Explore the tradeoffs of different Linux I/O methods and learn how databases can take advantage of a modern SSD’s unique characteristics
The following blog is an excerpt from Chapter 3 of the Database Performance at Scale book, which is available for free. This book sheds light on often overlooked factors that impact database performance at scale.
Unless the database engine is an in-memory one, it will have to keep the data on external storage. There can be many options to do that, including local disks, network-attached storage, distributed file- and object- storage systems, etc. The term “I/O” typically refers to accessing data on local storage – disks or file systems (that, in turn, are located on disks as well). And in general, there are four choices for accessing files on a Linux server: read/write, mmap, direct I/O (DIO) read/write, and asynchronous I/O (AIO/DIO, because this I/O is rarely used in cached mode).
Traditional read/write
The traditional method is to use the read(2) and write(2) system calls. In a modern implementation, the read system call (or one of its many variants – pread, readv, preadv, etc) asks the kernel to read a section of a file and copy the data into the calling process address space. If all of the requested data is in the page cache, the kernel will copy it and return immediately; otherwise, it will arrange for the disk to read the requested data into the page cache, block the calling thread, and when the data is available, it will resume the thread and copy the data. A write, on the other hand, will usually just copy the data into the page cache; the kernel will write-back the page cache to disk some time afterward.
mmap
An alternative and more modern method is to memory-map the file into the application address space using the mmap(2) system call. This causes a section of the address space to refer directly to the page cache pages that contain the file’s data. After this preparatory step, the application can access file data using the processor’s memory read and memory write instructions. If the requested data happens to be in cache, the kernel is completely bypassed and the read (or write) is performed at memory speed. If a cache miss occurs, then a page-fault happens and the kernel puts the active thread to sleep while it goes off to read the data for that page. When the data is finally available, the memory-management unit is programmed so the newly read data is accessible to the thread which is then awoken.
Direct I/O (DIO)
Both traditional read/write and mmap involve the kernel page cache and defer the scheduling of I/O to the kernel. When the application wishes to schedule I/O itself (for reasons that we will explain later), it can use direct I/O, shown in Figure 3-4. This involves opening the file with the O_DIRECT flag; further activity will use the normal read and write family of system calls. However, their behavior is now altered: instead of accessing the cache, the disk is accessed directly, which means that the calling thread will be put to sleep unconditionally. Furthermore, the disk controller will copy the data directly to userspace, bypassing the kernel.

Figure 3-4: Direct IO involves opening the file with the O_DIRECT flag; further activity will use the normal read and write family of system calls, but their behavior is now altered
Asynchronous I/O (AIO/DIO)
A refinement of direct I/O, asynchronous direct I/O behaves similarly but prevents the calling thread from blocking (see Figure 3-5). Instead, the application thread schedules direct I/O operations using the io_submit(2) system call, but the thread is not blocked; the I/O operation runs in parallel with normal thread execution. A separate system call, io_getevents(2), is used to wait for and collect the results of completed I/O operations. Like DIO, the kernel’s page cache is bypassed, and the disk controller is responsible for copying the data directly to userspace.
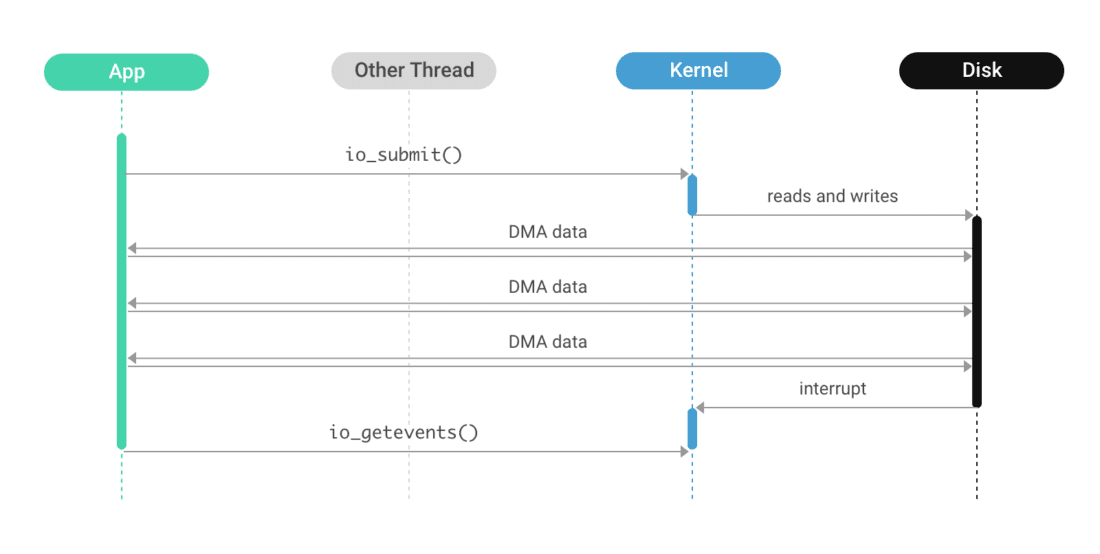
Figure 3-5: A refinement of direct I/O, asynchronous direct I/O behaves similarly but prevents the calling thread from blocking
Note: io_uring
The API to perform asynchronous I/O appeared in Linux long ago, and it was warmly met by the community. However, as it often happens, real-world usage quickly revealed many inefficiencies such as blocking under some circumstances (despite the name), the need to call the kernel too often, and poor support for canceling the submitted requests. Eventually, it became clear that the updated requirements are not compatible with the existing API and the need for a new one arose.
This is how the io_uring() API appeared. It provides the same facilities as what AIO does, but in a much more convenient and performant way (also it has notably better documentation). Without diving into implementation details, let’s just say that it exists and is preferred over the legacy AIO.
Understanding the tradeoffs
The different access methods share some characteristics and differ in others. Table 3-1 summarizes these characteristics, which are elaborated on below.
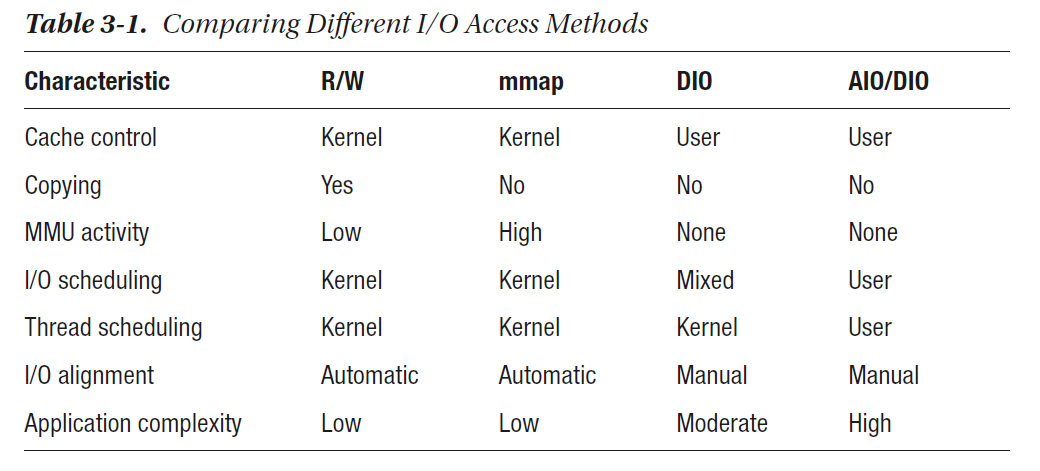
Copying and MMU activity
One of the benefits of the mmap method is that if the data is in cache, then the kernel is bypassed completely. The kernel does not need to copy data from the kernel to userspace and back, so fewer processor cycles are spent on that activity. This benefits workloads that are mostly in cache (for example, if the ratio of storage size to RAM size is close to 1:1).
The downside of mmap, however, occurs when data is not in the cache. This usually happens when the ratio of storage size to RAM size is significantly higher than 1:1. Every page that is brought into the cache causes another page to be evicted. Those pages have to be inserted into and removed from the page tables; the kernel has to scan the page tables to isolate inactive pages, making them candidates for eviction, and so forth. In addition, mmap requires memory for the page tables. On x86 processors, this requires 0.2% of the size of the mapped files. This seems low, but if the application has a 100:1 ratio of storage to memory, the result is that 20% of memory (0.2% * 100) is devoted to page tables.
I/O scheduling
One of the problems with letting the kernel control caching (with the mmap and read/write access methods) is that the application loses control of I/O scheduling. The kernel picks whichever block of data it deems appropriate and schedules it for write or read. This can result in the following problems:
- A write storm. When the kernel schedules large amounts of writes, the disk will be busy for a long while and impact read latency
- The kernel cannot distinguish between “important” and “unimportant” I/O. I/O belonging to background tasks can overwhelm foreground tasks, impacting their latency
By bypassing the kernel page cache, the application takes on the burden of scheduling I/O. This doesn’t mean that the problems are solved, but it does mean that the problems can be solved – with sufficient attention and effort.
When using Direct I/O, each thread controls when to issue I/O However, the kernel controls when the thread runs, so responsibility for issuing I/O is shared between the kernel and the application. With AIO/DIO, the application is in full control of when I/O is issued.
Thread scheduling
An I/O intensive application using mmap or read/write cannot guess what its cache hit rate will be. Therefore it has to run a large number of threads (significantly larger than the core count of the machine it is running on). Using too few threads, they may all be waiting for the disk leaving the processor underutilized. Since each thread usually has at most one disk I/O outstanding, the number of running threads must be around the concurrency of the storage subsystem multiplied by some small factor in order to keep the disk fully occupied. However, if the cache hit rate is sufficiently high, then these large numbers of threads will contend with each other for the limited number of cores.
When using Direct I/O, this problem is somewhat mitigated. The application knows exactly when a thread is blocked on I/O and when it can run, so the application can adjust the number of running threads according to runtime conditions.
With AIO/DIO, the application has full control over both running threads and waiting I/O (the two are completely divorced), so it can easily adjust to in-memory or disk-bound conditions or anything in between.
I/O alignment
Storage devices have a block size; all I/O must be performed in multiples of this block size which is typically 512 or 4096 bytes. Using read/write or mmap, the kernel performs the alignment automatically; a small read or write is expanded to the correct block boundary by the kernel before it is issued.
With DIO, it is up to the application to perform block alignment. This incurs some complexity, but also provides an advantage: the kernel will usually over-align to a 4096 byte boundary even when a 512-byte boundary suffices. However, a user application using DIO can issue 512-byte aligned reads, which results in saving bandwidth on small items.
Application complexity
While the previous discussions favored AIO/DIO for I/O intensive applications, that method comes with a significant cost: complexity. Placing the responsibility of cache management on the application means it can make better choices than the kernel and make those choices with less overhead. However, those algorithms need to be written and tested. Using asynchronous I/O requires that the application is written using callbacks, coroutines, or a similar method, and often reduces the reusability of many available libraries.
Choosing the Filesystem and/or Disk
Beyond performing the I/O itself, the database design must consider the medium against which this I/O is done. In many cases, the choice is often between a filesystem or a raw block device, which in turn can be a choice of a traditional spinning disk or an SSD drive. In cloud environments, however, there can be the third option because local drives are always ephemeral – which imposes strict requirements on the replication.
Filesystems vs raw disks
This decision can be approached from two angles: management costs and performance.
If accessing the storage as a raw block device, all the difficulties with block allocation and reclamation are on the application side. We touched on this topic slightly earlier when we talked about memory management. The same set of challenges apply to RAM as well as disks.
A connected, though very different, challenge is providing data integrity in case of crashes. Unless the database is purely in-memory, the I/O should be done in a way that avoids losing data or reading garbage from disk after a restart. Modern file systems, however, provide both and are very mature to trust the efficiency of allocations and integrity of data. Accessing raw block devices unfortunately lacks those features (so they will need to be implemented at the same quality on the application side).
From the performance point of view, the difference is not that drastic. On one hand, writing data to a file is always accompanied by associated metadata updates. This consumes both disk space and I/O bandwidth. However, some modern file systems provide a very good balance of performance and efficiency, almost eliminating the IO latency. (One of the most prominent examples is XFS. Another really good and mature piece of software is Ext4). The great ally in this camp is the fallocate(2) system call that makes the filesystem pre-allocate space on disk. When used, filesystems also have a chance to make full use of the extents mechanisms, thus bringing the QoS of using files to the same performance level as when using raw block devices.
Appending writes
The database may have a heavy reliance on appends to files or require in-place updates of individual file blocks. Both approaches need special attention from the system architect because they call for different properties from the underlying system.
On one hand, appending writes requires careful interaction with the filesystem so that metadata updates (file size, in particular) do not dominate the regular I/O. On the other hand, appending writes (being sort of cache-oblivious algorithms) handle the disk overwriting difficulties in a natural manner. Contrary to this, in-place updates cannot happen at random offsets and sizes because disks may not tolerate this kind of workload, even if used in a raw block device manner (not via a filesystem).
That being said, let’s dive even deeper into the stack and descend into the hardware level.
How modern SSDs work
Like other computational resources, disks are limited in the speed they can provide. This speed is typically measured as a 2-dimensional value with Input/Output Operations per Second (IOPS) and bytes per second (throughput). Of course, these parameters are not cut in stone even for each particular disk, and the maximum number of requests or bytes greatly depends on the requests’ distribution, queuing and concurrency, buffering or caching, disk age, and many other factors. So when performing I/O, a disk must always balance between two inefficiencies — overwhelming the disk with requests and underutilizing it.
Overwhelming the disk should be avoided because when the disk is full of requests it cannot distinguish between the criticality of certain requests over others. Of course, all requests are important, but it makes sense to prioritize latency-sensitive requests. For example, ScyllaDB serves real-time queries that need to be completed in single-digit milliseconds or less and, in parallel, it processes terabytes of data for compaction, streaming, decommission, and so forth. The former have strong latency sensitivity; the latter are less so. Good I/O maintenance that tries to maximize the I/O bandwidth while keeping latency as low as possible for latency-sensitive tasks is complicated enough to become a standalone component called the IO Scheduler.
When evaluating a disk, one would most likely be looking at its 4 parameters — read/write IOPS and read/write throughput (such as in MB/s). Comparing these numbers to one another is a popular way of claiming one disk is better than the other and estimating the aforementioned “bandwidth capacity” of the drive by applying Little’s Law. With that, the IO Scheduler’s job is to provide a certain level of concurrency inside the disk to get maximum bandwidth from it, but not to make this concurrency too high in order to prevent the disk from queueing requests internally for longer than needed.
For instance, Figure 3-6 illustrates how read request latency depends on the intensity of small reads (challenging disk IOPS capacity) vs the intensity of large writes (pursuing the disk bandwidth). The latency value is color-coded, and the “interesting area” is painted in cyan — this is where the latency stays below 1 millisecond. The drive measured is the NVMe disk that comes with the AWS EC2 i3en.3xlarge instance.
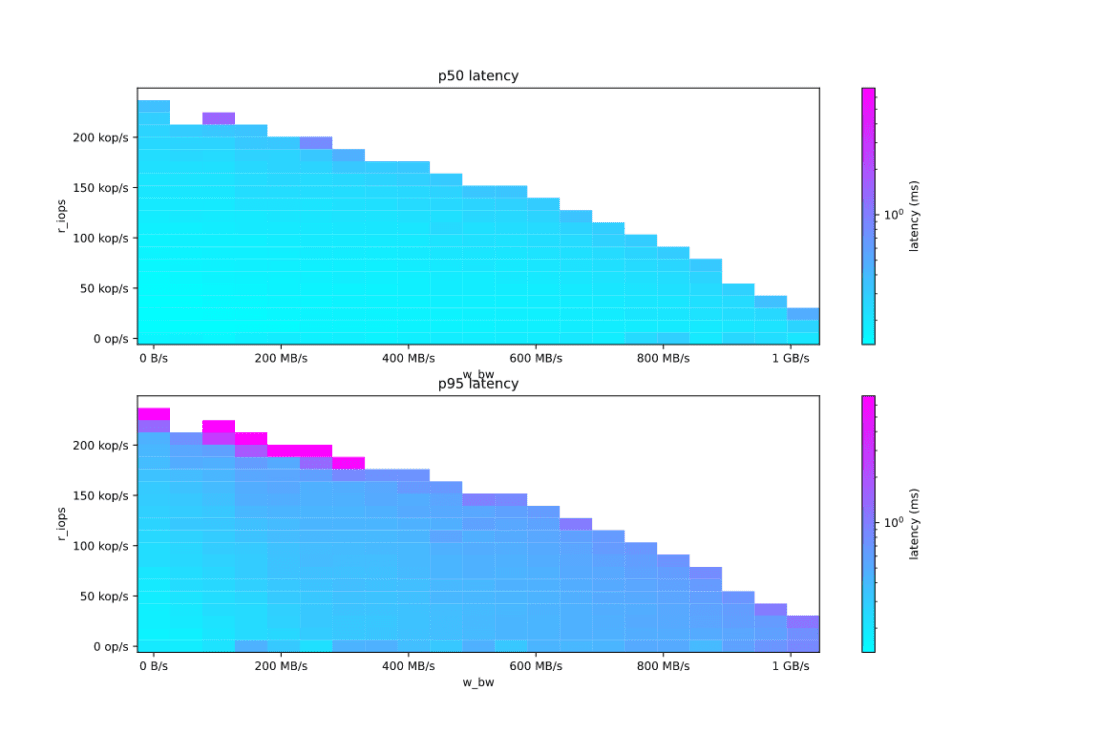
Figure 3-6: Bandwidth/latency graphs showing how read request latency depends on the intensity of small reads (challenging disk IOPS capacity) vs the intensity of large writes (pursuing the disk bandwidth)
This drive demonstrates almost perfect half-duplex behavior — increasing the read intensity several times requires roughly the same reduction in write intensity to keep the disk operating at the same speed.
Tip: How to measure your own disk behavior under load
The better you understand how your own disks perform under load, the better you can tune them to capitalize on their “sweet spot.” One way to do this is with Diskplorer, an open-source disk latency/bandwidth exploring toolset. By using Linux fio under the hood it runs a battery of measurements to discover performance characteristics for a specific hardware configuration, giving you an at-a-glance view of how server storage I/O will behave under load.
For a walkthrough of how to use this tool, see this Linux Foundation video, “Understanding Storage I/O Under Load.”