



Database Sharding FAQs
What is Database Sharding?
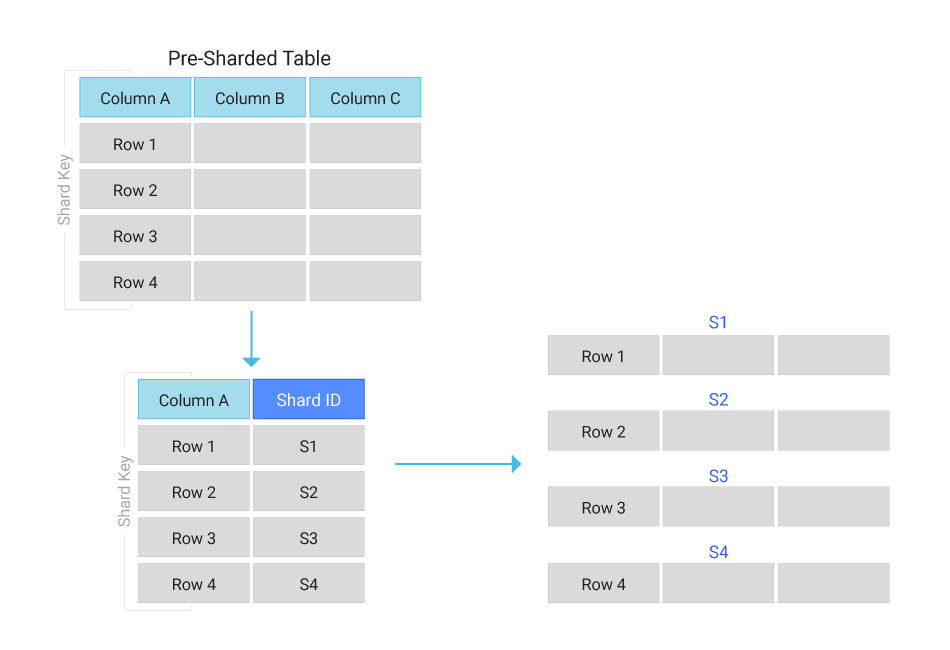
Sharded databases relate to horizontal partitioning—the separation of a single table by rows into multiple tables or partitions. Database sharding techniques involve breaking data into multiple logical shards distributed across database nodes, referred to as physical shards.
There are different ways to determine which shard receives reads and writes. Some database sharding is implemented at the application level. Some database management systems have built in database sharding capabilities, allowing direct database level implementation.
Sharding poses 3 key challenges:
- Choosing a way to split data across nodes
- Re-balancing data and maintaining location information
- Routing queries to the data
Benefits and Drawbacks of Database Sharding
Database sharding is the process of partitioning data in a search engine or database into various smaller distinct shards. Each shard could be a different table, physical database, or schema held on a separate database server. Here are some of the benefits and drawbacks associated with database sharding.
Advantages of Database Sharding
Database sharding scalability. The main draw of database sharding solutions is that they facilitate scaling out, or horizontal scaling. By adding more machines to an existing stack or scaling horizontally, an organization can permit more traffic, enable faster processing, and spread out the load.
Database sharding performance. Another benefit of sharding a database is to speed query response times. Sharding one massive table into multiple shards allows queries to pass over fewer rows and return result sets much more rapidly.
Reliability and availability. Sharding can mitigate the impact of outages on unsharded databases. A sharded database is likely to limit the effects of an outage to a single shard.
Drawbacks of Sharding. Database sharding can ease scaling and improve performance, but it may also cause certain problems:
Complexity. Implementing a sharded database architecture properly can be highly complex. This is especially evident when sharding SQL databases, which are at high risk of corrupted tables and lost data throughout the process.
Hotspots. Even correctly implemented database sharding has a major impact on workflows as it requires that teams manage data across multiple shard locations without creating database hotspots and while ensuring even data distribution.
Sharding Architectures
Each of the common sharding architectures distributes data across shards using a slightly different process.
Key-Based Sharding / Hash-based sharding
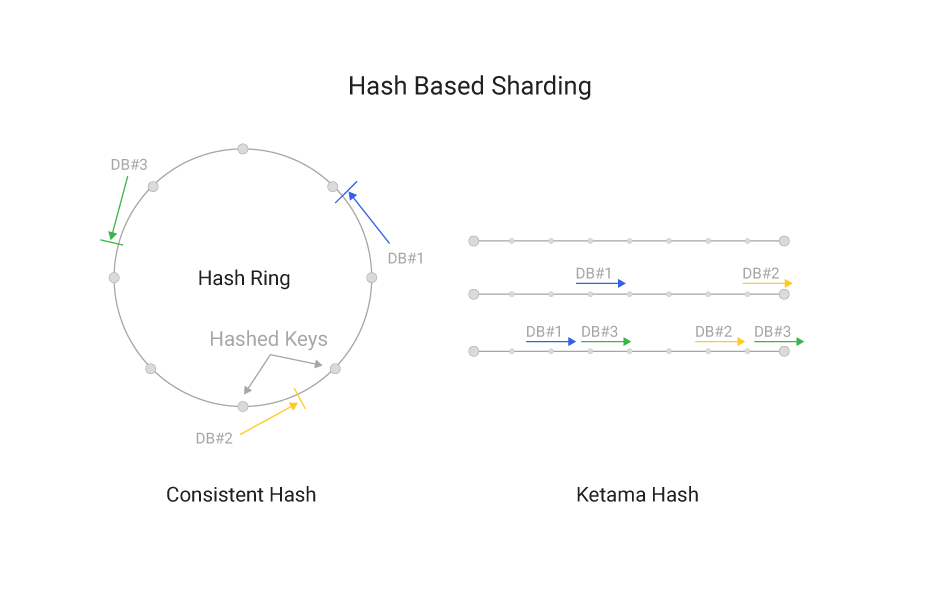
Hash based sharding is the most common way to split data across servers. Each shard key is hashed and the result is used to locate the server the data belongs to. There are a multitude of ways to map hash to a server. Examples are consistent hashing, Ketama or Rendezvous.
The biggest advantage is scaling read and write throughput along with the capacity. A good hash is sufficiently random and even non-uniform key sets are spread across the nodes sufficiently evenly, guaranteeing the workload doesn’t overwhelm a single node.
The key difference between vendors is in how they rebalance data. However, even a perfectly distributed set of buckets is still prone to hotspots.
- An individual key can be too big, and not allow splitting.
- It can be too frequently used. Even if we split the data evenly according to its size, it does not guarantee its even “temperature”.
- Some queries do not allow restricting to a single key – the query requires scanning a key range. This doesn’t map very well to a random distribution created by a hash based sharding.
Range Based Sharding
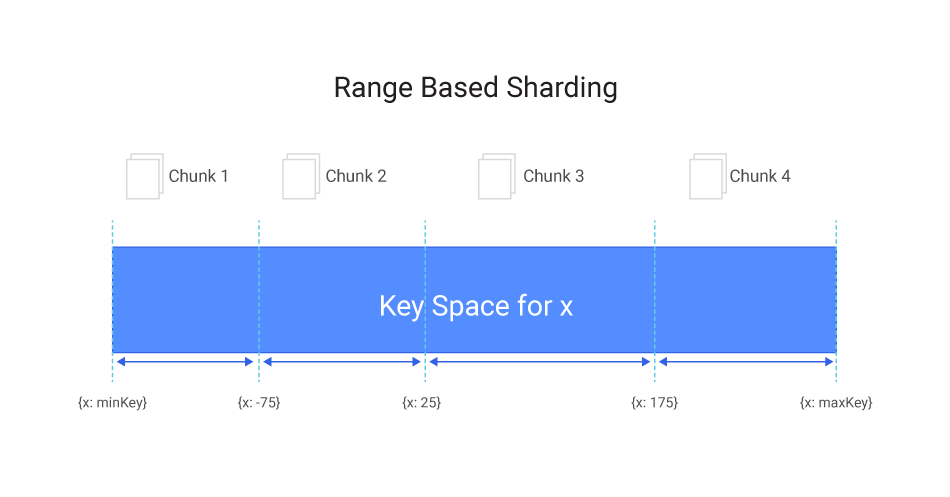
Range based sharding is designed to allow limiting the number of nodes searched when a range query is submitted
It defines a map of key ranges to nodes. If a range becomes too big, it is split. When it shrinks back, it can be coalesced.
Unfortunately, range based sharding creates its own kind of a hotspot: With keys that monotonically increase, new keys always end up in the same range, until it grows and is split, but then again new keys are always at the end of the range.
Directory Based Sharding
In directory-based sharding, the user creates and maintains a lookup table and uses a shard key to track what kind of data is held in which shard. A lookup table is a table that holds a static set of details about where specific data is located.
Here, similar to range based sharding, data from the shard key is written to the lookup table, but with directory based sharding each shard key’s data is tied to a unique shard. Directory based sharding is flexible but it limits to a range of values; it is beneficial where the shard key has a low number of possible values.
Does ScyllaDB Offer Solutions for Database Sharding?
There are two levels of sharding in ScyllaDB. The first, identical to that in Apache Cassandra, the entire dataset of the cluster is sharded into individual nodes. The second level, transparent to users, is within each node.
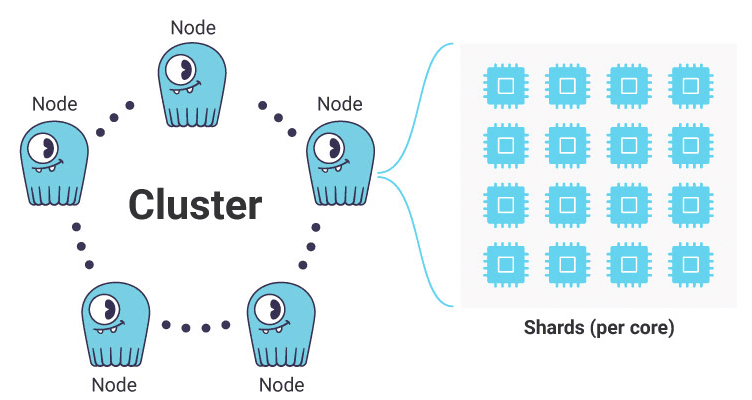
Each ScyllaDB node consists of several independent shards, which contain their share of the node’s total data. ScyllaDB creates one shard per core (technically, one shard per hyperthread, meaning some physical cores may have two or more virtual cores). Each shard operates on a shared-nothing architecture basis. This means each shard is assigned its RAM and its storage, manages its schedulers for the CPU and I/O, performs its compactions, and maintains its multi-queue network connection. Each shard runs as a single thread, and communicates asynchronously with its peers, without locking.
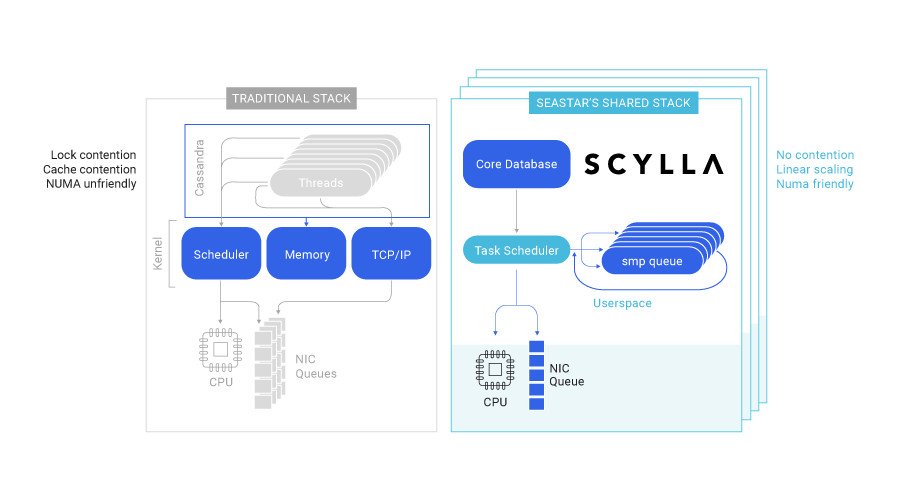
How Does a Shard-Per-Core Architecture Approach Database Sharding?
With shard-per-core database sharding, the node’s token range is automatically sharded across available CPU cores. (More accurately, datasets are sharded across hyperthreads). Each shard-per-core process is an independent unit, fully responsible for its own dataset. A shard has a thread of execution, a single OS-level thread that runs on that core and a subset of RAM.
The thread and the RAM are pinned in a NUMA- friendly way to a specific CPU core and its matching local socket memory. Since a shard is the only entity that accesses its data structures, no locks are required and the entire execution path is lock-free.
Each shard issues its own I/O, either to the disk or to the NIC directly. Administrative tasks such
as compaction, repair and streaming are also managed independently by each shard. In ScyllaDB, shards communicate using shared memory queues. Requests that need to retrieve data from several shards are first parsed by the receiving shard and then distributed to the target shard in a scatter/gather fashion. Each shard performs its own computation, with no locking and therefore no contention.
Each shard runs a single OS-level thread, leveraging an internal task scheduler to allow the shards to perform a range of different tasks, such as network exchange, disk I/O, compaction, as well as foreground tasks such as reads and writes. A task scheduler can select from low-overhead lambda functions (“continuations”). By taking this approach, both the overhead of switching tasks and the memory footprint are reduced, enabling each CPU core to execute a million continuation tasks per second.
Learn more about the shard-per-core database sharding approach:
- ScyllaDB University Essential Course
- Under the Hood of a Shard-per-Core Database Architecture
- More on ScyllaDB’s architecture and how it contributes to its extreme speed at scale