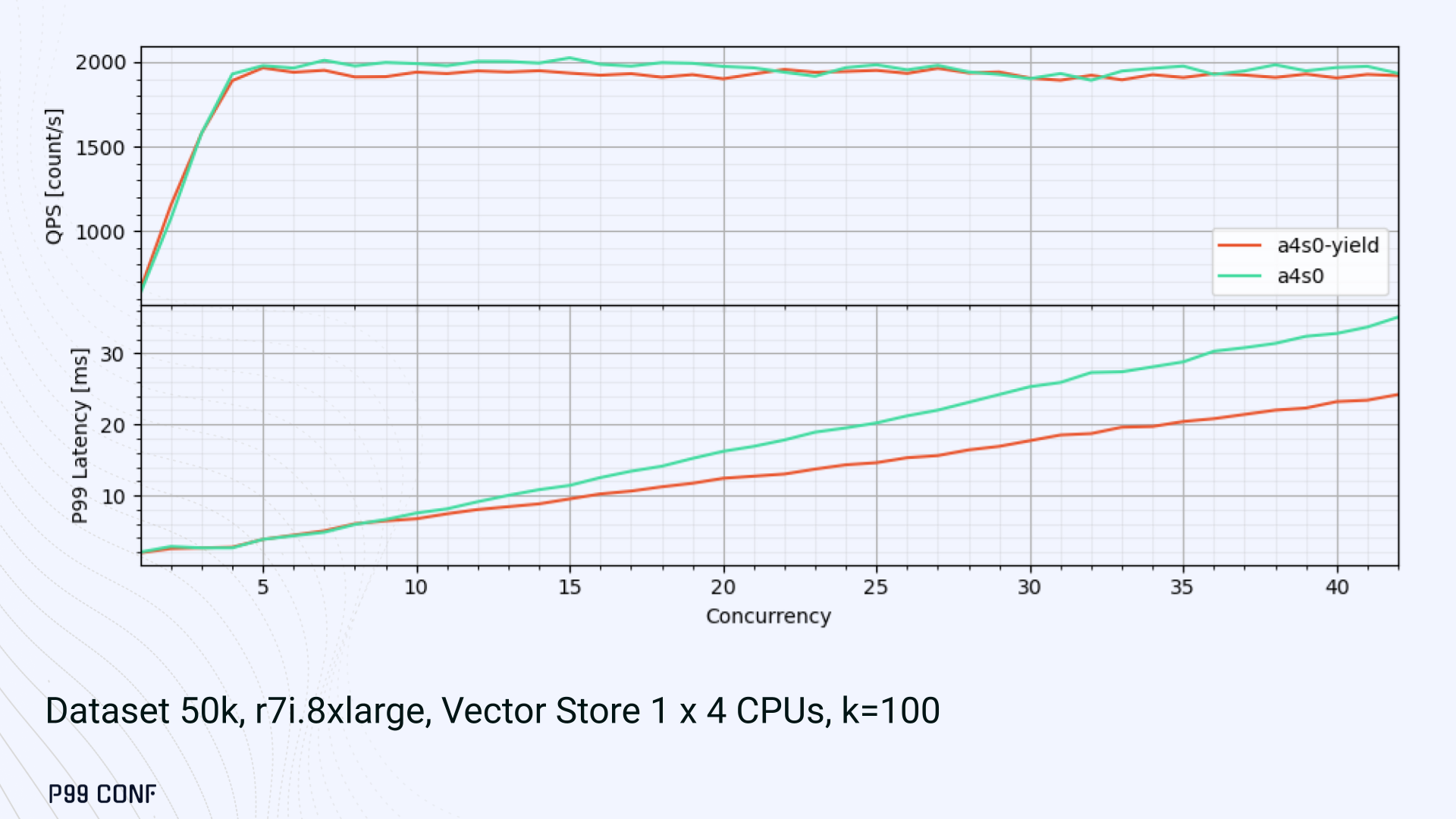
As you can see below, the asynchronous-only, yield layout also drives even lower latency than the previous oversubscribed setup.
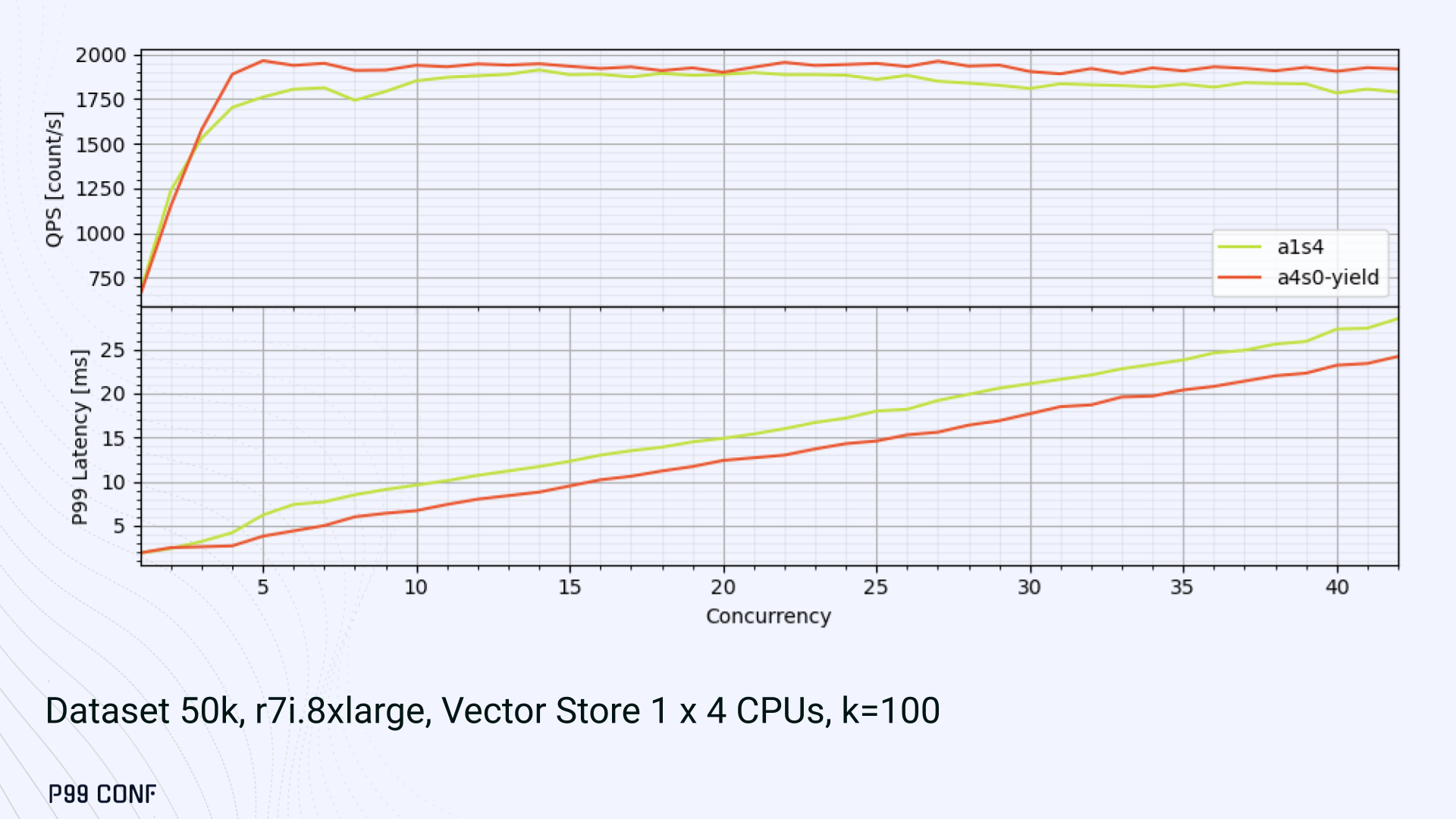
Moreover, the graph below shows that it still drives higher QPS and now lower latencies than the mixed non-oversubscribed layout. It’s quite fascinating what a single line of code can do these days…
Scaling with ScyllaDB Cloud
Finally, we turned to ScyllaDB Cloud environments to test scaling.
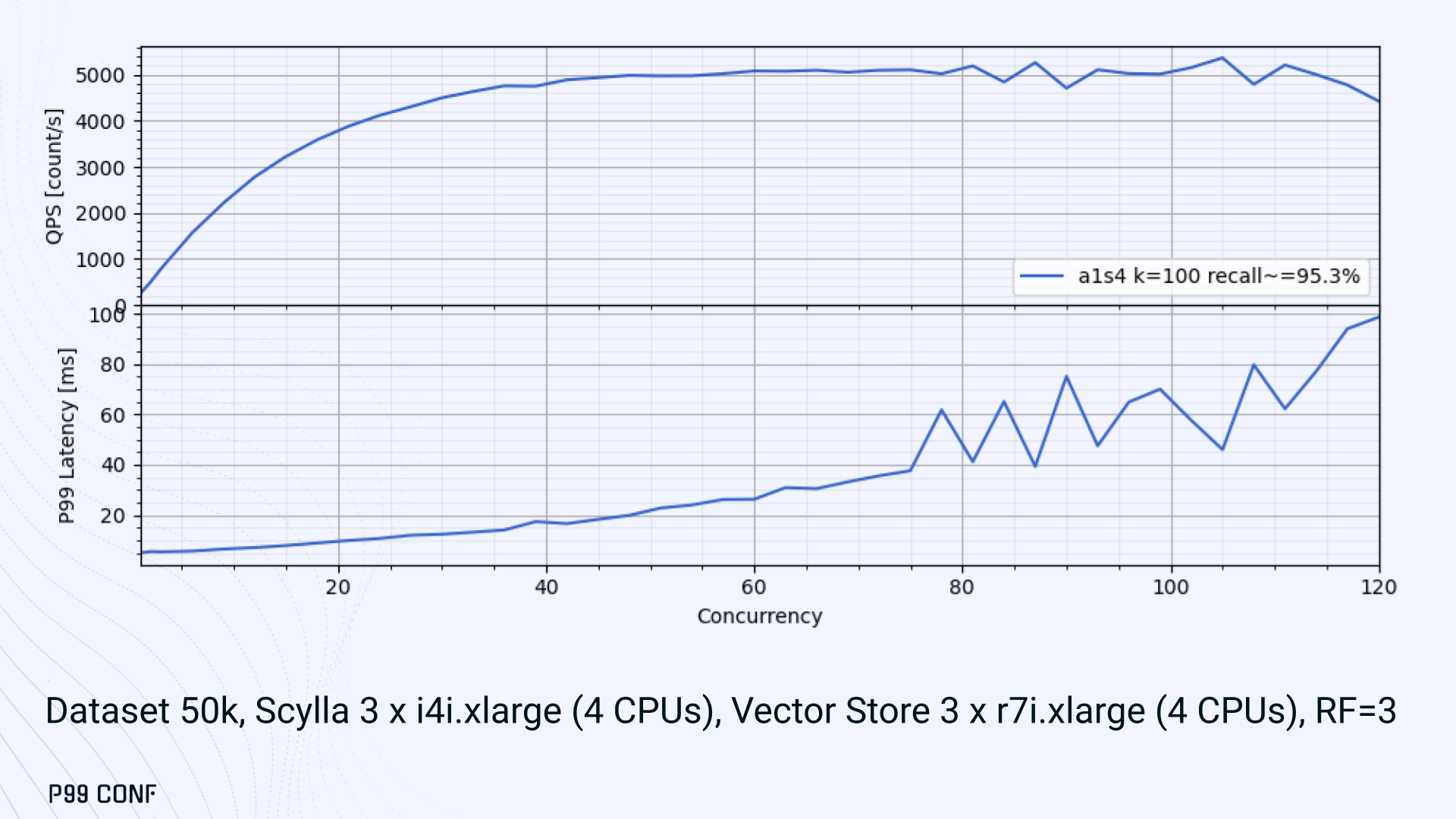
On the R7i.xlarge, we started by replicating the same tests that we ran in our previous single-node setup. Here, each ANN query retrieves the 100 most similar neighbors. This is quite a compute-intensive operation, often used for re-ranking scenarios. We achieved the same 5K QPS with single-digit millisecond latencies under moderate concurrency, while we approached the saturation point somewhere close to a concurrency of 80.
Using R7i.8xlarge instances, we scaled our setup by 4X: going from 4 vCPUs to 16 vCPUs per node. Here, we ran two series of tests.
- For the 100 most similar neighbors, throughput saturates between 13 to 14K QPS while latency remains below 5ms under low concurrency, up to 20ms under a concurrency of 100.
- For the 10 most similar neighbors, throughput saturates at 20K QPS, with single-digit millisecond latencies even under a concurrency of 100.
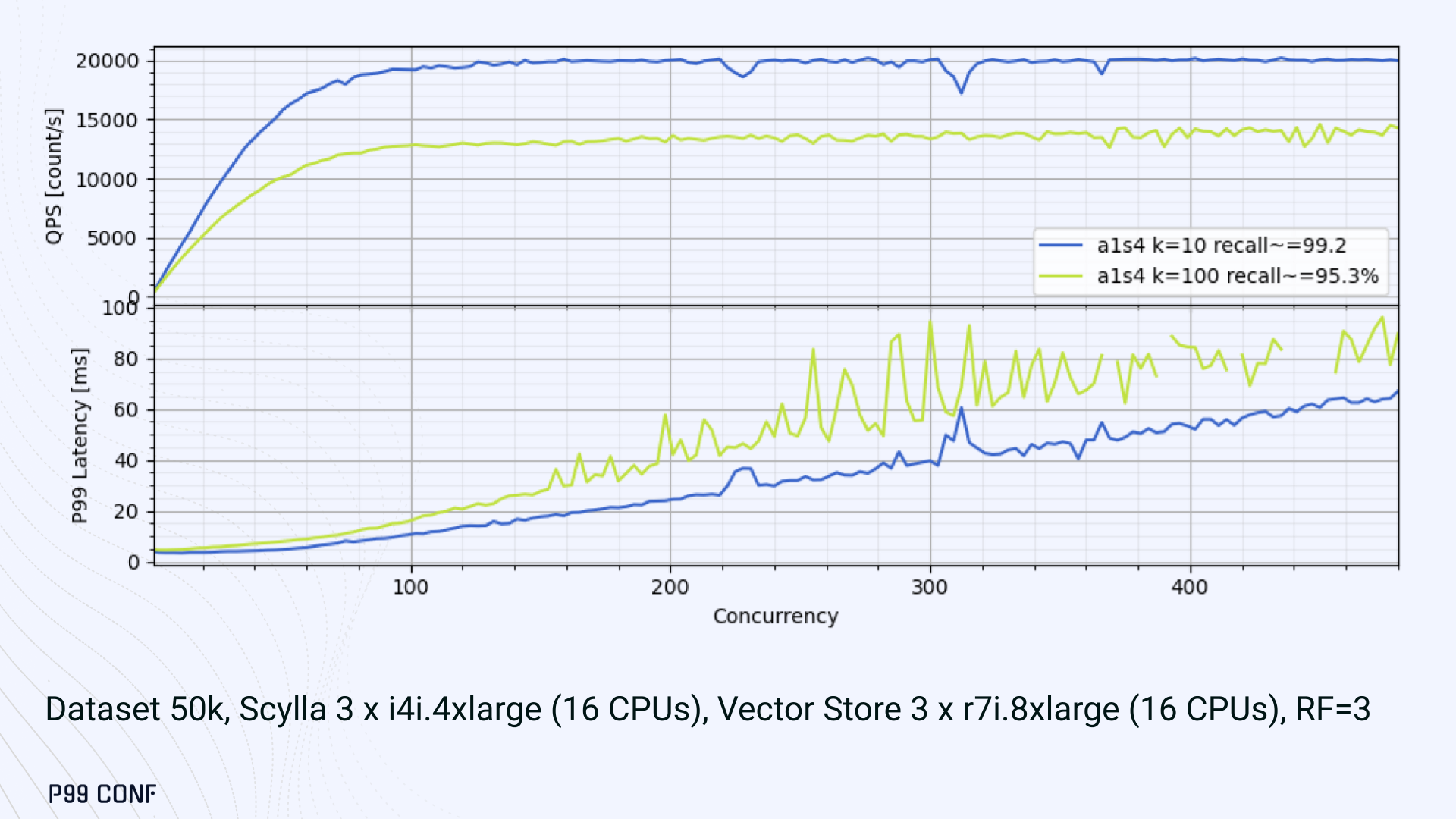
Large-Scale Performance Test
Our final test involved scaling the Vector Store nodes to 64 CPUs per node. Our goal here was to get enough memory to run a larger dataset with 100M embeddings at 768 dimensions.
This scale is rarely published by other vector search providers, and it still leaves plenty of headroom for even larger datasets.
With 100M embeddings, we reached 12K QPS with P99 latency ranging between 20ms at low concurrency to 40ms at 200 concurrency, while maintaining over 97% recall.
For comparison, the smaller dataset reached around 65K QPS for k=10 while keeping latencies steadily low even under extreme concurrency.
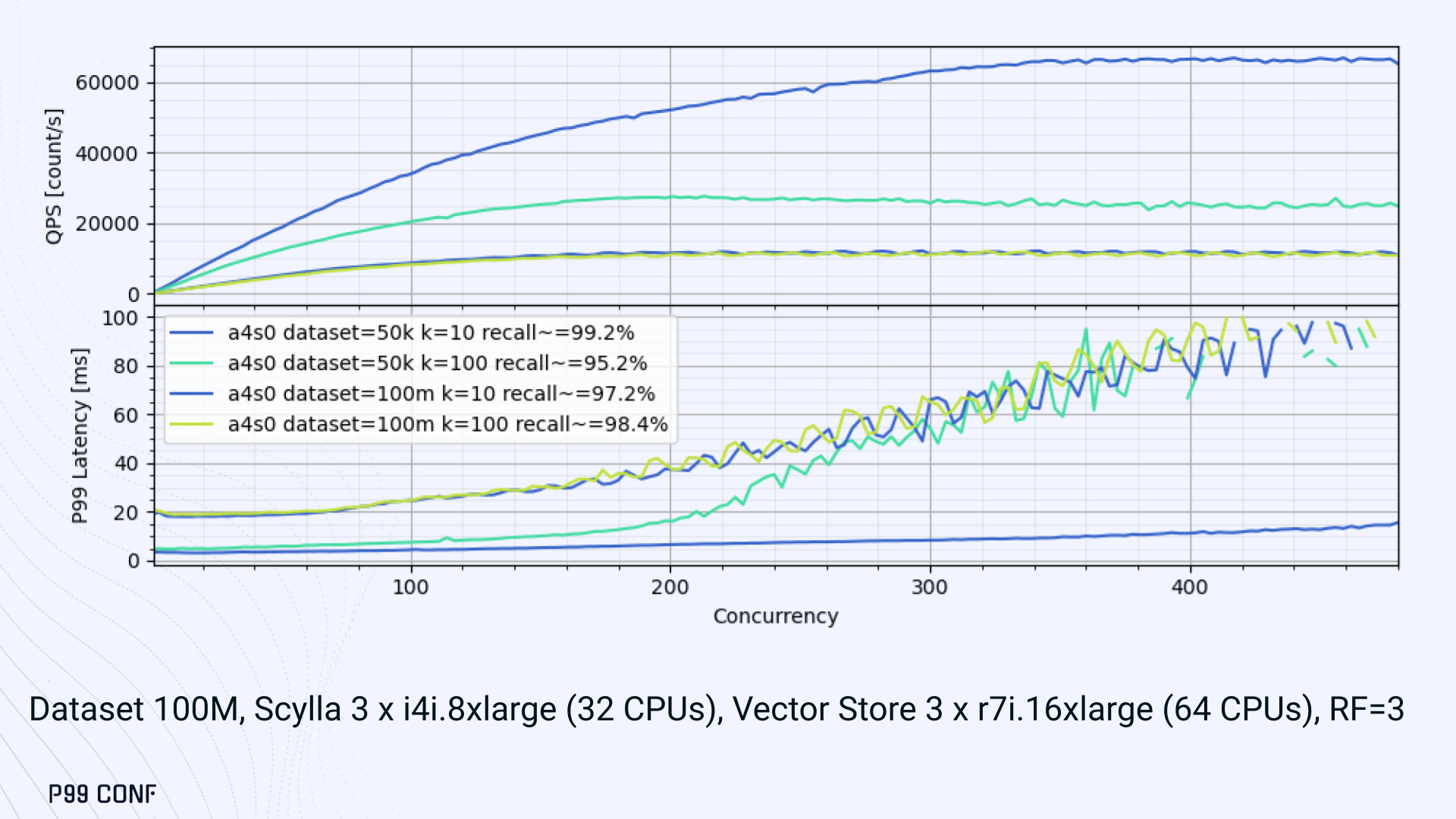
Of course, your mileage may vary. Our tests ran on static datasets, and real-world workloads may behave differently. Still, the trajectory is promising, and we’re continuing to push towards linear scaling.
Next Steps
ScyllaDB Vector Search was built for users with real-time workload needs; our architecture isolates similarity function computation from the database and abstracts complexity for the user. This blog has outlined some of the design decisions, testing, and optimization involved in achieving those performance goals.
We’re excited about the results of these early performance tests, and we hope you are too. We’re eager to hear our community’s feedback. Give a try, share your feedback, and help shape the future of this product.



