Close-to-the-metal architecture handles millions of OPS with predictable single-digit millisecond latencies.
Learn More 
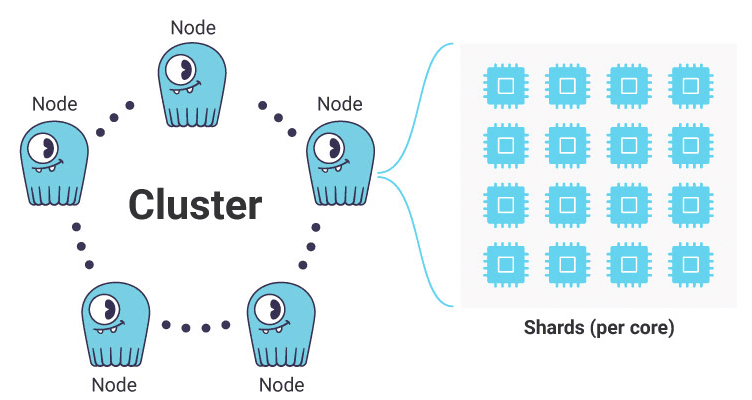
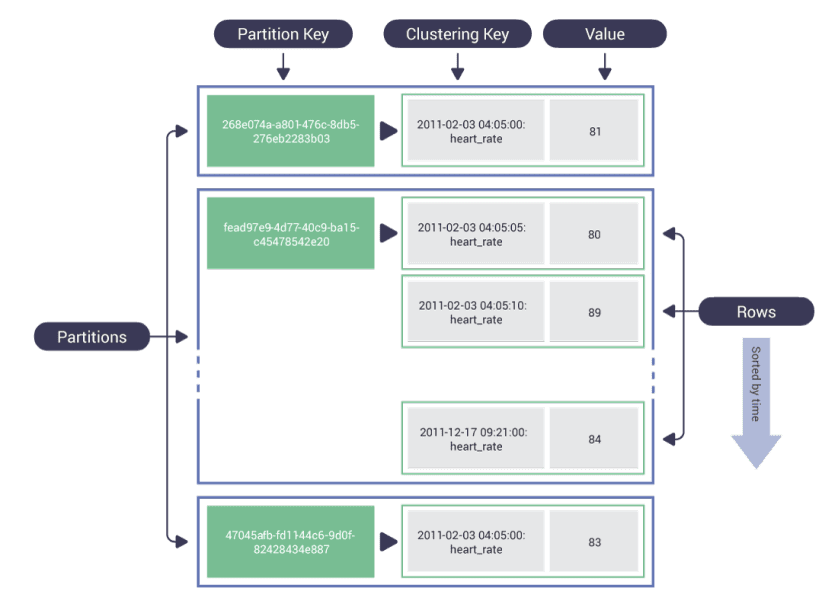
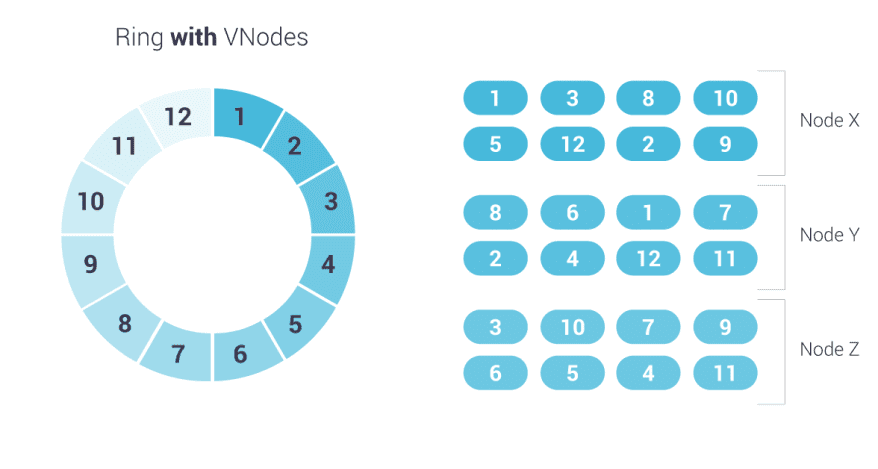
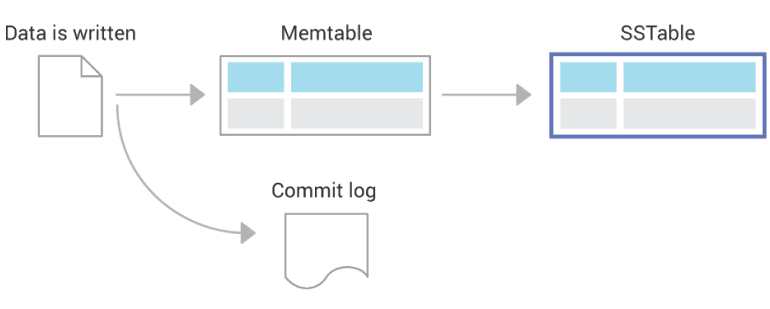
ScyllaDB supports the same CQL commands and drivers and the same persistent SSTable storage format. It uses the same ring architecture and high availability model you’ve come to expect from Cassandra. Find out more
See key differences
Unlike Apache Cassandra, ScyllaDB was written in C++ using the Seastar framework, providing highly asynchronous operations and avoiding Garbage Collection (GC) stalls prevalent in Java. ScyllaDB offers unique features like Incremental Compaction and Workload Prioritization that extend its capabilities beyond Cassandra. Find out more
See key similarities
ScyllaDB supports the same JSON-style queries and same drivers. It runs over the same HTTP/HTTPS style connection. It can even simulate DynamoDB’s schemaless model via a clever use of maps. Find out more
See key difference
With ScyllaDB you are not locked-in to one cloud provider. ScyllaDB can run on any cloud platform or on-premises. And if you want us to run ScyllaDB for you, ScyllaDB Cloud offers a fully managed database as a service (NoSQL DBaaS) solution. You can even run ScyllaDB Cloud on AWS Outposts. Find out more
See key similarities