




How do you achieve microsecond P99 latency with 1.2M op/sec – for ~180M monthly active users expecting real-time engagement with billions of posts per month? And how do you maintain that for a rapidly-growing service while actually reducing cost? These were the challenges that ShareChat, India’s top social media platform, recently faced. And that’s exactly what Geetish Nayak, Staff Engineer/Architect of Platforms at ShareChat, talked about in ShareChat’s Path to High-Performance NoSQL, a talk that is available on demand.
WATCH THE SHARECHAT WEBINAR ON DEMAND
Spoiler: Geetish and team found that modernizing the NoSQL database powering their services was the key to staying ahead of these challenges. They were able to improve performance 3-5x while reducing costs 50-80%. But the devil is always in the details. How did they orchestrate a migration without disrupting their massive business – and what best practices and strategies did they apply to achieve such impressive results?
About ShareChat, India’s Top Social Media Platform
First, let’s take a step back. In case you’re not one of the many millions using India’s leading multilingual social media platform (ShareChat) or India’s biggest short video platform (Moj), here’s Geetish’s introduction:
The Pressures Driving their Database Migration
With such impressive growth and scale, the team started hitting a number of limitations with their existing NoSQL database as a service (DBaaS). They needed to uplevel performance to support users’ high expectations. “We wanted better performance, with lower latency and higher throughput, so that our app experience was better,” Geetish explained. “With social media, everything is expected fast, so we wanted single-digit millisecond latencies.”
Multi-region disaster recovery was another top concern: services need to remain highly available for their massive user base, especially when there are disaster scenarios. Turning the focus inward, there were two main things that would make the engineering team’s lives easier. First, they needed more insight into database KPIs to facilitate their debugging. And second, they sought greater control over their DBaaS. They wanted the option to change the compaction strategy on the fly for a given use case, adjust how much data to cache on the database, change replication factor and consistency levels, and so on. The more they tried to fine-tune the database for their needs, the more frustrated they grew with the lack of visibility and control.
Exploring Fast NoSQL Alternatives
So, the team started exploring other fast NoSQL database options. Someone shared a ScyllaDB white paper in the team’s Slack, and that sparked Geetish’s interest: “I did a lot more research on aspects like the Seastar framework and the shard-per-core architecture. I saw the NoSQL benchmarks comparing ScyllaDB to the database we were using, as well as other popular NoSQL databases. The numbers looked too good to be true, so we decided to put ScyllaDB to the test with one of our production workloads.”
Using ScyllaDB Operator, they quickly spun up a ScyllaDB cluster on Kubernetes, and tried it out against one of their production workloads. The throughput and latency they were able to squeeze out of a relatively small number of nodes with minimal configuration was impressive. After testing ScyllaDB with additional workloads and achieving even more satisfying results, they decided to “go full throttle” on deploying ScyllaDB across ShareChat.
Geetish and his team then set out to migrate ShareChat’s core use cases to ScyllaDB. For example, ScyllaDB is now powering their chat application, real-time notification framework, counters (for views, likes, shares, comments, and 10+ others), ads data management platform, in-memory database use cases, and data science feature store.
A Peek Into ShareChat’s System Architecture
Here’s a peek at how one of those use cases is architected. The counters powering all the views, likes, shares, and other interactions for 50 million users per day rely on an Apache Kafka cluster that’s hosted internally.
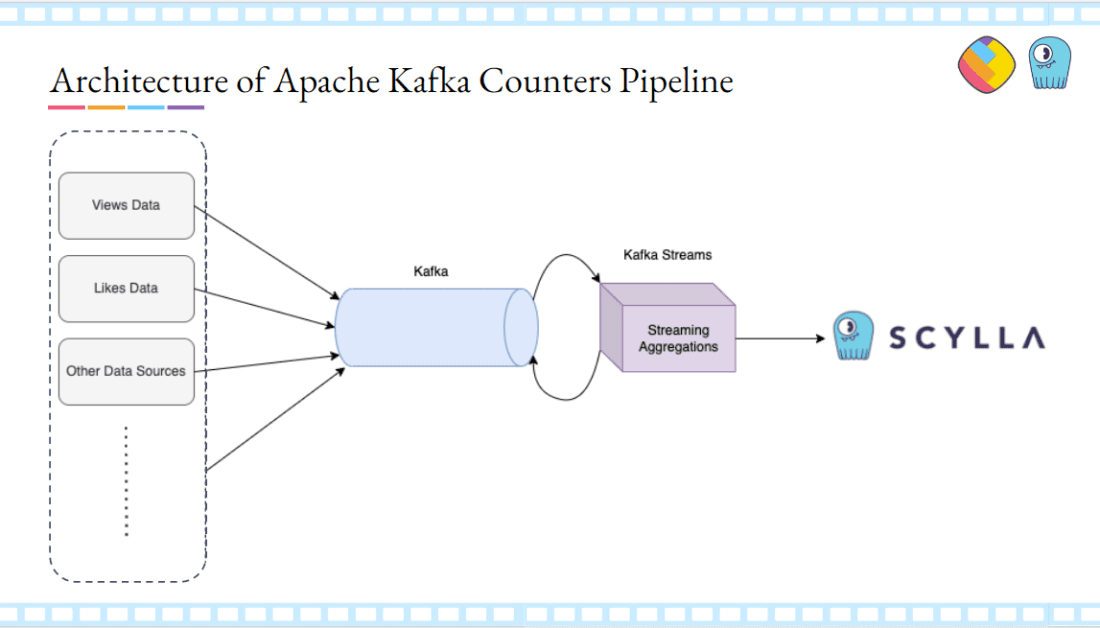
All of the views for a particular post get pushed to a Kafka cluster, aggregated with Kafka Streams according to ShareChat’s business logic. After that aggregation completes, they’re written to ScyllaDB using the “atomic counters” data type.
Go Deeper Into ShareChat’s System Architecture, Migration Strategy, ScyllaDB Best Practices, and DBaaS Experiences
Watch the complete video to hear Geetish share:
- The architecture behind other ShareChat use cases – including their data science feature and real-time communication framework
- Details of how they onboarded ~80TB of data and ~40 services to ScyllaDB – including one cluster that’s 20 TB with a throughput of 1.2M op/sec
- Their performance and cost savings results so far, including a look at how they are tracking KPIs
- The strategy they devised to migrate with zero downtime
- Core ScyllaDB best practice they have adopted
- Their experience working with ScyllaDB as a fully-managed database-as-a-service

Q & A with Geetish Nayak, Staff Engineer/Architect – Platforms at ShareChat
 We hosted this webinar in two time zones to better accommodate the global community. However, this meant viewers in one timezone did not have the access to questions answered in the other timezone. Here is a recap of some of the top audience questions, along with Geetish’s response.
We hosted this webinar in two time zones to better accommodate the global community. However, this meant viewers in one timezone did not have the access to questions answered in the other timezone. Here is a recap of some of the top audience questions, along with Geetish’s response.
About their ScyllaDB Deployment
Can you talk about optimizing for cost, and also for performance?
We use a lot of best practices. For example, with ScyllaDB’s shard-per-core architecture, the
application connects directly to the database node that contains the sharded data. Within the node, it connects directly to the vCPU owning the data, cutting latency and routing which optimizes performance and decreases costs. There are savings at both ends: the database is performing nicely, the apps are performing nicely, you don’t require an in-memory cache in between, and you don’t require an in-memory cache in your app. I think all of these things help.
For the counter nodes, what was the RAM & CPU per node?
n2-highmem-48 * 3 nodes
Handles 300K(Reads/Writes Ratio is 2:1) ops easily – with 50 percent CPU
When building a new use case, what’s the process for the design of the ScyllaDB cluster? Is redundancy in data expected in order to improve latency?
Redundancy is required for both high availability and latency. We use local disks to store data, and when a node goes down the data might get lost. Redundancy helps with that. Because of local disks, our latency numbers are much better.
With the distribution of content in social media, you’re going to have some hot posts where you could have hundreds of thousands or millions of likes. Do you run into hot shards or partitions when dealing with that?
Yes, absolutely. We do run into hot shards. I think one of the diagrams that I shared actually shows the hot partitions when one of the vCPUs was very much bombarded. We think of how many times are we getting these kinds of queries? Do we need to further partition our data? That’s a call that we have to make. Also, the live migration framework helps us; if you want to migrate from one table in ScyllaDB to another table in ScyllaDB by changing the partition key, you can also do that.
Did you begin with the open source version of ScyllaDB?
Yes, we did begin with ScyllaDB OSS to evaluate. But once the evaluation was done, we went with the enterprise version.
What is the total size of the data that you migrated from your previous database to ScyllaDB?
In total, 80TB – [and we] plan to add an additional 50 TB. But these are spread across different clusters.
What compaction strategy did you guys use?
We have a default Incremental Compaction Strategy for most of our clusters. We will be moving to Leveled Compaction Strategy as we see that most of our workloads are very read heavy.
ScyllaDB is a wide column database… does it support aggregation?
Yes, it does support aggregation functions: https://docs.scylladb.com/stable/cql/functions.html#aggregate-functions
About NoSQL Database Comparisons
What was the existing database you were using?
We were using databases available in GCP and also have other vendors for in-memory databases.
Did you consider any other databases?
We were looking for a pure NoSQL database. I had prior experience with Cassandra and knew the challenges there. We already were using some NoSQL databases to benchmark against. ScyllaDB’s website has detailed comparisons against every other major NoSQL database in the market.
Does ScyllaDB give better performance for caching compared to Redis?
I would answer this in 3 points:
- For pure Redis use cases where you are using far more involved data structures provided by Redis, ScyllaDB is not a good choice.
- If you are using Redis as a Key-Value store, then yes you can achieve almost similar numbers like Redis.
- If you are using Redis to cache some portion of data because your primary database is slow, you can get rid of Redis. With ScyllaDB your primary database is super fast – so why do you need Redis.
In ShareChat we have done #2 and #3.



