



Cassandra Time Series Data Modeling FAQs
How Modeling Time Series Data in Cassandra Works
Modeling time series data in Cassandra involves optimizing data storage, retrieval, and querying efficiency:
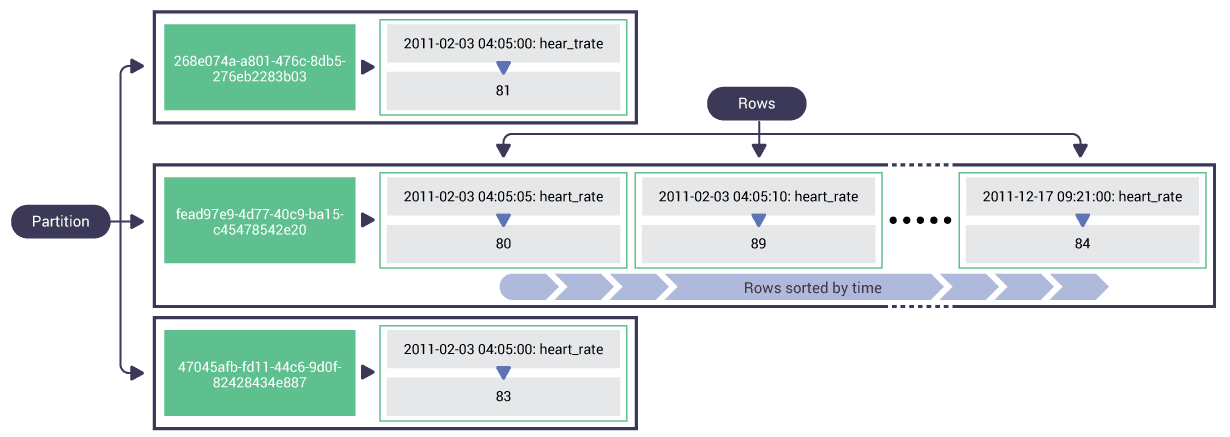
Design of primary keys. Timestamps are often used as a primary key or as part of a composite primary key in time series data modeling. Composite primary keys might include a combination of elements like timestamps, unique identifiers, and partition keys for efficient distribution of data across the cluster.
Time windowing. Data can be organized into time-based “buckets” or partitions to manage data distribution and retrieval and more evenly distribute data and spread varying partition sizes across the cluster.
Create table structure for custom results. Structure tables to support efficient querying based on time ranges. Use denormalization and materialized views to store aggregated data or precompute results for faster queries.
What Are the Benefits of Cassandra Time Series Data Modeling
Data size and storage. A Cassandra data model time series can handle massive volumes of time series data. The size of data structures can vary based on the data volume, retention policies, and query requirements. Cassandra’s distributed architecture can handle large datasets and scale horizontally by adding more nodes to the cluster.
Compaction and TTL. Compaction strategies in Cassandra help manage disk space and optimize read/write performance. Time-to-live (TTL) settings can be applied to data to automatically expire records after a certain period, facilitating data retention policies for time series data.
Compression algorithms. Compression algorithms can enhance read/write performance in Cassandra data modeling time series. Selecting the right compression algorithm depends on the nature of the data and the workload.
There are also a few drawbacks to modeling time series data in Cassandra. Abnormal, uneven access patterns and distributions of data that add pressure in some specific replicas on a distributed database, causing some replicas to receive more traffic than others. Those replicas become overutilized, leaving the remaining cluster members underutilized and serving less traffic.
How to Adapt Cassandra Time Series Data Modeling for Massive Scale
There are several strategies and best practices for massively scalable Cassandra time series data modeling and managing large volumes effectively in the database:
Proper data partitioning. An appropriate partition key evenly distributes data across nodes. Time-based partitioning (e.g., by day, hour) prevents hotspots and evenly distributes write and read loads.
Denormalization and materialized views. Denormalize data to reduce the number of joins required for queries. Use materialized views to precompute and store aggregated or filtered data for faster querying.
Data retention and compaction. Implement an efficient data retention policy to manage the amount of data stored. Configure compaction strategies to manage disk space and improve performance.
Tuning and optimization. Optimize the time series data model for Cassandra and the compaction settings, heap size, and other configuration parameters based on workload and hardware. Monitor and tune the cluster regularly to ensure optimal performance.
Cluster scaling and hardware. Scale the cluster horizontally by adding more nodes to accommodate increased data volume and workload. Consider using higher-capacity hardware or storage options for better performance. Note that although Cassandra focuses only on scaling out, Cassandra-compatiable databases such as ScyllaDB also support vertical scaling (scaling up), which is often preferable to horizontal scaling due to the lower admin overhead.
Time series data schemas. Design data models that fit the query patterns and types of analysis required for time series data. Consider data aggregation or roll-ups for older data to reduce the number of records queried for historical analysis.
Caching and read/write optimization. Cassandra’s built-in single row and key cache mechanisms enhance read performance. However, other caching approaches – such as the specialized internal cache used in the popular Cassandra alternative ScyllaDB – provide even greater read performance.
Consistency level. Adjust and balance consistency levels based on application requirements.
Regular monitoring and maintenance. Monitor cluster performance, data distribution, and resource utilization regularly. Perform routine maintenance such as compaction and nodetool operations to ensure the health of the cluster.
Do Cassandra Time Series Data Modeling Strategies Apply to ScyllaDB?
Yes. ScyllaDB and Cassandra data modeling is quite similar. ScyllaDB offers a similar architecture, data format, and query language as Cassandra, but without Java and its expensive GC pauses. Users commonly improve performance at scale with fewer nodes, reduced administration, and lower infrastructure cost. Switching from Cassandra to ScyllaDB is seamless, requiring minimal code modifications.