



Data Ingestion FAQs
What is Data Ingestion?
Data ingestion is the process toward the beginning of the data engineering pipeline and the first layer of all big data and internet of things (IoT) architectures.
What is the purpose of data ingestion?
To gather, prepare, and load data from various sources into a central location or repository, making it available for analysis, processing, reporting, and other applications. This serves several key purposes in the data pipeline:
Centralization. Data ingestion centralizes information which may be scattered across different systems, databases, or formats, making it easier to manage and access.
Data integration. Organizations use multiple data ingestion platforms, software applications, and databases. Data ingestion integrates data from diverse sources, creating a unified view for analysis.
Real-time processing. Ingestion enables real-time data streaming, so organizations can react quickly to changing conditions or events.
Data transformation. Raw data may need cleaning, formatting, or other transformations before analysis. Data ingestion can include data transformation steps to ensure the data is usable.
Analytics and decision-making. Centralized data eases querying, analysis, and reporting, helping organizations derive insights, make informed decisions, and identify trends.
Data Ingestion Examples
Two good examples or use cases for data ingestion are e-commerce analytics and IoT data management.
E-commerce analytics. Enterprise level e-commerce businesses that operate across multiple platforms and markets can more easily gain insights into things like sales trends and inventory management by collecting data from sources such as online orders, customer reviews, social media mentions, and website traffic and use it to analyze customer behavior and preferences, optimize product offerings, and improve marketing strategies.
IoT municipal data management. Devices and sensors linked to internet of things (IoT) devices in a smart city scenario generate massive amounts of data continuously. For example, real-time data from sensors embedded in traffic lights, waste management systems, and public transportation could provide valuable insights for urban planning and resource allocation. This kind of system makes real-time data analysis possible in support of city officials who need to make informed decisions about traffic flow, energy consumption, and public services.
Here are some specific examples of how teams are managing large-scale data ingest projects:
Palo Alto Networks – How the leading cybersecurity company is ingesting and correlating millions of records per second from different sensors, in different forms and formats
ShareChat – How India’s largest social media network handles the aggregations of a post’s engagement metrics/counters at scale with sub-millisecond P99 latencies for reads and writes.
Epic Games/Unreal Engine – Why and how the gaming/3D graphics giant places a binary cache in front of NVMe and S3 to accelerate global distribution of large game assets used by Unreal Cloud DDC
Trellix (formerly FireEye) – How this cybersecurity leaders uses a graph database system to store and facilitate analysis of threat intelligence data

Data Ingestion & Storage Use Cases
There are a variety of use cases that require teams to ingest and store a high variety, volume, and velocity of data:
Data Ingest & Storage/Event Streaming. Capture and store in series a continuous flow (stream) of data reflecting change in state (event; e.g., log-in, purchase, web search) for analysis, alerts, and action in real time.
Data Ingest & Storage/Cache Layer. Storage for a subset of data that provides faster application read and write speed than the primary storage.
Data Ingest & Storage/Data Store. A repository for the persistent storage, management, and distribution of various types of data, for various applications, and by various means.
Data Ingest & Storage/Graph Storage. Equip applications designed for graph data modeling and computation such as JanusGraph and Quine with an underlying storage layer or full database.
Data Ingest & Storage/DB Dedupe. Provide a secondary database to identify and eliminate unnecessary copies of data to increase application performance and reduce storage overhead.
Data Ingest & Storage/Key Management. Equip applications designed for the generation, use, and destruction of cryptographic keys with an underlying database.
Data Ingest & Storage/Geospatial Storage. Equip applications designed for querying and analyzing geospatial data (earth’s geography, events, mapping) with an underlying database.
Data Ingest & Storage/NMS Storage. Equip applications designed for network management and monitoring (such as OpenNMS) with an underlying database.
What Does the Data Ingestion Process Involve?
The data ingestion process flow could involve:
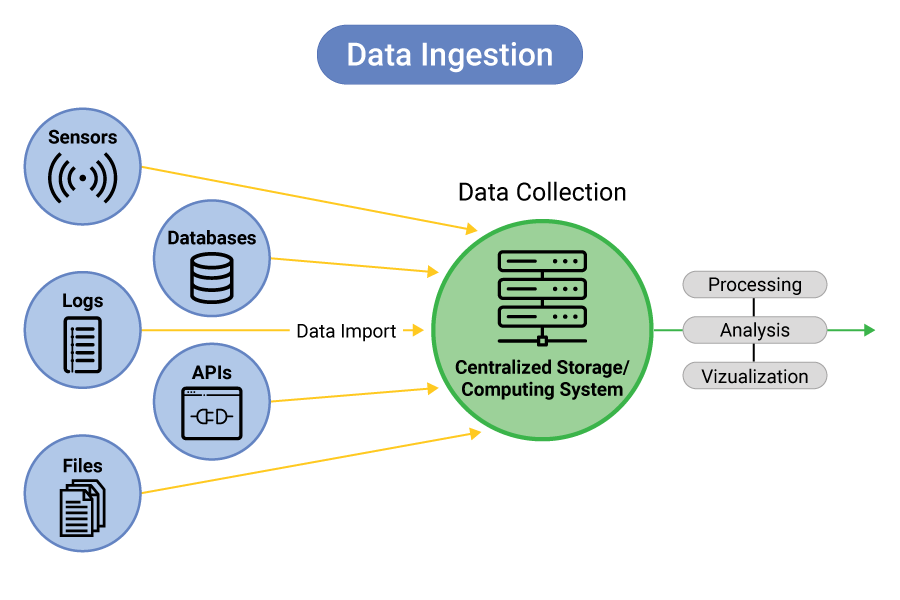
Data collection. The system collects data from various internal or external systems, databases, APIs, sensors, logs, files, streams, and other sources.
Data extraction. Raw data is extracted from source systems, which could involve reading databases, APIs, log files, or other data storage mechanisms.
Data transformation. Data engineers clean, validate, and transform the raw data into a format suitable for storage and analysis, for example by handling missing values, removing duplicates, and converting data types.
Data loading. Transformed data is loaded into a storage system, such as a data lake, data warehouse, or database to ensure it is organized and easily accessible.
Data processing. Depending on the use case, further processing steps like aggregations, calculations, or enrichment might be performed on the ingested data.
Data storage. The ingested and processed data is stored in a structured manner that allows for efficient querying and retrieval and makes it easier to move data on demand.
Metadata management. Metadata about ingested data (such as source, timestamps, data types) is often captured and stored with it to aid in data lineage tracking and quality control.
Data availability. Once ingested, the data is available for analysis tools, reporting systems, machine learning models, and other applications.
Monitoring and error handling. Continuous monitoring during data ingestion and processing ensures that the ingestion process is functioning correctly and any errors or discrepancies are identified and addressed.
Scalability. Depending on the volume and velocity of data, the ingestion process must be designed to scale effectively to handle large and growing datasets.
Data Ingestion Types
There several types of data ingestion based on how they collect, process, and integrate data:
Batch processing. This type of data ingestion moves data in batches at scheduled intervals and is best-suited to applications that only require periodic updates.
Real-time or streaming data ingestion. Use cases for real time data ingestion include stock market trading, fraud detection, real-time monitoring, and other applications that demand instant insights.
Hybrid- micro batching or lambda architecture based data ingestion. This type of data ingestion balances latency and throughput and is often used in telematics.
Log-based ingestion. Data is ingested from log files generated by applications, systems, or devices which can include valuable information about system performance, user interactions, and errors. Log-based ingestion is common in troubleshooting, performance analysis, and security monitoring.
File-based ingestion. Data is ingested from CSV, JSON, XML, and other types of files. This is a versatile ingestion method when data exists in various sources and is commonly used for historical data uploads.
Database replication. Data is ingested by replicating or copying data from one database to another, often to create backups, distribute data across multiple locations, or migrate data between databases.
API data ingestion. Data is ingested from external sources through APIs, a structured means of accessing and retrieving data from other applications or platforms.
Web scraping. Data is extracted from websites and web pages, often to gather information for data analytics, competitive analysis, and other research purposes.
Message queues and publish-subscribe systems. Messaging data ingestion systems allow data to be ingested and processed asynchronously. Producers send messages to topics, and consumers subscribe to those topics to process the data.
IoT data ingestion. Internet of things (IoT) devices generate massive amounts of sensor readings, device status, and other data. The Azure data ingestion offering Azure Data Factory is an example of this type of data ingestion.
Cloud data ingestion. Many cloud platforms offer specialized tools for data ingestion as a service. For instance, AWS data ingestion services like Amazon Kinesis offer real-time data streaming support and AWS DataSync helps users move data to the cloud.
How to Ingest Data: Data Ingestion Best Practices
Evidence-based data ingestion techniques and best practices ensure that the process is efficient, accurate, and reliable. Here are some tips that can help shape a plan to ingest data:
Data validation and cleaning. Validate incoming data for correctness and integrity. Handle missing values, outliers, and anomalies appropriately. Implement data quality checks to ensure that ingested data meets predefined criteria.
Schema management. Define and maintain a clear data schema that outlines data types and structures to ingest. Handle schema changes gracefully to prevent disruptions to the process.
Incremental loading. Implement incremental loading techniques to ingest only changed data since the last ingestion to reduce processing time and resource usage.
Deduplication. Identify and eliminate duplicate records during data ingestion to maintain data accuracy and avoid redundancy.
Scalability and parallelism. Design the ingestion process to handle large volumes of data by leveraging parallel processing and distributed systems.
Monitoring and logging. Implement robust monitoring and logging mechanisms to track the progress of data ingestion. Set up alerts for errors, failures, or performance issues.
Error handling and retry mechanisms. Define each data ingestion strategy to handle errors and failures during data ingestion, including automatic retries and error logging. Implement backoff mechanisms.
Metadata management. Capture metadata about the ingested data, such as source, timestamp, and data lineage. Maintain a metadata catalog for easy tracking and querying of ingested data.
Security and access control. Implement security measures to ensure data privacy and protection during ingestion. Apply access controls to limit who can initiate and manage data ingestion.
Compression and serialization. Reduce the amount of data being transferred and stored with compression techniques to improve efficiency. Serialize data in efficient formats to reduce storage and enhance processing speed.
Data transformation. Apply necessary transformations during ingestion to prepare data for downstream analysis such as data normalization, aggregation, and enrichment.
Backup and recovery. Establish regular backup mechanisms for ingested data to prevent data loss in case of system failures.
Performance optimization. Optimize the ingestion process for speed and efficiency to reduce processing time and resource usage. Monitor and fine-tune the process as needed.
Documentation. Maintain clear documentation for data sources, the ingestion process, and any transformations applied to aid in understanding and troubleshooting the process.
Data retention policies. Define policies for how long ingested data should be retained and when it should be archived or deleted.
Compliance and governance. Ensure that the data ingestion process adheres to relevant data compliance and governance standards.
Benefits of Data Ingestion
Data ingestion both offers benefits that enable organizations to leverage data more effectively for analysis, decision-making, and insights generation and presents challenges associated with the process:
Data Ingestion Capabilities
Centralized data access. Ingesting data from various sources into a centralized location provides a unified view, making it easier to access and analyze.
Timely insights. Real-time and streaming ingestion allows organizations to react quickly to changing conditions and make rapid decisions.
Improved decision-making. Access to a wide range of data types and sources enables better-informed decisions and insights.
Data integration. Ingestion facilitates the integration of data from disparate systems, enhancing the completeness and accuracy of analytics.
Enhanced analytics. Ingested data serves as the foundation for advanced analytics, machine learning, and AI-driven insights.
Historical analysis. Batch ingestion enables historical data analysis, aiding in identifying trends and patterns over time.
Operational efficiency. Ingestion automates the process of collecting and preparing data, reducing manual effort and errors.
Data exploration. Centralized data is readily available for exploration and experimentation, fostering innovation.
Compliance and governance. Ingestion processes can be tailored to ensure data security, compliance, and governance.
Data monetization. Properly ingested data can create opportunities for generating revenue through data-driven products and services.
Data Ingestion Challenges
Data variety and complexity. A variety of data formats, structures, and sources renders the ingestion process complex and demands diverse tools.
Data quality issues. Ensuring data accuracy, consistency, and quality during ingestion can be challenging, especially with large datasets.
Data volume and scalability. Handling and processing large volumes of data in real-time can strain resources and require sophisticated infrastructure.
Latency. Real-time ingestion requires minimizing latency to ensure timely data availability for analysis.
Schema evolution. Changes in data structure or schema can impact the ingestion process and require careful handling.
Integration complexity. Integrating with different source systems and APIs requires understanding their complexities and this can require technical skill.
Data security. Ingested data must be protected from unauthorized access and breaches.
Monitoring and troubleshooting. Tracking the status of multiple data sources and identifying issues during ingestion can be challenging.
Data loss or duplication. Inadequate error handling can lead to data loss or duplication, affecting data integrity.
Resource requirements. Efficient data ingestion, which can be resource-intensive and requires proper infrastructure and resources.
Compatibility. Ensuring compatibility between different systems, databases, and tools is important for successful data ingestion.
Cultural and organizational challenges. Ingestion processes might require changes in workflows and shifts in organizational culture.
What is a Data Ingestion Framework?
A data ingestion framework is a structured set of tools, processes, and methodologies designed to streamline and standardize data ingestion. Data ingestion tools typically offer a drag-and-drop interface with pre-built connectors and transformation, so users have no need to code, manage, and monitor a custom data ingestion pipeline. A data ingestion framework systematically customizes the process to fit the specific needs and technology stack of the organization.
What is Data Ingestion Architecture?
Data ingestion architecture refers to the overall design and structure of the systems and components that facilitate data ingestion. This includes the high-level layout of the hardware, software, networks, and tools used to perform data ingestion tasks. The architecture controls at a high level how data flows from source systems to the destination.
A data ingestion architecture involves various components, such as data sources, data transformation engines, message queues, data processing clusters, storage systems (like data warehouses or data lakes), and monitoring tools. Each architecture must account for the planned volume of data ingest, velocity, variety, latency requirements, security considerations, scalability, and other factors.
Data Acquisition vs Data Ingestion
Data acquisition and data ingestion refer to different stages of the data processing pipeline.
Data acquisition is the collection and capture of raw data at its source. It is often a crucial step for industries that rely on real-time data streams, such as manufacturing, healthcare, and environmental monitoring.
Data ingestion follows data acquisition and involves taking the acquired raw data and preparing it for storage, analysis, and further processing. Data ingestion ensures that the acquired data is structured, cleaned, and organized in a way that is suitable for analytics, reporting, and other applications.
Data Ingestion vs Data Integration
The difference between data ingestion and data integration is that they involve different stages of the data pipeline, and different data preparation tasks focused on analysis, reporting, and other uses.
Data ingestion focuses on efficiently bringing raw data from its sources into a designated repository, often without extensive processing, although with some basic transformation. Ingested data remains available for further processing, analysis, and reporting in a centralized location.
Data integration vs data ingestion, in contrast, is a comprehensive process of combining and harmonizing data to create a unified and coherent view. This process goes beyond just moving data and basic transformations; it includes cleansing, matching, and enriching data to ensure consistency and accuracy. Data integration aims to create a cohesive data environment where data from different sources can be combined, analyzed, and utilized without inconsistencies or duplications.
Data Ingestion vs Data Extraction
In contrast to data ingestion as described elsewhere, data extraction involves querying databases, APIs, log files, web services, or other data storage systems to retrieve specific data sets or information for further processing, analysis, reporting, or integration.
What is Data Ingestion in Big Data?
Big data ingestion is the collection, import, and loading of large amounts of data from various source systems into a big data infrastructure. Big data environments such as data lakes or distributed computing clusters handle massive amounts of structured and unstructured data, often generated in real time or at high velocities.
Apache data ingestion offerings present a good example of commonly-used open source data ingestion tools used in big data environments. Apache kafka data ingestion is a distributed streaming platform that can handle high-throughput, real-time data streams and facilitate the integration of data from various sources. Apache NiFi is another data ingestion open source tool that provides a visual interface for designing data flows and automating data movement and transformation in big data environments.
Does ScyllaDB Offer Data Ingestion Solutions?
Yes. ScyllaDB is a fast NoSQL database that is commonly used to support high throughput data ingestion processes. ScyllaDB also offers Change Data Capture (CDC) – including for Rust – which is often a helpful feature for data ingestion with data-intensive applications.
Learn more about ScyllaDB’s data ingestion use cases here.