The ScyllaDB Manager team is pleased to announce the release of ScyllaDB Manager 2.2, a production-ready version of ScyllaDB Manager for ScyllaDB Enterprise and ScyllaDB Open-Source customers. ScyllaDB Manager is a centralized cluster administration and recurrent tasks automation tool.
ScyllaDB Manager 2.2 brings improvements to ScyllaDB Repair performance and adds backup to Google Cloud Storage (GCP), as well as other improvements and bug fixes.
ScyllaDB Enterprise customers are encouraged to upgrade to ScyllaDB Manager 2.2 in coordination with the ScyllaDB support team.
The new release includes upgrades of both ScyllaDB Manager Server, Manager CLI tool (sctool) and ScyllaDB Manager Agent.
Useful Links:
- Download ScyllaDB Manager and ScyllaDB Manager Agent for ScyllaDB Enterprise customers
- Download ScyllaDB Manager and ScyllaDB Manager Agent for open source users (up to 5 nodes)
- ScyllaDB Manager Docker instance and example
- ScyllaDB Manager 2.2 documentation
- Upgrade from ScyllaDB Manager 2.0 to ScyllaDB Manager 2.2
- Submit a ticket for questions or issues with Manager 2.2 (ScyllaDB Enterprise users)
Repair Improvements
Small table optimization
ScyllaDB Manager breaks each table repair task to multiple small chunks. While this is useful for large tables, it proves to add redundant time when repairing small tables, for example system tables, resulting in a long repair time even for clusters with very little data.
In Manager 2.2, tables below configurable threshold (1GB by default) will be treated as small and repaired in a single repair command; this may affect production performance depending on the intensity of the operations.
Parallel repair
Manager 2.2 automatically breaks repair tasks to parallel tasks, running independently on distinct ranges of the token ring. Each node can take part in at most one repair at any given moment. Parallel repair can reduce the repair time in a factor of the number of nodes divided by the replication factor (RF). For example, a repair on a cluster of 12 nodes, Keyspace with RF=3 and default parallelism, can run up to x4 times faster, dependent on the online requests load.
User can control the level of parallelism using the new --parallel parameter.
- You can disable the parallel repair feature by setting the value to
1. - Default parallelism is zero; max parallelism value in the cluster based on the replication factor.
The following represents the saving in repair time in a 9 nodes cluster, all in the same data center, while serving requests in real time with 50% load.
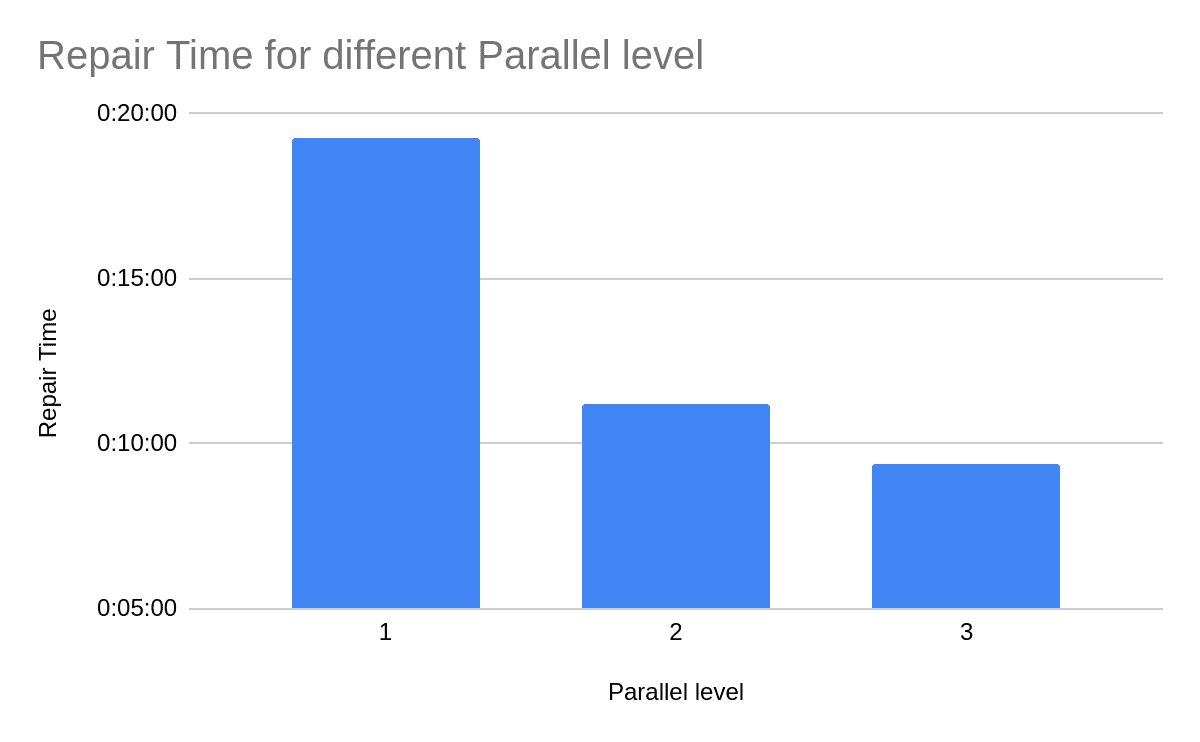
Refer to the ScyllaDB Manager documentation.
Control over parallelism and intensity during repair
A new command sctool repair control is added. It lets users change parallelism and intensity (added in 2.1) of an ongoing repair, without ever restarting the task. In addition to that commands sctool repair update and sctool backup update let you update task specification of existing tasks for future runs.
Note: starting with ScyllaDB Enterprise 2020.1 and ScyllaDB Open Source 3.1, ScyllaDB uses row level repair. This greatly improves repair performance, including ScyllaDB Manager users. As a side effect, the intensity flag while still supported, has a smaller effect on the repair time (see more in the documentation).
Backup to Google Cloud Storage (GCP)
Manager 2.2 now supports backup to GCP in a similar way to the existing AWS s3 support.
To enable, use the sctool backup command, for example
$ sctool backup --cluster prod-cluster --location gcs:manager-prod-backup --retention 7 --interval 1d
Where manager-prod-backup is the target bucket.
GCP back up default rate was tested to provide fast upload rate, with minimal impact on line requests.
Read the documentation here.
Healthcheck
ScyllaDB Manager now supports health check reports for ScyllaDB AWS DynamoDB compatible API (Alternator) .
A new (enabled by default) dynamic timeout parameter for each DC is based on measurements on RTT of recent probes. This fixes the issue of reporting remote DC nodes as not responsive due to longer latency values.
sctool updates
- Status
- Repair parameters
token-rangesandwith-hostare removed. - Backup parameter
forceis removed.
Port Updates
Monitoring ports used by ScyllaDB Manager and Manager Agent was overlapping with users’ existing applications. To fix this, we changed the default ports as follow:
ScyllaDB Manager Server:
- Default Prometheus port changes from 56090 → 5090
- Default HTTP API port changes from 56080 → 5080
- Default HTTPS API port changes from 56443 → 5443
- Default pprof debug port changes from 56112 → 5112
ScyllaDB Manager Agent:
- Default Prometheus port changes from 56090 → 5090
- Default pprof debug port changes from 56112 → 5112
For most users, the only ports used are the ones used by Prometheus (highlighted above). Please make sure to either:
- Update your Prometheus configuration to listen to the new port (already done in Monitoring 3.5)
- Update Manager and Manager configuration to keep using the old ports
For the first, make sure your firewall / security groups open the new monitoring port, and close the old one.
New OS support
- Added CentOS 8 support
Configuration
The following parameters has been removed from Manager configuration
- segments_per_repair
- shard_parallel_max
- shard_failed_segments_max
- error_backoff
Monitoring
You can use ScyllaDB Monitoring Stack 3.5 with -M 2.2 option to get Manager 2.2 dashboards.
02 Nov 2020