




What is DC/OS?
From https://dcos.io
DC/OS (the datacenter operating system) is an open-source, distributed operating system based on the Apache Mesos distributed systems kernel. DC/OS manages multiple machines in the cloud or on-premises from a single interface; deploys containers, distributed services, and legacy applications into those machines; and provides networking, service discovery and resource management to keep the services running and communicating with each other.
ScyllaDB on DC/OS
A centralized management system is often used in modern data-centers, and lately the most popular and in-demand type of such a management system is centered around running and controlling containers at scale. We have already covered the aspects of running ScyllaDB on one such system, Kubernetes, and in this post we will cover another – DC/OS.
Being able to natively run ScyllaDB in DC/OS will allow for simplified deployment, easy management, maintenance and troubleshooting, as well as bring the hardware and cloud instances, dedicated to running ScyllaDB, under the same pane of glass as the rest of the DC/OS managed servers.
Since DC/OS manages containers, in order to run ScyllaDB with its maximum performance, we will have to tune the hosts and dedicate them to ScyllaDB containers. ScyllaDB can have a performance overhead if the container is not optimized, so in order to reach ScyllaDB’s peak performance, some additional steps would have to be taken:
- Host network tuning
- Host disk(s) tuning
- Pin ScyllaDB containers to specific hosts
- Pin ScyllaDB containers to a set of host CPU cores, after tuning
We will cover all of these steps in a demo setup, described below.
The Setup
For this test, we have built a small cluster with minimal DC/OS configuration, consisting of a single DC/OS Master node and three Agent nodes, which will be dedicated to the ScyllaDB cluster.
The Agents are i3.16xlarge AWS EC2 instances, with the master a smaller m4 instance. Each Agent has several NVME drives, which will be gathered into a single RAID array, formatted as XFS and mounted under /scylla. Then network and disk tuning will be applied, and a list of CPU cores to be assigned to the ScyllaDB containers will be extracted. Finally, the ScyllaDB containers will be started, using the native, ScyllaDB packaged docker containers from Docker Hub.
Host preparation
First we gather all the drives into a single RAID array using mdraid, format as XFS and mount under a previously created mountpoint /scylla. The common recommended mount options are noatime,nofail,defaults. Data and commitlog directories will also have to be created inside the /scylla mountpoint.
Since host networking will be used, we will have to open the ScyllaDB ports in iptables or firewalld.
In order to run the tuning, we will also need to install perftune.py and hex2list.py. Perftune is the script that takes care of network and disk tuning, reassigning of IRQs to specific CPU cores and freeing the other cores for ScyllaDB’s exclusive use. Hex2list is a script that can decode a hexadecimal listing of CPU cores perftune makes available for ScyllaDB, into a human and docker readable form. The scripts will be installed if the ScyllaDB packages are installed on the hosts, but it is also possible to manually install just these two scripts to save space and avoid clutter on the Agent hosts.
In order for the tuning to persist across host reboots, it is recommended to create a systemd unit that will run on host startup and re-tune the hosts.
With the service enabled and activated, tuning will be performed at the host startup every time.
In order to retrieve the CPU core list, to which the ScyllaDB container will be pinned, the following command needs to be run:
perftune.py --nic ens3 --mode sq_split --tune net --get-cpu-mask|hex2list.pyOn our i3.16xlarge instances, the result was “1-31,33-63” – that is 62 cores from 0 to 63, with cores 0 and 32 excluded (these will be dedicated to networking operations).
NOTE: A working Ansible playbook can be downloaded from https://github.com/scylladb/scylla-code-samples/tree/master/scylla_dcos/dcos_hosts_prep
Running ScyllaDB containers in DC/OS
At this point we have 3 Agent nodes, tuned and with a prepared mountpoint, ready to run our ScyllaDB containers.
Let us create the first ScyllaDB node:
In DC/OS UI (or CLI), we created a new service which will run on host 10.0.0.46 using the following JSON:
{
"id": "/scylla001",
# arguments DC/OS will pass to the docker runtime, here we pass all the
# important arguments as described in ScyllaDB’s docker best practices guide
"args": [
# --overprovisioned=0 tells the container to adhere to the strict resource
# allocation, because no other containers will be running on this host
"--overprovisioned",
"0",
# seeds is where the IPs of hosts running the seed ScyllaDB nodes are provided.
# Since this is the first node, we will specify it as seed for itself. For
# subsequent nodes, we will provide this node’s IP (or IPs or other already
# running nodes)
"--seeds",
"10.0.0.46",
# broadcast-address, broadcast-rpc-address, listen-address - all of these
# should be set to the hosts’ IP address, because otherwise ScyllaDB will
# pick up the docker-internal IP (172.17.0.2 etc) and will not be available
# outside the container
"--broadcast-address",
"10.0.0.46",
"--broadcast-rpc-address",
"10.0.0.46",
"--listen-address",
"10.0.0.46",
# cpuset is where we provide the CPU core list extracted earlier, when tuning
# the hosts, for ScyllaDB to attach to the correct set of CPU cores
"--cpuset",
"1-31,33-63"
],
# constraints is where we ensure this instance of ScyllaDB is only run on this
# particular host. Constraints in DC/OS can be extended with additional rules
# but in our example, the basic IS rule ensures each of our ScyllaDB nodes is
# running on a separate host, dedicated to it.
"constraints": [
[
"hostname",
"IS",
"10.0.0.46"
]
],
"container": {
"type": "DOCKER",
# Docker volumes is where the mapping of the previously prepared /scylla
# mountpoint gets mapped to the container’s /var/lib/scylla/
"volumes": [
{
"containerPath": "/var/lib/scylla/",
"hostPath": "/scylla/",
"mode": "RW"
}
],
# Docker image points to the upstream Docker Hub ScyllaDB container image to
# download and use. Since no tags are used, just like with docker pull, we
# get the latest official image
"docker": {
"image": "scylladb/scylla",
"forcePullImage": true,
"privileged": false,
"parameters": []
}
},
# Cpus is the core count to be assigned to the container as DC/OS sees it, and
# as has been explained above, ScyllaDB gets access to 62 cores out of 64,
# after tuning the host.
"cpus": 62,
"instances": 1,
# Mem is the memory allocation in GiB, the number is slightly lower than what
# the EC2 i3.16xlarge provide, leaving some for the host OS to use.
"mem": 485000,
# Here we set the container to use host mode, as per docker best practices. "networks": [
{
"mode": "host"
}
],
# portDefinitions is where the ports mapped between the container and host
# are defined.
"portDefinitions": [
{
"protocol": "tcp",
"port": 9042
},
{
"protocol": "tcp",
"port": 9160
},
{
"protocol": "tcp",
"port": 7000
},
{
"protocol": "tcp",
"port": 7001
},
{
"protocol": "tcp",
"port": 10000
}
]
}NOTE: This JSON should be used without the comments. For a clean example, please see https://github.com/scylladb/scylla-code-samples/tree/master/scylla_dcos
When this container starts, we will see a docker container running the latest official ScyllaDB image running on host 10.0.0.46.
With our first ScyllaDB node up and running, we can start two more services (scylla002 and scylla003), only changing their ID and IPs defined in broadcast-address, broadcast-rpc-address, listen-address and constraints, leaving the seeds setting at the IP of the first node.
A few minutes later we have a running 3 node ScyllaDB cluster:
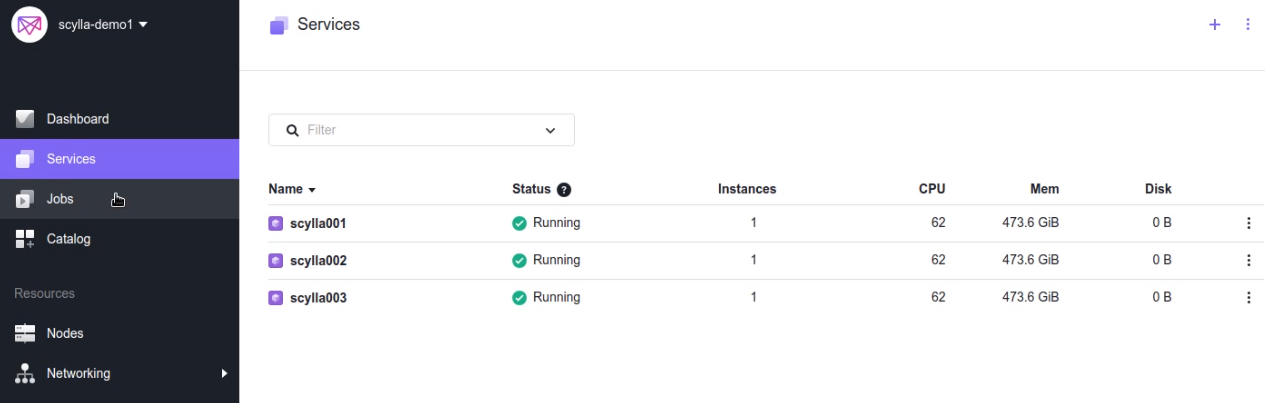
Checking the cluster performance
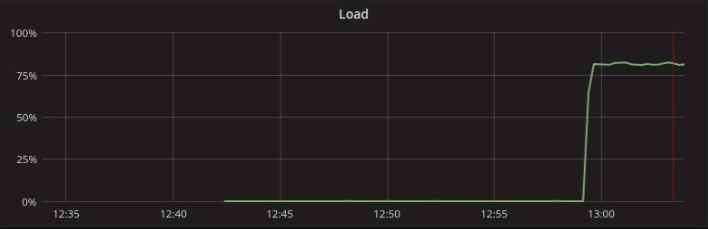
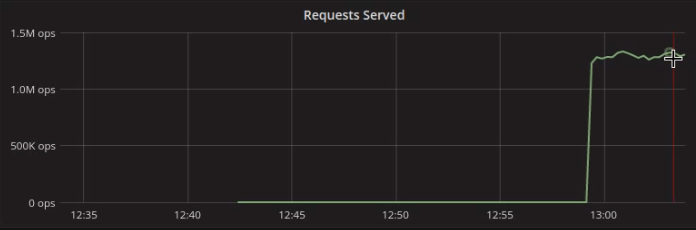
In order to make sure we are operating with enhanced performance and the ScyllaDB containers are not experiencing costly overhead penalties due to being run in containers, we have started eight loaders running cassandra-stress, doing a simple quick write load that should stay mostly in memory, as follows:
cassandra-stress write \
no-warmup \
cl=QUORUM \
duration=100m \
-col 'size=EXTREME(1..1024,2) n=FIXED(1)' \
-mode cql3 native connectionsPerHost=16 \
-rate 'threads=400 limit=150000/s' \
-errors ignore \
-pop 'dist=gauss(1..1000000000,500000000,5000000)' \
-node $NODESAs expected, at 80% load, the cluster is well capable of sustaining over 1.3 million ops per second:
Day 2 operations
While deploying a cluster and running a stress test is an important step, it is even more important to consider how one would deal with the common day-to-day tasks of an operator managing ScyllaDB on top of DC/OS. Here are a few common tasks explained:
- Cqlsh queries against the cluster: these can be run normally, just like when ScyllaDB is deployed on bare-metal, using the host IPs.Using our existing cluster, a typical command would be:
CQLSH_HOST=10.0.0.46 cqlsh - Nodetool commands: these can be run while logged into any of the ScyllaDB containers interactively or from a remote host (if the JMX API ports are exposed in portDefinitions and nodetool is preconfigured to listen on the host IP address).
- Monitoring: we recommend using ScyllaDB’s own monitoring, based on Prometheus and Grafana. These can be pointed at the host IPs in order to monitor all aspects of the ScyllaDB instances.
- If an Agent host in the cluster goes down: if the host can be brought back up again, simply restart the service in DC/OS. Since it is pinned to the host, it will start up on the same host again, using the same mountpoint and thus the same data.
- If the host cannot be restored, delete the DC/OS service, provision a new host, add it to DC/OS as an Agent, tune and create a new ScyllaDB service, pointing at an existing node IP as a seed.
- If all the Agents go down: the services in DC/OS can be started (manually or automatically, depending on their configuration) once the Agent hosts are online. Since the ScyllaDB mountpoint contains the data, and the host auto-tunes itself on startup, nothing else will need to be done.
- Scaling the ScyllaDB cluster: provision a new host, tune it, and create a new ScyllaDB service pointing at an existing node IP as a seed. This process can be easily automated.
Next Steps
- Learn more about ScyllaDB from our product page.
- See what our users are saying about ScyllaDB.
- Download ScyllaDB. Check out our download page to run ScyllaDB on AWS, install it locally in a Virtual Machine, or run it in Docker.
References



