The ScyllaDB team is pleased to announce the release of ScyllaDB Enterprise 2022.1.0 LTS, a production-ready ScyllaDB Enterprise Long Term Support major release. After more than 6,199 commits originating from five open source releases, we’re excited to now move forward with Scylla Enterprise 2022.
More information on the new ScyllaDB Long Term Support (LTS) policy is available here.
The ScyllaDB Enterprise 2022.1 release is based on ScyllaDB Open Source 5.0, introducing a set of production-ready new features – foremost of which is including support for the AWS EC2 I4i line of servers powered by the 3rd generation of Intel Xeon (“Ice Lake”) processors. ScyllaDB running on I4i servers can provide 2x the performance of comparable I3 series servers. On top of this, the new release provides fundamental optimizations to our IO scheduler, faster performance of reverse queries, and new virtual tables for easier configuration and to access nodetool-level information directly, using the CQL interface.
With the release of ScyllaDB Enterprise 2022.1.0, we will only support users on 2022.x or 2021.x releases. Users running ScyllaDB Enterprise 2020.x and earlier are encouraged to upgrade to one of these two releases.
Related Links
- Read more about ScyllaDB Enterprise here.
- Get ScyllaDB 2022.1 (customers only, or 30-day evaluation)
- Upgrade from 2021.1.x to 2022.1.y
- Upgrade from ScyllaDB Open Source 5.0 to ScyllaDB 2022.1
ScyllaDB Enterprise customers are encouraged to upgrade to ScyllaDB Enterprise 2022.1, and are welcome to contact our Support Team with questions.
Deployment
Safe OS Upgrade for ScyllaDB official image
From now on, every ScyllaDB Image (EC2 AMI, GCP) will include a manifest (text file) of versioned OS packages, tested with the corresponding ScyllaDB release.
This means you can safely upgrade OS packages to a tested version. For example:
cat scylla-packages-2021.1.0-x86_64.txt | sudo xargs -n1 apt-get -y
Note: ScyllaDB Image is now based on Ubuntu 20.04 LTS (see below).
OS and Hardware Support
- The AWS I4i instance types are pre-tuned and supported out of the box. Benchmark results show 2x improvement in throughput compared to the i3 instances on the same number of vCPUs! More detailed benchmarks will be shared soon.
- The AWS Im4gn and Is4gen instance families are now pre-tuned and supported out of the box.
- ScyllaDB Enterprise 2021 Image for AWS, GCP and Docker is based on Ubuntu 20.04. You should now use “scyllaadm” user to login to your instance.
Example:ssh -i your-key-pair.pem scyllaadm@ec2-public-ip - ScyllaDB 2022.1 supports ARM architecture, including:
- EC2 ARM-based AMI, ready for Graviton2
- Running ScyllaDB Docker on ARM, including Mac M1
- Debian 11 and Ubuntu 22 are now supported
- Ubuntu 16.04 and Debian 9, both announced deprecated and are no longer supported.
- Due to a bug in CentOS 8 mdadm, we now pin mdadm’s version to a known-good release. #9540
More Deployments Updates
- Newer Linux distributions use systemd-timesyncd instead of ntp or chrony for time synchronization. This is now supported. ScyllaDB will now detect if you already have time synchronization set up and leave it alone if so. #8339
- scylla_setup script now supports disabling the NVMe write-back cache on disks that allow it. This is useful to reduce latency on Google Cloud Platform local disks. The machine images built using scylla-machine-image will do this automatically.
- The Unified (tarball) Installer now works correctly when SElinux is enabled. #8589
- The installer now offers to set up RAID 5 on the data disks in addition to RAID 0; this is useful when the disks can have read errors, such as on GCP local disks. #9076
- The install script now supports supervisord in addition to systemd. This was brought in from the container image, where systemd is not available, and is useful in some situations where root access is not available.
- Automatic I/O configuration during setup now supports AWS ARM instances.#9493
- The setup utility now recognizes Persistent Disks on Google Cloud Platform and Azure. PR#9395 PR#9417
- Support Microsoft Azure snitch #8593
- ScyllaDB Enterprise Image (based on Ubuntu 20.04)
- Disables default upgrades
- Improves start time by moving 3rd party packages installation from the start up time, to image creation time
- Cloud Formation for ScyllaDB Enterprise
New Features in 2022.1
New I/O Scheduler
A new I/O scheduler measures and uses more granular storage properties to optimize and create a better balance between ScyllaDB IO queues.
ScyllaDB keeps a matrix of relevant combinations of the storage properties:
- write/read bandwidth (bytes per second)
- write/read IOPS (ops per second)
This matrix is part of the ScyllaDB cloud image (for example, AMI for AWS), or generated at setup.
The results are used as an input for the real-time I/O scheduler.
This new I/O scheduler brings significant improvement and further reduces the effect of admin operations like repair or scale-out on online request latency.
For more information, see Linux Foundation recorded webinar Understanding Storage I/O Under Load with Avi Kivity and Pavel “Xemul” Emelyanov and recently released blog post with much more details and results.
Virtual Table for Configuration
A new virtual table, system.config, allows querying and updating configuration over CQL.
Note that only a subset of the configuration parameters can be updated.
Note these updates are not persistent, and will be reverted to the scylla.yaml values in case the ScyllaDB server restarts.
Virtual Tables for Retrieving nodetool-level Information
Several virtual tables have been added for providing information usually obtained via nodetool:
- system.snapshots – replacement for nodetool listsnapshots;
- system.protocol_servers – replacement for nodetool statusbinary as well as Thrift active and Native Transport active from nodetool info;
- system.runtime_info – replacement for nodetool info; but not an exact match: some fields were removed and some were refactored to make sense for scylla;
- system.versions – replacement for nodetool version, prints all versions, including build-id;
Unlike nodetool, which is blocked for remote access by default, virtual tables allow remote access over CQL, including for ScyllaDB Cloud users.
For information about available virtual tables, see here
Repair-Based Node Operations (RBNO)
Repair-Based Node Operations were introduced as an experimental feature in ScyllaDB 4.0, which uses repair to stream data for node operations like replace, bootstrap, and others. In ScyllaDB Enterprise 2022.1, RBNO is enabled by default only for replace node and is no longer experimental. #8013 PR#9197
Our row-level repair mechanism is oriented towards moving small amounts of data, not an entire node’s worth. This resulted in many sstables being created in the node, creating a large compaction load. To fix that, offstrategy compaction is now used to efficiently compact these sstables with reduced impact on the primary workload. #5226
Other RBNO capabilities, such as repair, bootstrap and others are still considered experimental and are thus not supported in ScyllaDB Enterprise; we continue to improve this feature.
For more about “Repair Based Node Operations” see the ScyllaDB Summit 2022 session by Asias He
Service Level Properties
Service Levels allows the user to attach attributes to Roles and Users. These attributes apply to each session the user opens to ScyllaDB, enabling granular control of the session properties, like timeout and load-shedding (overload handling). See Workload Prioritization for more details.
In this release, service levels are enhanced with two features:
- Per service level timeouts
- Workload types
For more information, see the ScyllaDB Summit 2022 session by Eliran Sinvani
In addition, a separate semaphore for each workload is introduced. This improves workload isolation, so a lower priority workload cannot overtake higher priority workloads.
Per Service Level Timeouts
You can now create service levels with customized read and write timeouts and attach them to rules and users. This is useful when some workloads, like ETL, are less sensitive to latency than others.
For example:
CREATE SERVICE LEVEL sl2 WITH timeout = 500ms;
ATTACH SERVICE LEVEL sl2 TO scylla;
ALTER SERVICE LEVEL sl2 WITH timeout = null;
Workload Types
It’s possible to declare a workload type for a service level, currently out of three available values:
- unspecified – generic workload without any specific characteristics; default
- interactive – workload sensitive to latency, expected to have high/unbounded concurrency, with dynamic characteristics, OLTP; example: users clicking on a website and generating events with their clicks
- batch – workload for processing large amounts of data, not sensitive to latency, expected to have fixed concurrency, OLAP, ETL; example: processing billions of historical sales records to generate useful statistics
Declaring a workload type provides more context for ScyllaDB to decide how to handle the sessions. For instance, if a coordinator node receives requests with a rate higher than it can handle, it will make different decisions depending on the declared workload type:
- For batch workloads it makes sense to apply back pressure – the concurrency is assumed to be fixed, so delaying a reply will likely also reduce the rate at which new requests are sent;
- For interactive workloads, backpressure would only waste resources – delaying a reply does not decrease the rate of incoming requests, so it’s reasonable for the coordinator to start shedding surplus requests.
Example
ALTER SERVICE LEVEL sl WITH workload_type = 'interactive';
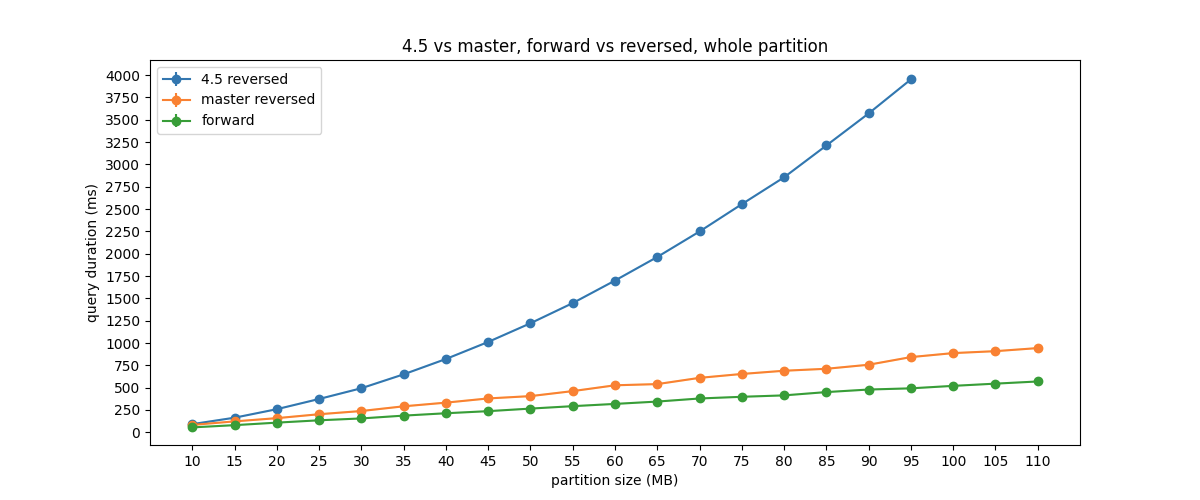
Reverse Queries
A reverse query is a SELECT query that uses a reverse order compared to the one used in the table schema. For example, the following table schema orders the rows in a partition by “time” in ascending order:
CREATE TABLE heartrate (
pet_chip_id uuid,
owner uuid,
time timestamp,
heart_rate int,
PRIMARY KEY (pet_chip_id, time)
);The following SELECT query worked in ScyllaDB Enterprise 2021.1 but could have been very inefficient:
SELECT * FROM heartrate LIMIT 1 ORDER BY time DESC
Note that if the primary key uses multiple columns in mixed order (some are ascending and some are descending), the reverse order needs to invert the sorting order of all clustering columns participating in the primary key.
The following diagram shows the performance improvement of Reverse Queries between 2021.1 and 2022.1.
While in 2021.1, the query time grew quadratically with the size of the partition, in 2022.1 the time is linear, almost as good as a forward query.
SSTable Index Caching
Up to this release, ScyllaDB only cached data from sstables.
As a result, if the data was not in cache readers had to read from disk while walking the index. This was inefficient, especially for large partitions, increasing the load on the disk, and adding latency.
In ScyllaDB 4.6, index blocks can be cached in memory, between readers, populated on access, and evicted on memory pressure – reducing the IO and decreasing latency. #7079
More info in Tomasz Grabiec’s session from ScyllaDB Summit “SSTable Index Caching”
Security Related Updates
- There is now support for a certificate revocation list for TLS encrypted connections. This makes it possible to deny a client with a compromised certificate. #9630
- The default Prometheus listener address is now localhost. Note that you may need to update this configuration item to expose the Prometheus port to your collector. #8757
- The recently-changed Prometheus listen address configuration has been refined. ScyllaDB will now bind to the same host as the internal RPC address if not configured. This will reduce misconfigurations during upgrades, as typically configuration will not require any changes. See #8757 above #9701
- Thrift listen port (start_rpc) is disabled by default, as it is not often used. Thrift is still fully supported. #8336
ScyllaDB Enterprise 2021.1.2 introduced support for LDAP Authorization and LDAP Authentication.
LDAP Authentication and Authorization
- LDAP Authentication allows users to manage the list of ScyllaDB Enterprise users and passwords in an external Directory Service (LDAP server), for example, MS Active Directory. ScyllaDB leverages authentication by a third-party utility named saslauthd to handle authentication, which, in turn, supports many different authentication mechanisms.Read the complete documentation on how to configure and use saslauthd and LDAP Authentication
- LDAP Authorization allows users to manage the roles and privileges of ScyllaDB users in an external Directory Service (LDAP server), for example, MS Active Directory. To do that, one needs a role_manager entry in scylla.yaml set to com.scylladb.auth.LDAPRoleManager. When this role manager is chosen, ScyllaDB forbids GRANT and REVOKE role statements (CQL commands) as all users get their roles from the contents of the LDAP directory.When LDAP Authorization is enabled and a ScyllaDB user authenticates to ScyllaDB, a query is sent to the LDAP server, whose response sets the user’s roles for that login session. The user keeps the granted roles until logout; any subsequent changes to the LDAP directory are only effective at the user’s next login to ScyllaDB.Read the complete documentation on how to configure and use LDAP Authorization
Change Data Capture (CDC)
Change Data Capture (CDC) allows users to track data updates in their ScyllaDB database. While it is similar to the feature with the same name in Apache Cassandra and other databases, the way it is implemented in ScyllaDB is unique, more accessible, and more powerful.
With ScyllaDB’s CDC, you can choose to keep track of the updates, original values and/or new values. The data is stored in regular ScyllaDB tables (SSTables) and can be queried asynchronously using a standard ScyllaDB/Cassandra CQL driver. Data in a CDC table is set with a TTL, minimizing the possibility of an overflow.
A common use case for CDC is using it as a source to a Kafka stream. This is now easy with the Kafka CDC Source Connector.
Writing your own CDC consumer? You can use the example libraries in Go and Java
Example: creating a table with CDC for delta and preimage:
CREATE TABLE base_table (
pk text,
ck text,
val1 text,
val2 text,
PRIMARY KEY (pk, ck)
) WITH cdc = { 'enabled': 'true', 'preimage': 'true' };More information:
- Using Change Data Capture (CDC) in ScyllaDB
- ScyllaDB CDC documentation
- ScyllaDB CDC lesson in ScyllaDB University
- ScyllaDB CDC on-demand webinar
CQL Extensions
Timeout per Operation
There is now new syntax for setting timeouts for individual queries with “USING TIMEOUT”. #7777
This is particularly useful when one has queries that are known to take a long time. Till now, you could either increase the timeout value for the entire system (with request_timeout_in_ms), or keep it low and see many timeouts for the longer queries. The new Timeout per Operation allows you to define the timeout in a more granular way. Conversely, some queries might have tight latency requirements, in which case it makes sense to set their timeout to a small value. Such queries would get time out faster, which means that they won’t needlessly hold the server’s resources.
You can use the new TIMEOUT parameters for both queries (SELECT) and updates (INSERT, UPDATE, DELETE).
Examples:
SELECT * FROM t USING TIMEOUT 200ms;
INSERT INTO t(a,b,c) VALUES (1,2,3) USING TIMESTAMP 42 AND TIMEOUT 50ms;
Working with prepared statements works as usual — the timeout parameter can be explicitly defined or provided as a marker:
SELECT * FROM t USING TIMEOUT ?;
INSERT INTO t(a,b,c) VALUES (?,?,?) USING TIMESTAMP 42 AND TIMEOUT 50ms;
- One can now omit irrelevant clustering key columns from ORDER BY clauses.
You can now replaceSELECT * FROM t WHERE p = 0 AND c1 = 0 ORDER BY (c1 ASC, c2 ASC)With the shorterSELECT * FROM t WHERE p = 0 AND c1 = 0 ORDER BY (c2 ASC)
More CQL Updates
- It is now possible to ALTER some properties of system tables, for example update the speculative_retry for the system_auth.roles table #7057ScyllaDB will still prevent you from deleting columns that are needed for its operation, but will allow you to adjust other properties.
- The removenode operation has been made safe. ScyllaDB will now collect and merge data from the other nodes to preserve consistency with quorum queries.
- Lightweight (fast) slow-queries logging mode. New, low overhead tracing facility for slow queries.When enabled, it will work in the same way slow query tracing does besides that it will omit recording all the tracing events. So that it will not populate data to the system_traces.events table but it will populate trace session records for slow queries to all the rest:
system_traces.sessions,system_traces.node_slow_log, etc. #2572More here SELECTstatements that used an index, and also restricted the token (e.g.SELECT ... WHERE some_indexed_column = ? AND token(pk) = ?) incorrectly ignored the token restriction. The issue was found by using spark connector filtering on a secondary index. This is now fixed. #7043- Selecting a partition range with a slice/equality restriction on clustering keys (e.g.
SELECT * FROM tab WHERE ck=?, with no partition key restrictions) now demandsALLOW FILTERINGagain (since this query can potentially discard large amounts of data without returning anything). To avoid breaking applications that accidentally did not specifyALLOW FILTERING, it will only generate a warning for now. #7608 - ScyllaDB now correctly rejects CQL insert/update statements with
NULLs in key columns. #7852 - Queries that are performed using an index can now select Static Columns. #8869
Alternator
Alternator, ScyllaDB’s implementation of the DynamoDB API, now provides the following improvements:
- Nested attribute paths in all expressions #8066
- Supports
DELETEoperations that remove an element from a set. #5864 - Added missing support for
UpdateItem DELETEoperation with value parameter #5864 - Avoid large allocations while streaming. A similar change was made to the
BatchGetItemsAPI. This reduces latency spikes. #8522 - Deleting a nested path with non-existent leaf should work #10043
- Query with
ScanIndexForward = falseis inefficient and limited to 100MB #7586 - Stream JSON response object – not convert it to a contiguous string #8522
- Support for Cross-Origin Resource Sharing (CORS). This allows client browsers to access the database directly via JavaScript, avoiding the middle tier. #8025
- Support limiting the number of concurrent requests with a scylla.yaml configuration value
max_concurrent_requests_per_shard. In case the limit is crossed, Alternator will returnRequestLimitExceedederror type (compatible with DynamoDB API) #7294 - Alternator, now fully supports nested attribute paths. Nested attribute processing happens when an item’s attribute is itself an object, and an operation modifies just one of the object’s attributes instead of the entire object. #5024 #8043
- Alternator now supports slow query logging capability. Queries that last longer than the specified threshold are logged in `
system_traces.node_slow_log` and traced. #8292
Example trace:
- Alternator was changed to avoid large contiguous allocations for large requests. Instead, the allocation will be broken up into smaller chunks. This reduces stress on the allocator, and therefore latency. #7213
sstableloader now work with Alternator tables #8229 - Support attribute paths in
ConditionExpression,FilterExpression - Support attribute paths in
ProjectionExpression - New metrics:
requests_shed metrics
- Rudimentary implementation of TTL expiration service PR#9624
- ConditionExpression wrong comparison of two non-existent attributes #8511
- Incorrect set equality comparison inside a nested document #8514
- Incorrect inequality check of two sets #8513
- Include username in trace records. #9613
- Supports the
ADDoperation. #5893 - Deleting a nested path with non-existent leaf should work #10043
- Can’t run alternator with both HTTP and HTTPS #10016
Guardrails
We continue to add default limitations (guardrails) to ScyllaDB, making it harder for users to use non production settings by mistake. Each new configuration added to restriction mode (tri_mode_restriction) has three options:
- True: restricted, disable risky feature
- False: non restricted, enable risky feature
- Warn: non restricted, log warning about risky feature
Additions in this release are:
- It’s now possible to prevent users from using SimpleReplicationStrategy, using config parameter
restrict_replication_simplestrategy
The goal is to first default to warning and then default to actual prevention. SimpleReplicationStrategy can make it hard to later grow the cluster by adding data centers. #8586 - DateTieredCompactionStrategy has been deprecated in favor of TimeWindowCompactionStrategy for a long time now. A new warning will let you know if you are still using it. If you are nostalgic for the old strategy, use “
restrict_dtcs” to disable this warning #8914
Hinted Handoff API
Hinted Handoff is an anti-entropy mechanism to replay mutations to a node which was unreachable for some time.
There is a new HTTP API for waiting for hinted handoff replay to be completed. This can be used to reduce repair work.
`/hints_manager/waiting_point`(POST) – Create a sync point: given a set of target hosts, creates a sync point at the end of all HH queues pointing to any of the hosts.`/hints_manager/waiting_point`(GET) – Wait or check the sync point: given a description of a sync point, checks if the sync point was already reached. If you provide a non-zero `timeout` parameter and the sync point is not reached yet, this endpoint will wait until the point reached or the timeout expires.
Tools
Nodetool Scrub
scrub is a nodetool command and a REST API for deserialization and reserializion of sstables to the latest version, resolving corruptions if any) the given keyspace. Scrub has the following modes:
ABORT(default) – abort scrub if corruption is detected;SKIP(same as `skip_corrupted=true`) skip over corrupt data, omitting them from the output;SEGREGATE– segregate data into multiple sstables if needed, such that each sstable contains data with valid order;VALIDATE– read (no rewrite) and validate data, logging any problems found. #7736
The following bugs are fixed in scrub operation:
- Scrub compaction: segregate mode: unbounded number of buckets can cause OOM #9400
- Scrub always segregates, regardless of mode #9541
- Scrub compaction filters out sstables that are being compacted #9256
- Better handling of non-UTF-8 strings of corrupt partition keys to the log
- Don’t purge tombstones in scrub
Active Client Table
System.clients is a CQL table that provides real-time information on CQL clients connected to the ScyllaDB cluster.
In this release, the following columns are added to the clients table:
connection_stage
connection_stagedriver_namedriver_versionprotocol_version
It also improves:
client_type– distinguishes cql from thrift just in caseusername– now it displays the correct username if `PasswordAuthenticator` is configured.
Nodetool Stop
Reshard and reshape start automatically on boot or refresh, if needed. This release supports the new “nodetool stop RESHAPE” command
nodetool stop now supports the following compaction types: COMPACTION, CLEANUP, SCRUB, UPGRADE and RESHAPE For example: nodetool stop SCRUB.
More Tooling and Admin API Updates
- API: There is now a new API to force removal of a node from gossip. This can be used if information about a node lingers in gossip after it is gone. Use with care as it can lead to data loss. #2134
- A new tool scylla-sstable allows you to examine the content of SStables by performing operations such as dumping the content of SStables, generating a histogram, validating the content of SStables, and more.
- The main ScyllaDB executable can now run subtools by supplying a subcommand: scylla sstables and scylla types, to inspect sstables and schema types. Additional commands will be added over time (see scylla-sstable above as an example) #7801
- The scylla tool sub-subcommands have changed from switch form (‘
scylla sstable --validate‘) to subcommand form (‘scylla sstable validate‘). - When the user requests to stop compactions, ScyllaDB will now only stop regular compaction, not user-request compactions like
CLEANUP. - It is now possible to stop compaction on a particular set of tables. #9700
- A replace operation in repair-based-node-operations mode will now ignore dead nodes, allowing the replacement of multiple dead nodes.
- There is now a configuration flag to disable the new reversed reads code, in case an unexpected bug is found after release. PR#9908
- It is now possible to perform a partial repair when a node is missing, by using the new ignore_nodes option. Repair will also detect when a repair range has no live nodes to repair with and short-circuit the operation #7806 #8256
- The Thrift API disable by default. As it is less often used, users might not be aware Thrift is open and might be a security risk. #8336 To enable it, add “
start_rpc: true” to scylla.yaml. In addition, Thrift now have- partial admission control
- support for max_concurrent_requests_per_shard
- counters for in-flight requests and blocked requests
- Nodetool Top Partitions extension. nodetool toppartitions allow you to find the partitions with the highest read and write access in the last time window. Till now,
nodetool toppartitionsonly supported one table at a time. From ScyllaDB 4.5,nodetool toppartitionsallows specifying a list of tables, or keyspaces. #4520 nodetool stopnow supports more compaction types: Supported types are:COMPACTION,CLEANUP,SCRUB,UPGRADE. For example:nodetool stop SCRUB.Note that reshard and reshape start automatically on boot or refresh, if needed. Compaction, Cleanup, Scrub, and Upgrade are started with nodetool command. The others:RESHAPE,RESHARD,VALIDATION,INDEX_BUILDare unsupported bynodetool stop.- scylla_setup option to retry the RAID setup #8174
- New
system/drop_sstable_cachesRESTful API. Evicts objects from caches that reflect sstable content, like the row cache. In the future, it will also drop the page cache and sstable index caches. While exitingBYPASS CACHEaffects the behavior of a given CQL query on per-query basis, this API clears the cache at the time of invocation, later queries will populate it. - REST API: add the compaction id to the response of
GET compaction_manager/compactions - sstablemetadata: add support to inspect sstable using zstd compression #8887
- CQLsh use the ScyllaDB Python Driver instead of the Cassandra driver
- There is now a crawling sstable reader, that does not use the sstable index file. This is useful in scenarios such as scrub, when the index file is suspected to be corrupted.
nodetool scrub- support for new
--modeoptions:ABORT,SKIP,SEGREGATE, orVALIDATE. - deprecate the old
--skip-corrupted. Note that although--skip-corruptedcan still be provided, the user must not specify both--skip-corruptedand--mode.
- support for new
For Nodetool scrub reference see here #7736
nodetool toppartitions– Allow query of multiple tables and keyspaces scylla-tools-java#228, #4520scylla-sstable– a tool which can be used to examine the content of sstable(s) and execute various operations on them. The currently supported operations are:dump– dumps the content of the sstable(s), similar tosstabledump;dump-index– dumps the content of the sstable index(es), replacingscylla-sstable-index;writetime-histogram– generates a histogram of all the timestamps in the sstable(s);custom– a hackable operation for the expert user (until scripting support is implemented);validate– validate the content of the sstable(s) with the mutation fragment stream validator, same as scrub in validate mode;
Performance Optimizations
- Repair works by having the repairing node (“repair master”) merge data from the other nodes (“repair followers”) and write the local differences to each node. Until now, the repair master calculated the difference with each follower independently and so wrote an SSTable corresponding to each follower. This creates additional work for compaction, and is now eliminated as the repair master writes a single SSTable containing all the data. #7525
- When aggregating (for example,
SELECT count(*) FROM tab), ScyllaDB internally fetches pages until it is able to compute a result (in this case, it will need to read the entire table). Previously, each page fetch had its own timeout, starting from the moment the page fetch was initiated. As a result, queries continued to be processed long after the client gave up on them, wasting CPU and I/O bandwidth. This was changed to have a single timeout for all internal page fetches for an aggregation query, limiting the amount of time it can be alive. #1175 - ScyllaDB maintains system tables tracking sstables that have large cells, rows, or partitions for diagnostics purposes. When tracked sstables were deleted, ScyllaDB deleted the records from the system tables. Unfortunately, this uses range tombstones which are not (yet) well supported in ScyllaDB. A series was merged to reduce the number of range tombstones to reduce impact on performance. #7668
- Queries of Time Window Compaction Strategy tables now open sstables in different windows as the query needs them, instead of all at once. This greatly reduces read amplification, as noted in the commit. #6418
- For some time now, ScyllaDB reshards (rearranges sstables to contain data for one shard) on boot. This means we can stop considering multi-shard sstables in compaction, as done here. This speeds up compaction a little. A similar change was done to cleanup compactions. #7748
- During bootstrap, decommission, compaction, and reshape ScyllaDB will separate data belonging to different windows (in Time Window Compaction Strategy) into different sstables (to preserve the compaction strategy invariant). However, it did not do so for memtable flush, requiring a reshape if the node was restarted. It will now flush a single memtable into multiple sstables, if needed. #4617
The following updates eliminate latency spikes:
- Large sstables with many small partitions often require large bloom filters. The allocation for the bloom filters has been changed to allocate the memory in steps, reducing the chance of a reactor stall. #6974
- The token_metadata structure describes how tokens are distributed across the cluster. Since each node has 256 tokens, this structure can grow quite large, and updating it can take time, causing reactor stalls and high latency. It is now updated by copying it in the background, performing the change, and swapping the new variant into the place of the old one atomically. #7220 #7313
- A cleanup compaction removes data that the node no longer owns (after adding another node, for example) from sstables and cache. Computing the token ranges that need to be removed from cache could take a long time and stall, causing latency spikes. This is now fixed. #7674
When deserializing values sent from the client, ScyllaDB will no longer allocate contiguous space for this work. This reduces allocator pressure and latency when dealing with megabyte-class values. #6138 - Continuing improvement of large blob support, we now no longer require contiguous memory when serializing values for the native transport, in response to client queries. Similarly, validating client bind parameters also no longer requires contiguous memory. #6138
- The memtable flush process was made more preemptible, reducing the probability of a reactor stall. #7885
- Large allocation in
mutation_partition_view::rows()#7918 - Potential reactor stall on LCS compaction completion #7758
- Seastar has disabled Nagle’s algorithm for the http server, preventing 40ms latency spikes. #9619
- XFS filesystems created by scylla_setup now have online discard enabled. This can improve SSD performance. Upgrades should consider manually adding online discard, providing they run a recent kernel. #9608
- ScyllaDB precalculates replication maps (these contain information about which replicas each token maps to). We now share replication maps among keyspaces with similar configuration, to save memory and time.
- ScyllaDB will now compact memtables when flushing them into sstables. This results in smaller sstables in delete-heavy workloads. Memtable compaction is automatically disabled when there are no relevant tombstones in the memtable. #7983
- The internal cache used for (among other things) prepared statements now has pollution resistance. This means that a workload that uses unprepared statements will not interfere with a workload that properly prepares and reuses its statements. #8674 #9590
- Leveled compaction strategy (LCS) will now be less aggressive in promoting sstables to higher levels, reducing write amplification.
- Data in memtables is now considered when purging tombstones. While it’s very unlikely to have data in memtable that is older than a tombstone in an sstable, it’s still better to protect against it. #1745
- When using Time Window Compaction Strategy (TWCS), ScyllaDB will now compact tombstones across buckets, so they can remove the deleted data. Note that using DELETE with TWCS is still not recommended. #9662
- Time window compaction strategy (TWCS) major compactions will now serialize behind other compactions, in order to to include all sstables in the compaction input set. #9553
- Repair will now prefer closer nodes for pulling in missing data, when there is a choice. This reduces cross-datacenter traffic. PR#9769
- ScyllaDB performs a reshape compaction to bring sstables into the structure required by the compaction strategy, for example after a repair. It will now require less free space while doing so.
- Reshape of Time Window Compaction Strategy (TWCS) now tries to compact sstables of similar size, like Size Tiered Compaction Strategy, to reduce reshape time. This helps reduce reshape time if one accidentally creates tiny time windows and then has to increase them dramatically to avoid an explosion in sstable counts.
- Generally, if a node finds it needs to reshape sstables while starting up, it will remain offline while doing so, in order to reduce read amplification. However, for the case of repair sstables, remaining offline can be avoided and the node can start up immediately. #9895
- Improve
flat_mutation_reader::consume_pausable#8359. Combined reader microbenchmark has shown from 2% to 22% improvement in median execution time while memtable microbenchmark has shown from 3.6% to 7.8% improvement in median execution time. - Significant write amplification when reshaping level 0 in a LCS table #8345
- The Log-Structured Allocator (LSA) is the underlying memory allocator behind ScyllaDB’s cache and memtables. When memory runs out, it is called to evict objects from cache, and to defragment free memory, in order to serve new allocation requests. If memory was especially fragmented, or if the allocation request was large, this could take a long while, causing a latency spike. To combat this, a new background reclaim service is added which evicts and defragments memory ahead of time and maintains a watermark of free, non-fragmented memory from which allocations can be satisfied quickly. This is somewhat similar to kswapd on Linux. #1634
- To store cells in rows, ScyllaDB used a combination of a vector (for short rows) and red-black tree (for wide rows), switching between the representations dynamically. The red-black is inefficient in memory footprint when many cells are present, so the data storage now uses a radix tree exclusively. This both reduces the memory footprint and also improves efficiency.
- sstables: Share partition index pages between readers. Before this patch, each index reader had its own cache of partition index pages. Now there is a shared cache, owned by the sstable object. This allows concurrent reads to share partition index pages and thus reduce the amount of I/O. For IO-bound, we needed 2 I/O per read before, and 1 (amortized) now. The throughput is ~70% higher. More here.
- Switch partition rows onto B-tree. The data type for storing rows inside a partition was changed from a red-black tree to a B-tree. This saves space and spares some cpu cycles. More here.
The sstable reader will now allow preemption at row granularity; previously, sstables containing many small rows could cause small latency spikes as the reader would only preempt when an 8k buffer was filled. #7883 - Streams of mutation data are represented in ScyllaDB by a
flat_mutation_reader, which provides a means for a function to consume a stream. This was made faster, which improves operations such as flushing a memtable. See PR#8359 for micro benchmark results. - When ScyllaDB receives sstables from outside the replica (such as via a repair operation, or after restoring a snapshot) it first reshapes them to conform to the compaction strategy.
Reshape was improved for:- Leveled Compaction Strategy, by checking first if the sstables happen to be disjoint.
- Time Window Compaction Strategy, by reducing write amplification.
- More code paths can now work with non-contiguous memory for table columns and intermediate values: comparing values, the CQL write path. This reduces CPU stalls due to memory allocation when large blobs are present. PR#8357
- SSTable parser will avoid large allocations, reducing latency spikes. #6376, #7457
- Repair is now delayed until hints for that table are replayed. This reduces the amount of work that repair has to do, since hint replay can fill in the gaps that a downed node misses in the data set. #8102
- SSTables will now automatically choose a buffer size that is compatible with achieving good latency, based on disk measurements by iotune.
- The setup scripts will now format the filesystem with 1024 byte blocks if possible. This reduces write amplification for lightweight transaction (LWT) workloads.
- Performance: read latency increase after deletion of high percentage of the data, as many rows covered by a single range tombstone, which go through row cache are very slow #8626
- Authentication had a 15 second delay, working around dependency problems. But it is long unneeded and is now removed, speeding up node start.
- Unintended quadratic behavior in the log-structured allocator (which manages ScyllaDB memtable and cache memory) has been fixed. #8542
- Off-strategy compaction is now enabled for repair. After repair completes, the sstables generated by repair will first be merged together, then incorporated into the set of sstables used for serving data. This reduces read amplification due to the large number of sstables that repair can generate, especially for range queries where the bloom filter cannot exclude those sstables. #8677
- Off-strategy compaction, a method by which sstables are reshaped to fit the compaction strategy, is now enabled for bootstrap and replace operation using standard streaming. #8820
- The read path has been optimized to remove unnecessary work, leading to a small performance increase.
- The common case of single-partition query was treated as an IN query with a 1-element tuple. This case is now specialized to avoid the extra post-processing work.
- SSTable index files are now cached, both at the page level and at an object level (index entry). This improves large partition workloads as well as intermediate size workloads where the entire sstable index can be cached. #7079
- The row cache behavior was quadratic in certain cases where many range tombstones were present. This has been fixed. #2581
- Recently the sstable index has gained the ability to use the cache to reduce I/O; but it did so even when
BYPASS CACHEwas requested in the CQL statement. The index now respectsBYPASS CACHElike data access. - After adding a node, a cleanup process is run to remove data that was “moved” to the new node. This is a compaction process that compacts only one sstable at a time. This fact was used to optimize cleanup. In addition, the check for whether a partition should be removed during cleanup was also improved. #6807
- ScyllaDB uses reader objects to read sequential data. It caches those readers so they can be reused across multiple pages of the result set, eliminating the overhead of starting a new sequential read each time. However, this optimization was missed for internal paging used to implement aggregations (e.g.
SUM(column)). ScyllaDB now uses the optimization for aggregates too. #9127 - There is now an effective replication map structure, which contains the application of a replication strategy and its parameters to a topology (node → token mapping). This reduces the amount of run-time computation needed by the coordinator.
- Time Window Compaction strategy reshape gained two optimizations. Reshape happens when changing compaction strategies or after streaming data to a new node. The optimizations reduce write amplification and therefore the time spent when adding a new node.
- In Time Window Compaction Strategy compactions, fully expired sstables will be compacted separately, since that can be done by just dropping them. #9533
- Scrub compaction, which re-sorts unsorted sstables, will now use memtables as a sorting mechanism instead of generating many small sstables. PR#9548
- Usually a memtable is flushed into one sstable. In some cases, however, it can be flushed into several sstables. We now adjust the partition estimate for these sstables so the bloom filters allocated by these sstables will not occupy too much memory. #9581
- Size-tiered compaction strategy will prefer compactions with larger fan-in in order to improve efficiency. Moreover, once a compaction with large fan-in is started, compactions with lower fan-in will be delayed in order to improve overall write amplification.
- Major compaction will now process tables from smallest to largest, to increase the probability of success in case the node is running low on space.
- Zap dummy cache entries when populating or reading a range. See #8153
Configuration
- Hinted handoff configuration can now be changed without restart. #5634
- Ignore
enable_sstables_mc_format: User can no longer disable MC format for older SSTable formats. experimental– deprecated. The flag used to enable all experimental features, which is not very useful. Instead, you should enable experimental features one by one. Experimental feature in this release include these possible values: ‘lwt‘, ‘cdc‘, ‘udf‘, ‘alternator-streams‘, ‘raft‘ #9467enable_sstables_mc_format: parameter is now ignored; mc or md format is mandatory. ScyllaDB continues to be able to read older ka and la format sstables. #8352batch_size_warn_threshold_in_kb: from 5 to 128,batch_size_fail_threshold_in_kb: from 50 to 1024
The batch size warning and failure thresholds have been increased to 128 kiB and 1 MiB respectively. The original limits (5 and 50 kiB) were unnecessarily restrictive. #8416max_hinted_handoff_concurrency:: when a node is down, writes to that node are collected in hint files. When the node rejoins, hint files are replayed. It turned out that hint replay was too fast and interfered with the normal workload, so its concurrency was reduced and made configurable.restrict_dtcs(false): Disable DateTieredCompactionStrategy usage. See Guardrails section above for more informationreversed_reads_auto_bypass_cache(true): Use new implementation of reversed reads in sstables when performing reversed queriesreplace_nodeandreplace_tokenwere ignored, and node removedflush_schema_tables_after_modification(true): Flush tables in thesystem_schemakeyspace after schema modification. This is required for crash recovery, but slows down tests and can be disabled for themstrict_allow_filtering(warn): Match Cassandra in requiringALLOW FILTERINGon slow queries. Can betrue,false, orwarn. Whenfalse, ScyllaDB accepts some slow queries even withoutALLOW FILTERINGthat Cassandra rejects.Warnis the same asfalse, but with warning.commitlog_use_hard_size_limit(false): Whether or not to use a hard size limit for commitlog disk usage. Default isfalse. Enabling this can cause latency spikes, whereas the default can lead to occasional disk usage peaks.enable_repair_based_node_ops(true): Settrueto use enable repair based node operations instead of streaming based (more on RBNO above)allowed_repair_based_node_ops(replace): A comma separated list of node operations which are allowed to enable repair based node operations. The operations can bebootstrap,replace,removenode,decommissionandrebuild(more on RBNO above)sanitizer_report_backtrace(false): In debug mode, report log-structured allocator sanitizer violations with a backtrace. Do not use this in production, as it can slow ScyllaDB significantly.restrict_replication_simplestrategy(false): see restricted abovefailure_detector_timeout_in_ms(20,000ms): Maximum time between two successful echo message before gossip marks a node down in millisecondswait_for_hint_replay_before_repair(true): If set totrue, the cluster will first wait until the cluster sends its hints towards the nodes participating in repair before proceeding with the repair itself. This reduces the amount of data needed to be transferred during repair.
Monitoring
The ScyllaDB Enterprise 2022.1.0 Dashboard is available with ScyllaDB Monitoring Stack 4.0 or later
- For new metrics compare to ScyllaDB Enterprise 2021.1 see here
- For new metrics compare to ScyllaDB Open Source 5.0 see here
Stability and Bug Fixes
Partial list. For a full list of updates, see release notes for ScyllaDB 5.0, 4.6, 4.5 and 4.4
- A bug where incorrect results were returned from queries that use an index was fixed. The bug was triggered when large page sizes were used, and the primary key columns were also large, so that the page size multiplied by the key size exceeded a megabyte. #9198
- ScyllaDB implements upgrades by having nodes negotiate “features” and only enabling those features when all nodes support them. The negotiated features are now persistent to disallow some illegal downgrades.
- An exception safety problem leading to a crash when inserting data to memtables was fixed. #9728
- A crash in ScyllaDB memory management code, triggered by index file caching, was fixed. The bug was caused by an allocation from within the memory allocator causing cache eviction in order to free memory. Freeing the evicted items re-enters the memory allocator, in a way that was not expected by the code. Fixes #9821 #9192 #9825 #9544 #9508 #9573
- The
INSERT JSONstatement now correctly rejects empty string partition keys. #9853 - Change Data Capture (CDC) preimage now works correctly for
COMPACT STORAGEtables. #9876 - Performance: Cleanup compaction / rewrite sstable block behind regular compaction for each sstable #10175. This fix replaces the earlier reverted fix for #10060, which was not complete.
- Stability: a bug in LSA allocator might cause a Coredump, for example after snapshot operations #10056
- Build: compilation error on Fedora 34 with recent libstdc++ #10079
- Docker: previous versions of Docker image run scylla as root. A regression introduced in 4.6 accidentally modified it to scylla user. #10261
- Docker: Incompatible change of supervisor service name inside ScyllaDB container image #10269
- Docker: incorrect locale value in docker build script #10310
- Docker: ScyllaDB Docker doesn’t have pidof, required by seastar-cpu-map.sh #10238
- Fix a regression induce in 5.0rc0:
range_tombstone_list: insert_from: incorrectrange_tombstoneapplied to reverter in non-overlapping case #10326 - CQL: Incorrect results returned with
INclause in a partition and index restriction andALLOW FILTERING#10300 - Stability:
compare_atomic_cell_for_mergedoesn’t compare TTL if expiry is the same. This is not consistent with the way the cell hash is computed, and may cause repair to keep trying to repair discrepancies caused by the ttl being different. #10156, #10173 - Stability: A crash in ScyllaDB memory management code, triggered by index file caching, was fixed. The bug was caused by an allocation from within the memory allocator causing cache eviction in order to free memory. Freeing the evicted items re-enters the memory allocator, in a way that was not expected by the code. Fixes #9573
- Stability: JSON formatter issues may cause API calls fail in some cases, for example top partition on a CDC table #9061
- Seastar: Intensive mixed (e.g. compaction + query) IO could sporadically break through the configured limitations causing the disk to be overloaded which would result in increased IO latencies #10233
- Stability: Truncating a table during memtable flush might trigger an assert failure in
~flush_memory_accounter#10423 - Stability: Compaction manager error: “
bad_optional_access (bad optional access): retrying” when triggering maintenance compaction after disable autocompaction #10378 - Stability: A wrong auth opcode, for example, a driver bug, might crashes node #10487
- Stability: Prepared statements cache: Batch statements don’t get invalidated when it appears that they should. #10129
- Stability: OOM on memtable flush causes ScyllaDB to abort #10027
- cdc: dropping a column from the base table does not update system_schema.dropped_columns for the CDC log table, preventing queries from CDC log sstables which contain this column #10473
- Regression: batch with prepared stmts can cause (Java) driver to infinite loop re-preparing #10440
- Stability:
prepared_statements_cache/loading_cacheload vs invalidate race can result in stale prepared statements #10117 - Stability:
database::drop_column_family(): has a window where new queries can be created for the dropped cf #10450 - Stability: nodetool complains about malformed ipv6 addresses #10442
- “Could not create SSTable component” exceptions while ScyllaDB service is down #10218
- Stability: system.config table is not usable for inquiring
experimental_featuressetting #10047 - Stability:
managed_chunked_vectorcrashes in certain cases ifreserve()is called twice without the reservation being consumed #10364 - Stability:
chunked_vectorcrashes in certain cases ifreserve()is called twice without the reservation being consumed #10363 - UX: Unreadable error response in a large partition test case #5610
- Stability: Segmentation fault in
sstables::partition_index_cache::get_or_load, after upgrade to 4.6 - Crashes in sstable reader which touch sstables which have partition index pages with more than 1638 partition entries. Introduced in 4.6.0 #10290
- Docker: ScyllaDB container image stopped logging to stdout #10270
- Stability: Seastar: some counters need to be reported as floating point numbers. https://github.com/scylladb/scylla-seastar/commit/6745a43c10d5df4ab90519fdc499964443246c72
- Stability: Messaging: default tenants (user and system queries) are not isolated. As a result one node latency might increase a peer node latency #9505
- Stability: Too many open files during terminate and replace node (scale test) #10462
- Stability: Alternator – AWS Terraform API for Alternator fails to create table #10660
- Setup:
scylla_sysconfig_setup: does not able to handle ≥32 CPUs cpuset correctly #10523 - Setup: scylla image setup fails with
ValueError, cause by a warning return from perftune.py #10082 - Storage: files created by ScyllaDB ignore XFS project inheritance bit #10667
- REST API major compaction request stuck for 30 minutes and don’t get response from scylla. #10485
- Stability: Abort on
bad_allocduring page loading #10617 - Performance: write only workload which is throttled and uses only 20-30% CPU can’t be sustained #10704
- Stability: coredump when calling
describe_ringand a node is being shut down #10592 - Thrift now has partial admission control, to reduce the chance of server overload.
- A recent regression caused requests to data centers where the local replication factor is zero to crash. This is now fixed. #8354
- A bug in Time Window Compaction Strategy’s selection of sstables for single-partition reads caused sstables that did not have data for the key to be consulted, reducing performance. This is now fixed. #8415
- Continuing on the path of allowing non-contiguous allocations for large blobs, memory linearizations have been removed from Change Data Capture (CDC). This reduces CPU stalls when CDC is used in conjunction with large blobs. #7506
- The underlying json parser used by alternator, rapidjson, has been hardened against out-of-memory errors. #8521
- A bug in the row cache that can cause large stalls on schemas with no clustering key has been fixed.
- ScyllaDB uses a log-structured memory allocator (LSA) for memtable and cache. Recently, unintentional quadratic behavior in LSA was discovered, so as a workaround the memory reserve size is decreased. Since the quadratic cost is in terms of this reserve size, the bad behavior is eliminated. Note the reserves will automatically grow if the workload really needs them. #8542
- Repair allocates working memory for holding table rows, but did not consider memory bloat and could over-allocate memory. It is now more careful. #8641
- Failure detection is now done directly by nodes pinging each other rather than through the gossip protocol. This is more reliable and the information is available more rapidly. Impact on networking is low, since ScyllaDB implements a fully connected mesh in all clusters smaller than 256 nodes per datacenter, much larger than the typical cluster. #8488
- Change Data Capture (CDC) uses a new internal table for maintaining the stream identifiers. The new table works better with large clusters. #7961
- ScyllaDB will now close the connection when a too-large request arrives; previously ScyllaDB would read and discard the request. The new behavior protects against having to read and discard potentially gigabytes of data. #8798
- A
SELECTstatement could result in unbounded concurrency (leading to an out-of-memory error) in some circumstances; this is now fixed. #8799 - Speculative retry will now no longer consider failed responses when calculating the 99th percentile of a request. Considering them leads to the latency threshold being continuously raised, since failed (timed out) requests have very long latency; so the effectiveness of the feature is much reduced. Now it will only consider successful responses. #3746 #7342
- The bootstrap process was made more robust over failures to communicate the token ranges to the new node. Such problems will be resolved more fully with Raft. #8889
- A regression in how ScyllaDB computes compaction backlog has been fixed. Compaction backlog estimates the total number of bytes that remain to be compacted (which can be greater than the table size due to write amplification). ScyllaDB then uses the backlog to decide how to allocate resources to compaction. The bug caused the backlog to be overestimated, thus devoting too many resources (CPU and disk bandwidth) to compaction #8768
- Logging of corrupted sstables has been improved to report the file name and offset of the corrupted chunk.
- A problem with
COMPACT STORAGEtables representation in Change Data Capture has been corrected. #8410 - The reader concurrency semaphore is ScyllaDB’s main replica-side admission control mechanism. It tracks query memory usage and timeouts, and delays or rejects queries that will overload memory. Previously, it was engaged only on a cache miss. It is now engaged before the cache is accessed. This prevents some cache intensive workloads from overloading memory. These workloads typically have queries that take a long time to execute and consume a lot of memory, even from cache, so their concurrency needs to be limited. #4758 #5718
- A limitation of 10,000 connections per shard has been lifted to 50,000 connections per shard, and made tunable with max-networking-io-control-blocks seastar config. #9051
- The
currenttime()and related functions were incorrectly marked as deterministic. This could lead to incorrect results in prepared statements. They are now marked as non-deterministic. #8816 - If ScyllaDB stalls while reclaiming memory, it will now log memory-related diagnostics so it is easier to understand the root cause.
- Repair now reads data with a very long timeout (instead of infinite timeout). This is a last-resort defense against internal deadlocks. #5359
- The cache abstraction that is used to implement the prepared statement cache has been made more robust, eliminating cases where the entry expired prematurely. #8920
- When streaming data from a Time Window Compaction Strategy table, ScyllaDB segregates the data into the correct time window to follow the compaction strategy rules. This however causes a large number of sstables to be created, overloading the node in extreme cases. We now postpone data segregation to a later phase, off strategy compaction, which happens after the number of sstables has been reduced. #9199
Scrub compactions no longer purge tombstones. This is in order to give a tombstone hiding in a corrupted sstable the chance to get compacted with data. - Scrub compactions are now serialized with regard to other compactions, to prevent an sstable undergoing compaction from not being scrubbed. #9256
- The CQL protocol server now responds with an overloaded exception if it decides to shed requests. This avoids a resource leak at the client driver side, when the driver may be waiting for the response indefinitely. #9442
- A scrub compaction takes an sstable with corruption problems and splits it into non-corrupted sstables. This can result in an sstable being split into a large number of new sstables. In this case the bloom filter of the new sstables could occupy too much memory and run the node out of memory. We now reduce the bloom filter size dynamically to avoid this. #9463
- When rewriting sstables (e.g. for the
nodetool upgradesstablescommand), ScyllaDB will now abort the rewrite if shutting down.
04 Aug 2022
Last Edit: 12 Aug 2022