



Database Caching FAQs
Types of Cache Databases
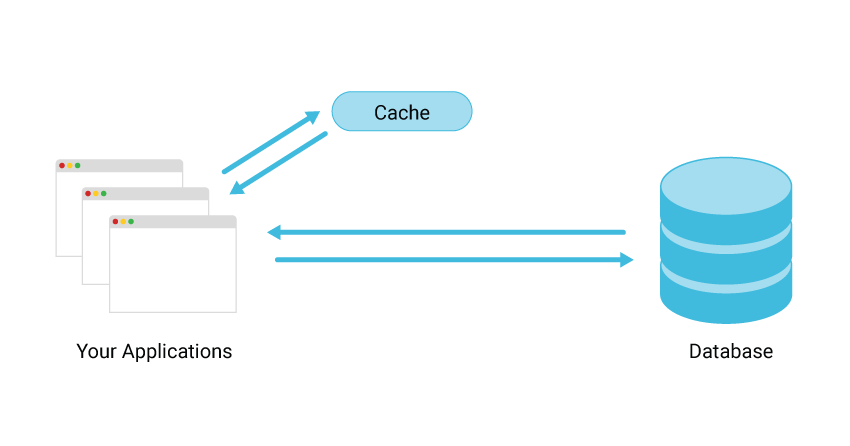
There are several common types of cache databases:
Integrated cache databases such as Amazon Aurora are managed within the database engine and offer built-in write-through capabilities, updating the cache automatically when the underlying data on the database table changes. To leverage data within the cache, users need nothing inside the application tier. However, integrated cache databases are typically limited in capabilities and size to whatever available memory the database instance allocates to the cache. They cannot be used to share data with other instances or for any other purposes.
Local cache databases store frequently used data inside the application. This removes network traffic associated with retrieving data and speeds data retrieval. However, a serious disadvantage is that each node among applications has a resident cache that functions and stores data in a disconnected way. This means that an individual node cannot share information stored with other local individual caches, including web sessions, database cached data, or user shopping carts. In a distributed environment that supports dynamic, scaling environments with information sharing, this is a challenge. Additionally, most applications use multiple servers, and coordinating values across them, each with its own cache, is a major issue.
See why and how Comcast eliminated their 60 cache servers
In addition, locally cached data is lost when outages occur. These cons are mostly mitigated with remote or side caches, separate or multiple instances dedicated to in-memory cached data storage.
Typically built on NoSQL stores such as Redis, remote caches are stored on dedicated servers. Remote caches offer many more requests per second per node and some offer high availability. They also boast average request latency in the sub-millisecond range, which is considerably faster than disk-based cache databases. Remote caches also serve as connected clusters in distributed environments and work adjacently to the database itself, not directly connected to it.
Database Caching Approaches Compared
Pre-caching vs. Caching
Pre-caching is a process that loads data ahead of time in anticipation of its use. For example, when a web page is retrieved, the pages that users typically jump to when they leave that page might be pre-cached in anticipation. An application might pre-cache files or records that are commonly called for at some time during a session. Pre-caching differs from web and browser caching, in that pre-caching implies storing files that are expected to be used, whereas regular caching deals with files already requested by the user.
Pre-caching requires some method to determine what should be cached ahead of time (i.e., time and expertise needed to make manual or procedural decisions on what to pre-cache). However, pre-caching might contain data that never actually gets used. If you are caching in an all-RAM instance, that means you’re paying money on expensive resources for pre-caching info of low-value.
Caching, on the other hand, is populated as needed. Since the cache is reactive, the first transaction to it is likely to be much slower than subsequent actions on the same data. Since nothing is primed in the cache, it has to be populated as requests are served. This could saturate certain requests until the cache is fully populated.
Side Cache vs. Transparent Cache
A further distinction exists between side caches and transparent caches. External cache deployments are typically implemented in the form of a “side cache.” The cache is independent of the database, and it places a heavy burden on the application developer: The application itself is responsible for maintaining cache coherency. The application performs double writes, both for the cache and for the database. Reads are done first from the cache, and, if the data isn’t found, a separate read is dispatched to the database.
Transparent database caching strategies, such as that used by Amazon DAX, improves on this situation somewhat by unburdening the application developer. Only a single database query needs to be issued. The figure above shows the advantages of a transparent cache like the DAX: It doesn’t require application changes and it is automatically coherent. DAX eliminates the major data coherency problem.

Free book PDF on Latency, including a caching chapter
Database Caching Disadvantages
Database caching advantages have been outlined above. However, there are numerous disadvantages to database caching strategies that are commonly overlooked.
An external cache adds latency
A separate cache means another hop on the way. When a cache surrounds the database, the first access occurs at the cache layer. If the data isn’t in the cache, then the request is sent to the database. The result is additional latency to an already slow path of uncached data. One may claim that when the entire dataset fits the cache, the additional latency doesn’t come into play, but most of the time there is more than a single workload/pattern that hits the database and some of it will carry the extra hop cost.
An external cache is an additional cost
Caching means DRAM which means a higher cost per gigabyte than SSDs/HDDs. In a scenario when additional RAM can store frequently accessed objects, it is best to utilize the existing database RAM, and potentially increase it so it will be used for internal caching. In other cases, the working set size can be too big, some cases reaching petabytes and thus another SSD friendly implementation is preferred.
External caching decreases availability
The cache’s HA usually isn’t as good as the database’s HA. Modern distributed databases have multiple replicas; they also are topology aware and speed aware and can sustain multiple failures. For example, a common replication pattern in Scylla is three local replicas, and a quorum is required for acknowledged replies. In addition, copies reside in remote data centers, which can be consulted. Caches do not have good high-availability properties and can easily fail, or have partial failures, which are worse in terms of consistency. When the cache fails (and all components are doomed to fail at some point), the database will get hit at full throughput and your SLA will not be satisfied together with your guarantees to your end users.
Application complexity —your application needs to handle more cases
Once you have an external cache, you need to keep the cache up to date with the client and the database. For instance, if your database runs repairs, the cache needs to be synced (or invalidated). Your client retry and timeout policies need to match the properties of the cache but also need to function when the cache is done. Usually, such scenarios are hard to test.
External caching ruins the database caching
Modern databases have internal caches and complex policies to manage their caches. When you place a cache in front of the database, most read requests will only reach the external cache and the database won’t keep these objects in its memory. As a result, the database cache isn’t effective, and when requests eventually reach the database, its cache will be cold and the responses will come primarily from the disk.
External caching isn’t secure
The encryption, isolation and access control on data placed in the cache are likely to be different from the ones at the database layer itself.
External caching ignores the database knowledge and database resources
Databases are very complex and impose high disk I/O workloads on the system. Any of the queries access the same data, and some amount of the working set size can be cached in memory in order to save disk accesses. A good database should have multiple sophisticated logic to decide which objects, indexes, and access it should cache.
How Does Apache Cassandra Approach Caching
Apache Cassandra uses several separate competing caches (key cache, row cache, on/off-heap, and Linux OS page cache) that require an operator to analyze and tune — a manual process that will never be able to keep up with users’ dynamic workloads.
How Does ScyllaDB Approach Database Caching?
The ScyllaDB NoSQL database offers a different approach to caching: one that addresses the significant problems covered above, while also delivering the performance gains that caching promises.
ScyllaDB has a unified row-based cache system that automatically tunes itself, allowing it to adapt to different data access patterns and workloads. With ScyllaDB, with its inherent low-latency design, there’s no need for external caches, further simplifying the infrastructure.
This design decision means higher ratios of disk to RAM, yet also better utilization of your available RAM. Each node can serve more data, enabling the use of smaller clusters with larger disks. The unified cache simplifies operations, since it eliminates multiple competing caches and is capable of dynamically tuning itself at runtime to accommodate varying workloads.
Learn more about ScyllaDB and why it’s the fastest NoSQL database – optimized for real-time applications.